No Dicas de R de hoje, vamos mostrar como utilizar o pacote rdbnomics, que conecta o R à base de dados do DBNomics. O carro-chefe do pacote é a função rdb(), que permite acessar dados diretamente, tanto com calls para a API da base como para o ID das séries de interesse. Além disso, a função permite a aplicação de filtros - de agregação e interpolação - automaticamente, facilitando análises.
O ID de cada série está disponível logo abaixo de seu nome, dentro da página do provedor no site do DBNomics, entre chaves. Abaixo, mostraremos como exemplo como baixar os dados de taxa de desemprego da Argentina, Austrália e Áustria, com os dados do FMI.
library(rdbnomics)
arg <- rdb("IMF/WEO:2020-10/ARG.LUR.pcent_total_labor_force")
australia <- rdb("IMF/WEO:2020-10/AUS.LUR.pcent_total_labor_force")
austria <- rdb("IMF/WEO:2020-10/AUT.LUR.pcent_total_labor_force")
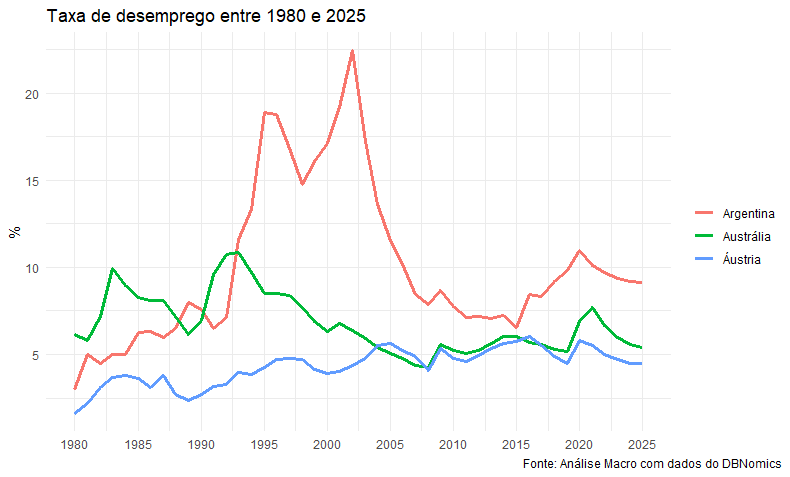
Com isso, temos 3 dataframes com as séries de interesse. Vamos então tratar os dados com tidyverse e visualizá-los com ggplot2. Como as séries são padronizadas pelo FMI, não precisamos nos preocupar com fazer matching das datas e inner joins, logo a transformação fica simplificada. Os dados vão de 1980 a 2025, logo a parte final é uma estimação para o futuro da trajetória de desemprego dos 3 países.
library(tidyverse) library(ggplot2) dados <- tibble(Argentina = arg$value, Austrália = australia$value, Áustria = austria$value, Ano = seq(1980, 2025, by = 1)) %>% pivot_longer(-Ano, values_to = "Valor", names_to = "Variável") dados %>% ggplot(aes(x=Ano, y = Valor, color = Variável))+geom_line(size = 1.1)+ labs(title = "Taxa de desemprego entre 1980 e 2025", y = "%", x = NULL, caption = "Fonte: Análise Macro com dados do DBNomics")+ scale_x_continuous(breaks = seq(1980, 2025, by = 5), labels = seq(1980, 2025, by = 5))+ theme_minimal()+ theme(legend.title = element_blank(), plot.caption.position = "plot")
_____________________


