O Prophet é um modelo produzido pelo Facebook, com o objetivo de prever dados diários com sazonalidade semanal e anual, mais efeitos de feriados. No post de hoje, utilizaremos o modelo no R aplicando um exemplo com os dados de demanda de energia elétrica no Brasil.
O modelo Prophet é um modelo de séries temporais que leva em consideração diversos componentes. Em geral, é considerado um modelo de regressão não linear na seguinte forma:

Onde g(t) descreve o termo de crescimento (a tendência linear) , s(t) descreve os vários padrões sazonais, h(t) captura os efeitos de feriados e  é o termo de erro em forma de ruído branco.
é o termo de erro em forma de ruído branco.
Podemos ilustrar o uso do modelo Prophet no R utilizando o pacote {fable.prophet}, que faz parte da família de pacotes de séries temporais, tidyverts, no uso de dados da Curva de demanda de energia por hora disponibilizada pela ONS. Os dados referem-se ao ano de 2022.
Abaixo, carregamos os pacotes.
library(tidyverse) library(fable.prophet) library(fable) library(tsibbledata) library(feasts)
Para obter o código de importação do dataset, da construção dos gráficos e também dos códigos subsequentes, faça parte do Clube AM, o repositório especial da Análise Macro.
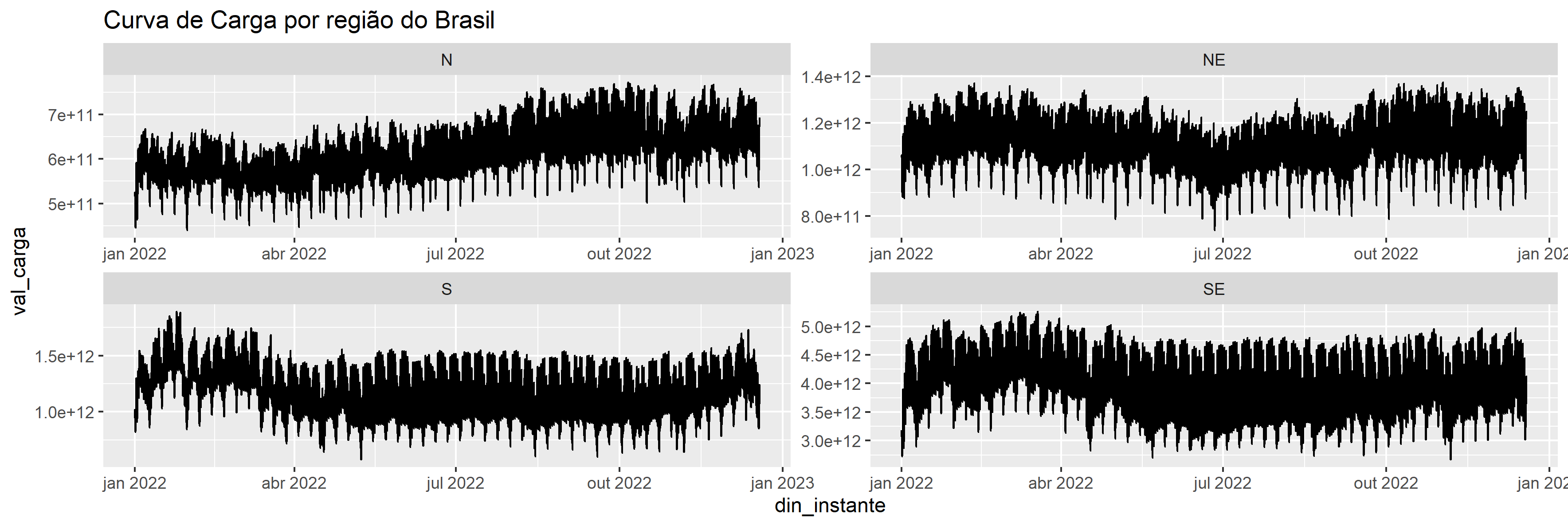
Vamos olhar os dados da Curva para cada região. Vemos que há um padrão de várias sazonalidades nas curvas. Podemos entender que há a possibilidade usa-las no modelo Prophet.
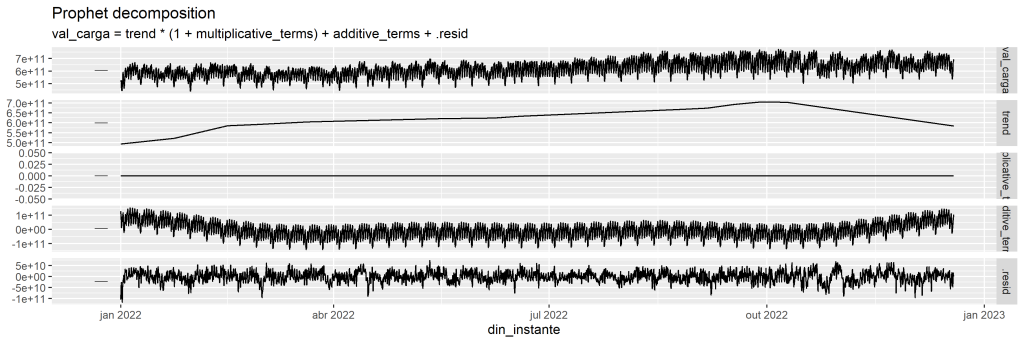
Aplicando o modelo, o resultado será a decomposição das séries. Vemos abaixo o resultado para a região Norte.
