No Hackeando o R de hoje, vamos mostrar como fazer a visualização do impacto das variáveis de um modelo linear com o pacote Effects. Esse tipo de visualização é interessante para facilitar a comunicação de resultados estatísticos, garantindo a interpretação correta de seus modelos. Vamos iniciar nosso exemplo gerando um modelo linear usual:
library(car)
Prestige$type = factor(Prestige$type, levels=c("bc", "wc", "prof"))
lm1 = lm(prestige ~ education + poly(women, 2) +
log(income)*type, data=Prestige)
summary(lm1)
lm(formula = prestige ~ education + poly(women, 2) + log(income) *
type, data = Prestige)
Residuals:
Min 1Q Median 3Q Max
-12.1070 -3.8277 0.2736 3.8382 16.4393
Coefficients:
Estimate Std. Error t value Pr(> |t|)
(Intercept) -137.5002 23.5219 -5.846 8.18e-08 ***
education 2.9588 0.5817 5.087 2.01e-06 ***
poly(women, 2)1 28.3395 10.1900 2.781 0.00661 **
poly(women, 2)2 12.5663 7.0954 1.771 0.07998 .
log(income) 17.5135 2.9159 6.006 4.06e-08 ***
typewc 0.9695 39.4947 0.025 0.98047
typeprof 74.2759 30.7357 2.417 0.01771 *
log(income):typewc -0.4661 4.6200 -0.101 0.91986
log(income):typeprof -7.6977 3.4512 -2.230 0.02823 *
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 6.199 on 89 degrees of freedom
(4 observations deleted due to missingness)
Multiple R-squared: 0.8793, Adjusted R-squared: 0.8685
F-statistic: 81.08 on 8 and 89 DF, p-value: < 2.2e-16
Dentre os regressores do modelo, apenas education possui uma interpretação direta, de que uma unidade adicional aumenta o valor de prestige em 2.95. Para as outras variáveis, temos efeitos que variam de magnitude, como no caso de women, e transformações de escala misturadas com interações, fazendo com que a compreensão do modelo não seja muito intuitiva. Para resolver isso, vamos utilizar a função plot() do pacote effects, que permite visualizar o efeito de uma das variáveis. Abaixo, o efeito de education:
library(effects)
e1.lm1 = predictorEffect("education", lm1)
plot(e1.lm1)
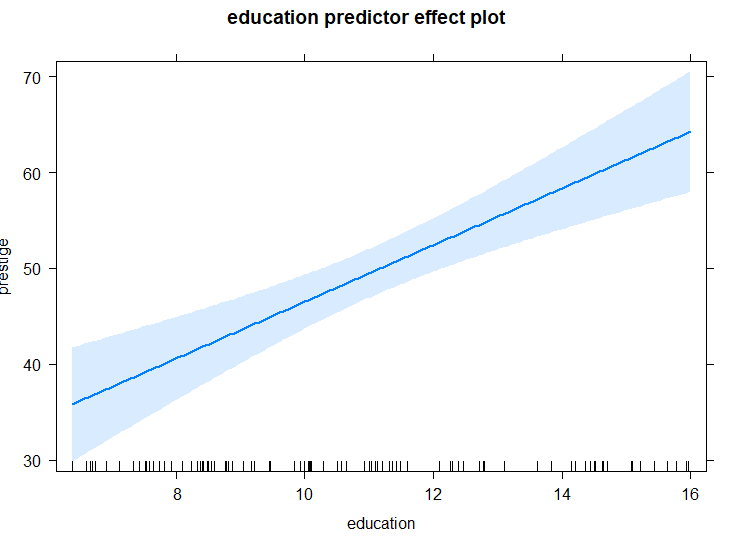
O gráfico gerado apresenta uma reta cuja angulação é o coeficiente do regressor no modelo, e o valor da função de efeito é prestige em função de education, com os outros regressores fixos em valores padrões, como a média deles, sendo assim o efeito parcial de education. A banda desenhada é o intervalo de confiança para a estimação desse valor, se baseando na matriz de covariâncias dos regressores da amostra. Para um parâmetro simples, não há grandes ganhos sobre a interpretação, porém no caso da variável income, que entra no modelo em logaritmo e tem interação com dummies, o efeito é mais complicado, e o gráfico se torna mais interessante:
plot(predictorEffect("income", lm1),
lines=list(multiline=TRUE))
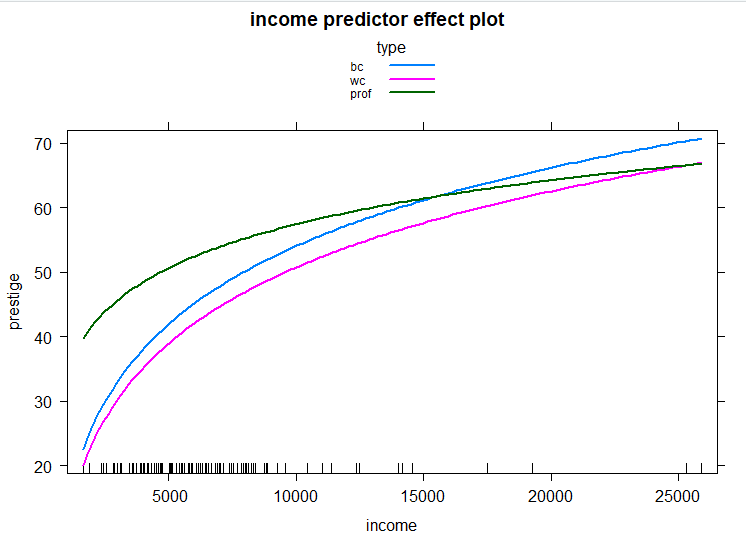
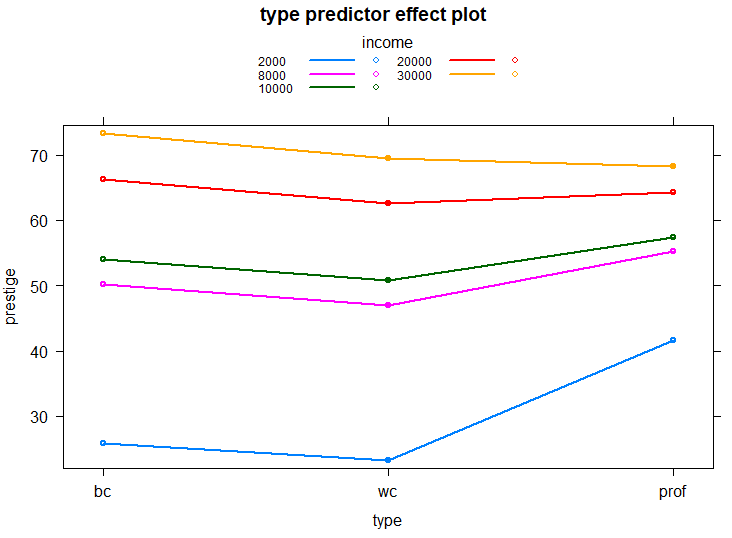
No caso da própria variável type, que é categórica, o efeito depende da categoria, e do valor de income. Para entendermos como funciona o modelo em níveis distintos de income, são gerados pontos para os 5 principais quantis:
plot(predictorEffect("type", lm1, xlevels = 5), lines=list(multiline=TRUE))
________________________
(*) Para entender mais sobre modelagem e estatística, confira nossos Cursos de Econometria e Machine Learning.

