No Hackeando o R de hoje, vamos mostrar como fazer a análise de fatores no R. A ideia por trás dessa metodologia é tentar identificar a relações não-observáveis em amostras de variáveis observáveis (como uma correlação). Esse método é comum em psicometria, logo para o exemplo utilizaremos o pacote psych, que possui ferramentas específicas para isso. Também utilizaremos o pacote GPArotation, que é útil para a análise de fatores. Diferentemente do PCA, onde é pressuposto que toda a variância é comum entre as variáveis, aqui supomos que há alguma variância em cada observação que é única a ela, através de fatores que são específicos, ou erros. Com isso, vamos fazer um exemplo usando o dataset attitude, que já vem no R base.
Primeiramente, vamos carregar os pacotes que iremos utilizar:
library(psych) library(GPArotation)
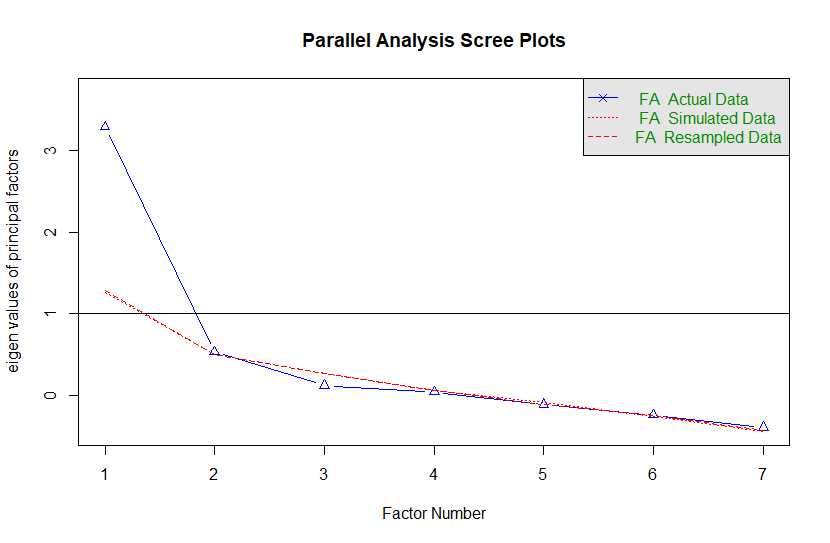
Para criarmos uma análise simples, podemos iniciar identificando o possível número de fatores que explicam a variação comum das observações, utilizando um gráfico scree. Sua interpretação é parecida com a do PCA: estamos buscando uma dobra brusca no gráfico (como um cotovelo), indicando que a passagem de n fatores para n+1 traz pouca informação nova. Isso pode ser feito com a função fa.parallel, que gera o gráfico e algumas informações adicionais. Como podemos ver abaixo, utilizar 2 fatores parece adequado.
fa.parallel(attitude, fm = "ml", fa = "fa")
Com isso, podemos rodar o modelo (cujos detalhes serão omitidos por hoje) usando a função fa(). Dois argumentos merecem atenção: o rotate = "oblimin" indica que permitimos que os fatores possuam correlação, enquanto que fm = "ml" faz a estimação através de máxima verossimilhança.
attitude_fa <- fa(attitude, nfactors = 2, rotate = "oblimin", fm = "ml") attitude_fa fa.diagram(attitude_fa, simple = FALSE)
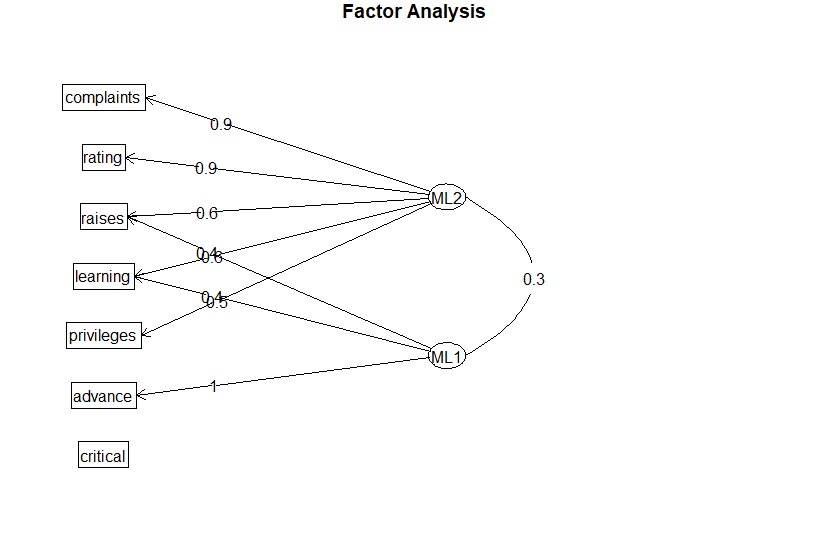
O diagrama gerado pela fa.diagram() mostra que os dois fatores gerados possuem correlação com características observáveis distintas. O ML1 é correlacionado com learning, raises e advance, o que pode ser interpretado como as oportunidades de carreira para funcionários da empresa. O ML2 tem correlação com todas as variáveis exceto advance e critical, o que pode ser visto como o bem-estar geral dos funcionários. É importante notar que essa é apenas uma interpretação: o objetivo da análise é justamente identificar fatores que explicam variações comuns, e tentar descrevê-los de uma forma causal.
________________________
(*) Para entender mais sobre análises estatísticas, confira nosso Curso de Estatística usando R e Python.