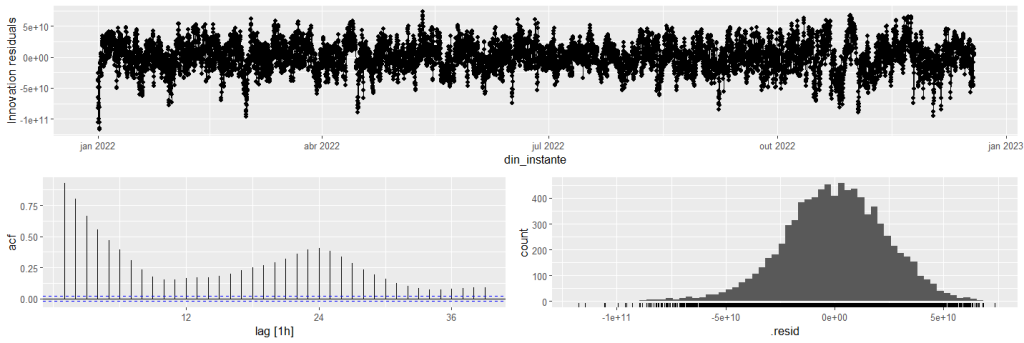
Em ordem para verificar se o modelo produziu estimativas corretas, verificamos os termos de erros para confirmar se são de fato ruído branco.
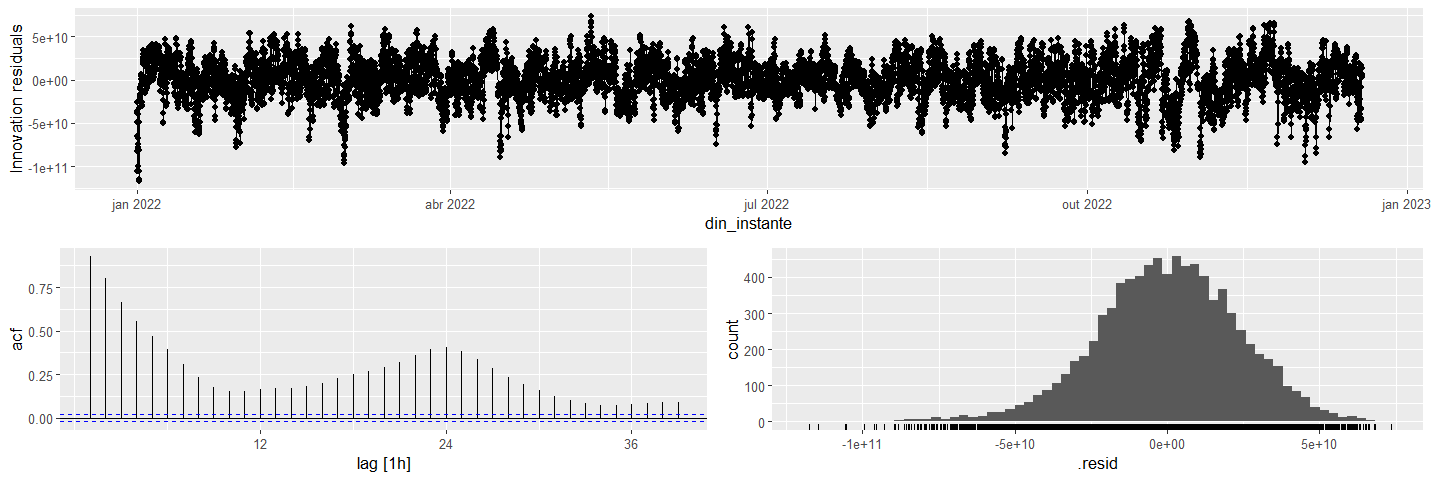
O gráfico sugere que há autocorrelação nos termos de erros, o que implica que não é ruído branco, bem como podemos adicionar mais variáveis para explicar o uso de energia elétrica (tal como o efeito de feriados e a temperatura).
________________________________________________
Quer se aprofundar no assunto?
Alunos da trilha de Ciência de dados para Economia e Finanças podem aprender a como construir projetos que envolvem dados reais usando modelos econométricos e de Machine Learning com o R.
Referências
Hyndman, R.J., & Athanasopoulos, G. (2021) Forecasting: principles and practice, 3rd edition, OTexts: Melbourne, Australia. OTexts.com/fpp3.

