No post anterior, eu mostrei como é possível coletar os preços de ações com o R através do pacote quantmod, utilizando a base de dados do Yahoo Finance. Essa representação dos dados, contudo, não é a mais conveniente para a gestão de portfólios, como veremos no nosso Novo Curso Mercado Financeiro e Gestão de Portfólios. Para fins de construção de portfólios, é conveniente usarmos os retornos ou log-retornos dos ativos. De fato, uma grande parte dos estudos financeiros envolve retorno, ao invés de preço, de ativos. Isto porque, retorno de ativos pode ser um completo sumário para oportunidades de investimento, bem como séries de retorno são mais fáceis de lidar do que séries de preço porque aquelas possuem propriedades estatísticas mais atrativas.
Há, entretanto, diversas definições de retorno de ativos. Tomando  como o preço de um ativo no tempo
como o preço de um ativo no tempo  , considerando que a princípio o ativo não paga dividendos, ao manter um ativo por um período de
, considerando que a princípio o ativo não paga dividendos, ao manter um ativo por um período de  a , isso resultaria em um retorno bruto simples de
a , isso resultaria em um retorno bruto simples de
(1) 
O retorno líquido ou simples então será de
(2) 
Já o logaritmo natural do retorno bruto simples de um ativo é chamado de retorno composto continuamente ou simplesmente log-retorno:
(3) 
onde  . A seguir, pegamos nossas ações coletadas no post anterior e calculamos os log-retornos mensais com o pacote tidyquant.
. A seguir, pegamos nossas ações coletadas no post anterior e calculamos os log-retornos mensais com o pacote tidyquant.
library(tidyverse) library(tidyquant) library(timetk) library(scales) library(quantmod) prices = getSymbols(symbols, src='yahoo', from='2019-01-01', to='2020-04-20', warning=FALSE) %>% map(~Cl(get(.))) %>% reduce(merge) %>% `colnames<-` (symbols) %>% tk_tbl(preserve_index = TRUE, rename_index = 'date') %>% drop_na() returns = prices %>% gather(asset, prices, -date) %>% group_by(asset) %>% tq_transmute(mutate_fun = periodReturn, period='monthly', type='log') %>% spread(asset, monthly.returns) %>% select(date, symbols)
A seguir, construímos um gráfico desses retornos.
ggplot(returns, aes(x=date))+
geom_line(aes(y=PETR4.SA, colour='PETR4'))+
geom_line(aes(y=ABEV3.SA, colour='ABEV3'))+
geom_line(aes(y=MGLU3.SA, colour='MGLU3'))+
geom_line(aes(y=VVAR3.SA, colour='VVAR3'))+
scale_colour_manual('',
values=c('PETR4'='blue',
'ABEV3'='red',
'MGLU3'='orange',
'VVAR3'='green'))+
scale_x_date(breaks = date_breaks("1 month"),
labels = date_format("%b/%Y"))+
theme(axis.text.x=element_text(angle=45, hjust=1),
legend.position = 'bottom',
plot.title = element_text(size=10, face='bold'))+
labs(x='', y='',
title='Log-Retornos mensais de ações brasileiras selecionadas',
caption='Fonte: analisemacro.com.br com dados do Yahoo Finance')
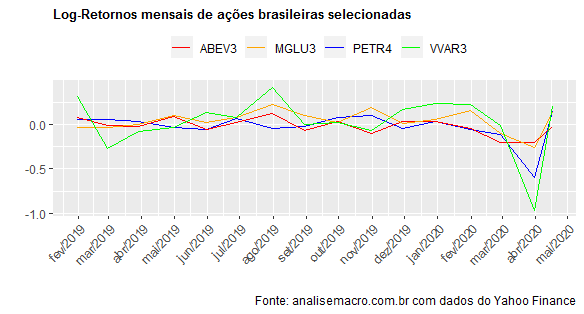
Observa-se uma queda forte no mês de março por conta da pandemia do coronavírus, como era esperado.
(*) Isso e muito mais você irá aprender no nosso Novo Curso Mercado Financeiro e Gestão de Portfólios.

