No Dicas de R de hoje, vamos apresentar algumas funções que podem melhorar a qualidade dos seus gráficos em ggplot, utilizando para nossas visualizações usando o clássico mtcars. Um gráfico comumente utilizado para a exploração de uma base é o seu histograma, como a seguir:
library(ggplot2) library(tidyverse) dados <- mtcars dados %>% ggplot(aes(x=factor(cyl), y = mpg))+ geom_boxplot()+ labs(y='Milhas por Galão', x = 'Número de cilindros')+ theme_bw()

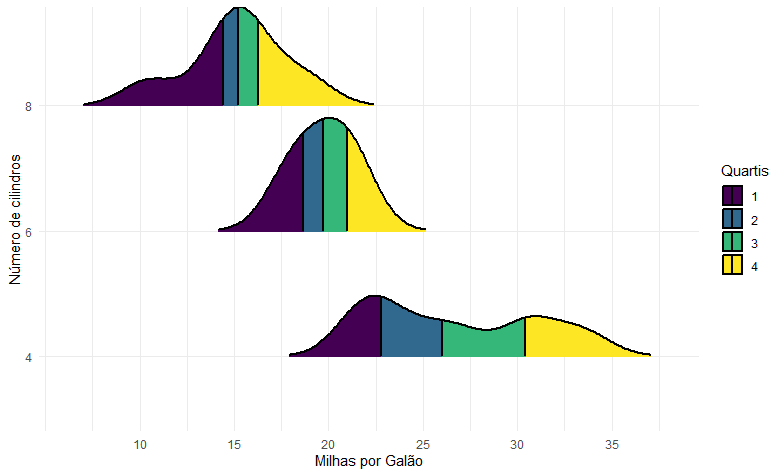
Porém, podemos utilizar uma alternativa que facilita a visualização da distribuição estimada dos valores, chamada de Kernel Density Estimation. Ela é parente do histograma, e permite uma visualização mais suavizada dos dados. Ademais, com o pacote ggridges, podemos fazer uma visualização semelhante à acima, exibindo os quartis estimados:
library(ggridges) dados %>% ggplot(aes(x=mpg, y = factor(cyl), fill = factor(stat(quantile))))+ labs(x='Milhas por Galão', y = 'Número de cilindros')+ scale_x_continuous(breaks = seq(10, 35, by = 5))+ stat_density_ridges(geom = "density_ridges_gradient", quantile_lines = TRUE, alpha = 1, rel_min_height = 0.01, scale = 0.9, size = 1)+ scale_fill_viridis_d(name = "Quartis")+ theme_minimal()
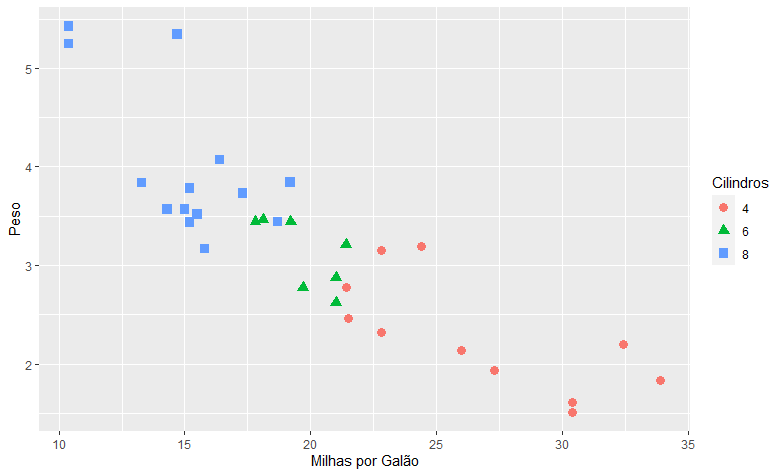
Agora, vamos adicionar à análise o peso dos carros. Para isso, o modo mais simples de visualizarmos os dados é o gráfico de dispersão:
dados %>% ggplot(aes(x=mpg, y=wt, color=factor(cyl), shape = factor(cyl)))+ geom_point(size = 3) + labs(x='Milhas por Galão', y = 'Peso', color='Cilindros', shape='Cilindros')
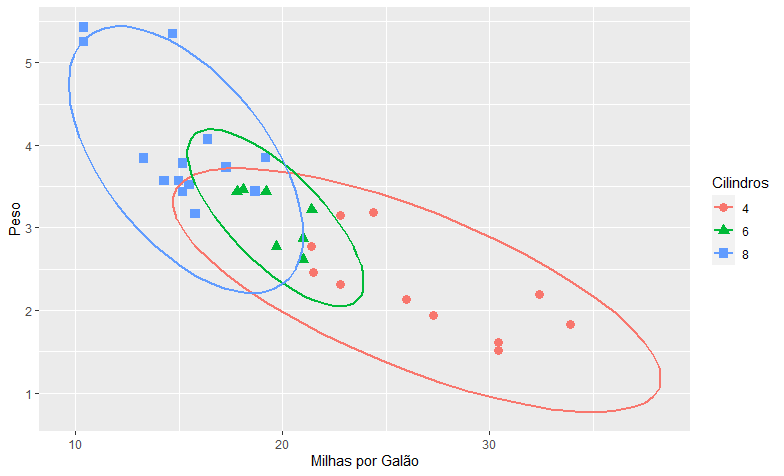
A visualização é facilitada pela inclusão de tanto cores como formatos para cada tipo de variável, permitindo distinguir os pontos que estabelecem a relação descrita. Como podemos ver, a correlação negativa entre as variáveis é fortemente ditada pelos grupos que se definem pelo número de cilindros. Podemos facilitar a visualização da posição dos grupos adicionando elipses em torno de cada um:
dados %>% ggplot(aes(x=mpg, y=wt, color=factor(cyl), shape = factor(cyl)))+ geom_point(size = 3) + labs(x='Milhas por Galão', y = 'Peso', color='Cilindros', shape='Cilindros')+ stat_ellipse(size=1.05)