No Hackeando o R de hoje, vamos mostrar como fazer a visualização do carry-over estatístico de uma série temporal. Essa estatística pode ser uma importante ferramenta para a análise de agregações de dados ao longo do tempo pois facilita identificar a variação que ocorreu apenas no período corrente, extraindo a variação que é apenas resíduo do período anterior, chamada de carry-over. Abaixo, visualizamos os dois efeitos teóricos com uma simulação de dados
library(RcppRoll) library(ggplot2) set.seed(1) x = data.frame(valor = (1:100) + rnorm(100), t = 1:100) ggplot(x[49:72,], aes(x = t, y = valor))+geom_bar(stat = 'identity') + coord_cartesian(ylim = c(45, 73))+ geom_segment(aes(x=49, xend=60, y = 54.68361, yend=54.68361), size = 1.2)+ geom_label(aes(x=49, y=54.68361, label = 'A'))+ geom_segment(aes(x=61, xend=72, y = 59.86495, yend=59.86495), size = 1.2)+ geom_label(aes(x=61, y=59.86495, label = 'B'))+ geom_segment(aes(x=61, xend=72, y = 66.85647, yend=66.85647), size = 1.2)+ geom_label(aes(x=61, y=66.85647, label = 'C'))+ labs(x='', y = '')+ theme_bw()

No exemplo acima, A é a média do ano anterior, C a média do ano corrente, e B é o valor da última observação do ano anterior, repetido para o ano corrente, ou seja, a média do ano corrente caso não houvesse crescimento. Ao compararmos a variação interanual dos dois períodos, podemos decompor esse valor em duas partes: a variação percentual de A a B, chamada de carry-over, e a variação percentual de B a C (mensurada no nível de A), que é o crescimento que ocorreu apenas a partir da última observação do ano anterior. A função abaixo calcula tais valores para uma variável mensal qualquer:
calcula_carry_over_anual <- function(data) {
A <- dplyr::lag(RcppRoll::roll_meanr(data, n=12), n=12)
B <- dplyr::lag(data, n = 12)
C <- RcppRoll::roll_meanr(data, n=12)
carry_over <- (B-A)/A
cresc_real_do_periodo <- (C-B)/A
lista = data.frame(carry_over, cresc_real_do_periodo, carry_over+cresc_real_do_periodo)
return(lista)
}
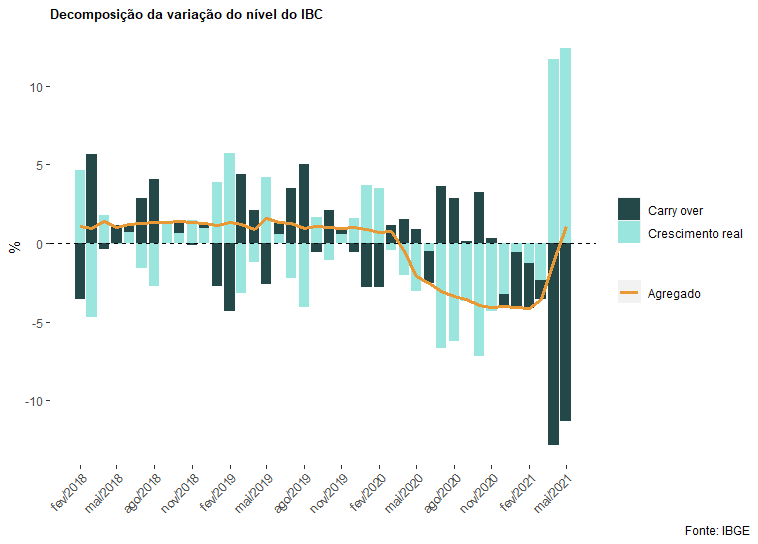
Então, vamos fazer a decomposição da série de nível do IBC como exemplo:
library(BETS)
library(tidyverse)
library(ggplot2)
library(scales)
ibc = BETSget(24363, data.frame=TRUE)
tibble(ibc$date, calcula_carry_over_anual((ibc$value))*100) %>%
magrittr::set_colnames(c('date', 'carry_over', 'cresc_real', 'soma')) %>%
pivot_longer(-date, names_to = 'var', values_to = 'val') %>%
filter(date>as.Date('2018-01-01') & var != 'soma') %>%
mutate(idk = RcppRoll::roll_sumr(val, n=2),
idk = ifelse(rep(c(FALSE, TRUE), times = 39), idk, NA)) %>%
ggplot(aes(x=date, y = val, fill = var))+geom_bar(stat = 'identity')+
scale_x_date(breaks = date_breaks('3 months'),
labels = date_format("%b/%Y"))+
scale_fill_manual(labels = c('Carry over', 'Crescimento real'), values = c('#244747', '#9ae5de'))+
geom_line(aes(x=date,y=idk, color = 'Agregado'), size= 1.2, linetype='solid')+
scale_color_manual(values = c('Agregado' = '#e89835'))+
geom_hline(yintercept=0, colour='black', linetype='dashed')+
labs(title='Decomposição da variação do nível do IBC', y = '%',
caption='Fonte: IBGE')+
theme(panel.background = element_rect(colour = 'white', fill='white'),
legend.position = 'right',
strip.text = element_text(size=8, face='bold'),
axis.text.x = element_text(angle = 45, hjust=1),
plot.title = element_text(size=10, face='bold'),
legend.title = element_blank(),
plot.caption.position = 'plot',
axis.title.x = element_blank())

________________________
(*) Para entender mais sobre séries temporais e como realizar cálculos estatísticos, confira nosso Curso de Análise de Séries Temporais.

