No Hackeando o R de hoje, vamos mostrar como fazer a visualização de dados distribuídos em uma malha (como um mapa) dentro do R. Para isso, iremos introduzir funcionalidades básicas do pacote terra, e conectar seus resultados ao ggplot2 usando o pacote rasterVis.
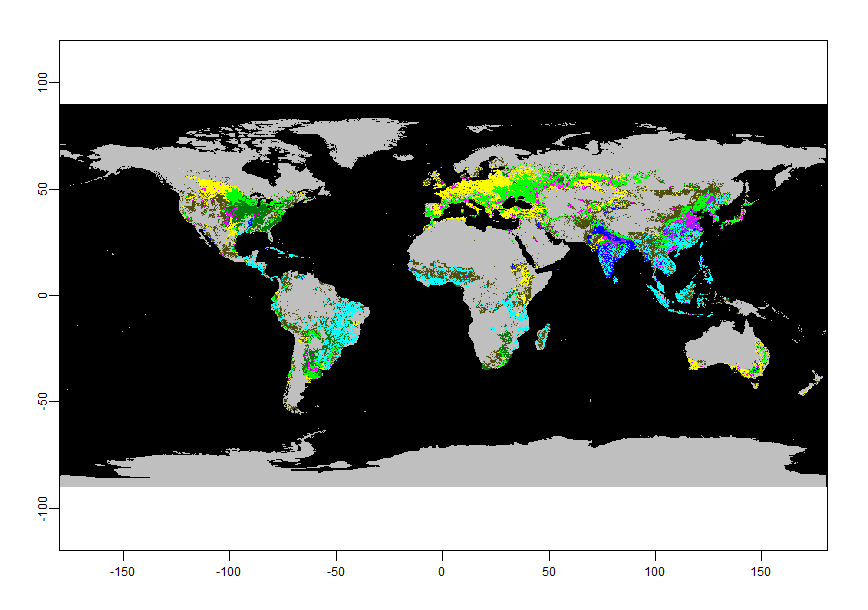
Iremos utilizar duas fontes de dados para o exercício: o mapa de UFs do Brasil disponível no NEREUS, e a imagem de distribuição da agricultura ao redor do mundo em 2010, classificada por principais produtos e a predominância de irrigação/chuvas como fonte de água. Tais dados são de classes diferentes: o mapa, que está em formato shapefile (.shp), é uma coleção de vetores que descreve características do mundo real, como no caso a divisão entre os estados; por outro lado, a imagem é uma malha de pixels que percorre o mundo inteiro, e possui uma codificação para cada pixel, indicando qual seria o atributo em cada posição do mapa global. Os dados em malha são chamados de rasterizados, e no nosso caso estão disponíveis em um arquivo TIFF (.tif).
Para abrirmos esses dados, vamos carregá-los com o terra. Para abrir dados vetorizados, utilizamos a função vect(), enquanto que dados rasterizados utilizam a função rast. Abaixo, abrimos cada um e plotamos seus resultados:
library(terra)
munip = vect('estados/UFEBRASIL.shp')
irrig = rast('dados_irrigacao_GFSAD1KCD.tif')
plot(munip)

plot(irrig)
Agora, digamos que queremos apenas analisar os dados do Brasil. Para fazer isso, podemos utilizar a função mask(), que sobrepõe a imagem no mapa de vetores, e transforma em NA todos os dados que estão fora do mapa. Note que dentro da mask utilizamos crop(); essa função recorta a imagem original, para que a imagem final tenha extensões do mapa de vetores.
recorte = mask(crop(irrig, munip), munip)
Feito isso, podemos então visualizar diretamente os dados brasileiros. Queremos trabalhar com o ggplot2 devido a seu grande número de funcionalidades, porém ele não recebe objetos do tipo SpatRaster. Então, utilizamos a função gplot() do pacote rasterVis, que interage com esses objetos e recebe argumentos do ggplot. Abaixo, visualizamos o gráfico final:
library(rasterVis)
library(ggplot2)
library(stringr)
gplot(recorte, maxpixels = 1000000) + geom_tile(aes(fill = factor(value)))+
ggtitle("Distribuição da produção agrícola em relação ao uso de irrigação em 2010",
subtitle = 'Dados classificados por principais produtos e oferta de água') +
scale_fill_manual(values = c('#414952', '#c42f0e', '#ff773d',
'#de9f00', '#3dccff', '#0495c9',
'#4824ff', '#140078', '#00ba63',
'#bdbdbd'),
labels = lapply(c('Dados não identificados',
'Irrigação: Arroz e trigo',
'Irrigação: Trigo, arroz, cevada e soja',
'Irrigação: Trigo, milho, arroz, algodão e pomares',
'Chuva: Trigo, arroz, soja, cana-de-açúcar, milho e mandioca',
'Chuva: Trigo e cevada',
'Chuva: Milho e soja',
'Chuva: Trigo, milho, arroz, cevada, soja',
'Plantação em pequena quantidade',
'Sem dados',
''), str_wrap, 30)) +
theme_minimal() +
theme(legend.title = element_blank(),
panel.grid = element_blank(),
axis.text = element_blank(),
axis.title = element_blank(),
legend.key.height=unit(1, "cm"))
 _____________________
_____________________


