Arquivos de PDF são muito utilizados para compartilhar relatórios de análise, informações e dados diversos. Muitas vezes precisamos dos dados ali disponibilizados, tal como uma tabela. Então surge a pergunta: como extrair as informações com precisão e agilidade?
Neste artigo vamos mostrar um exemplo simples de extração de dados tabulares a partir de um arquivo PDF proveniente do site do Banco Central do Brasil. Utilizamos Inteligência Artificial para facilitar, simplificar e agilizar o processo, além do Python para possibilitar a automação.
Passo 01: abrir o Google Colab
Primeiro, abrimos o ambiente online Google Colab para usar o Python no procedimento. Basta ter uma conta de cadastro para usar e acessar o endereço https://colab.new/.
Passo 02: bibliotecas de Python
Em seguida, vamos importar as bibliotecas da linguagem Python com funções prontas que facilitam todo o processo, através do seguinte código:
Para obter o código e o tutorial deste exercício faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
Passo 03: arquivo PDF de exemplo
Neste exemplo vamos utilizar o arquivo PDF chamado “Atualização dos modelos semiestruturais de pequeno porte”, publicado no site do Banco Central do Brasil através deste link.

Escrevemos o seguinte código para baixar online o arquivo PDF acima, através do link, diretamente para o Google Colab:
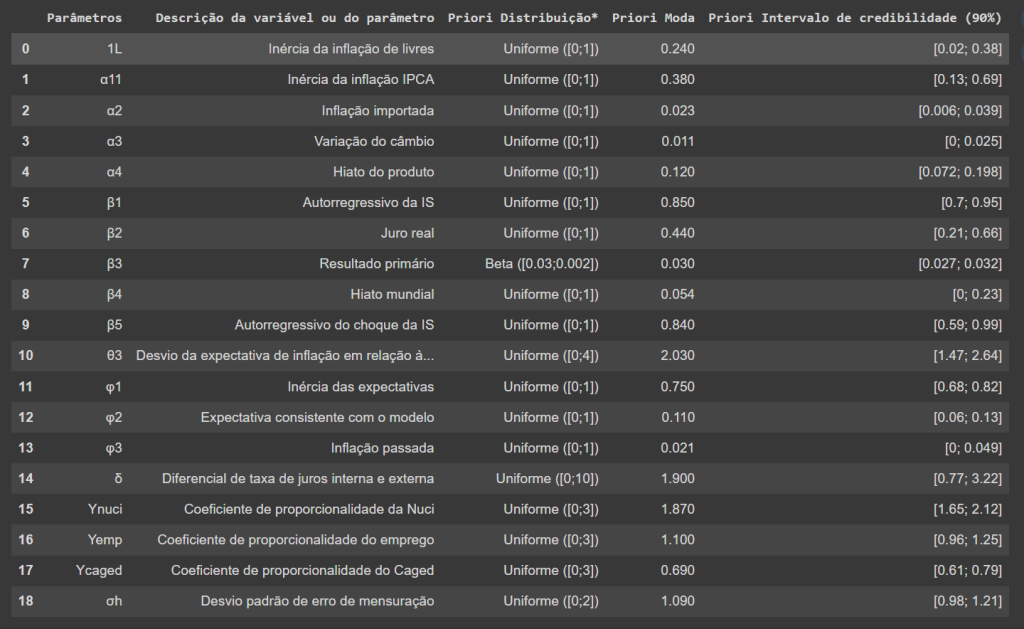
A informação que queremos extrair nesse exemplo é a “Tabela 1” do PDF:

Passo 04: instrução para modelo de IA
Agora, vamos escrever uma instrução (prompt) para um modelo de Inteligência Artificial, chamado Google Gemini, ler o arquivo PDF baixado e extrair a tabela de interesse. Para isso funcionar é necessário configurar a chave de API e, então, enviar a instrução com o arquivo PDF para o modelo processar.
Passo 05: converter resposta em tabela Pandas
Por fim, convertemos a resposta textual do modelo de IA generativa para um tabela do Pandas (DataFrame), assim fica mais fácil trabalhar na sequência com os dados.
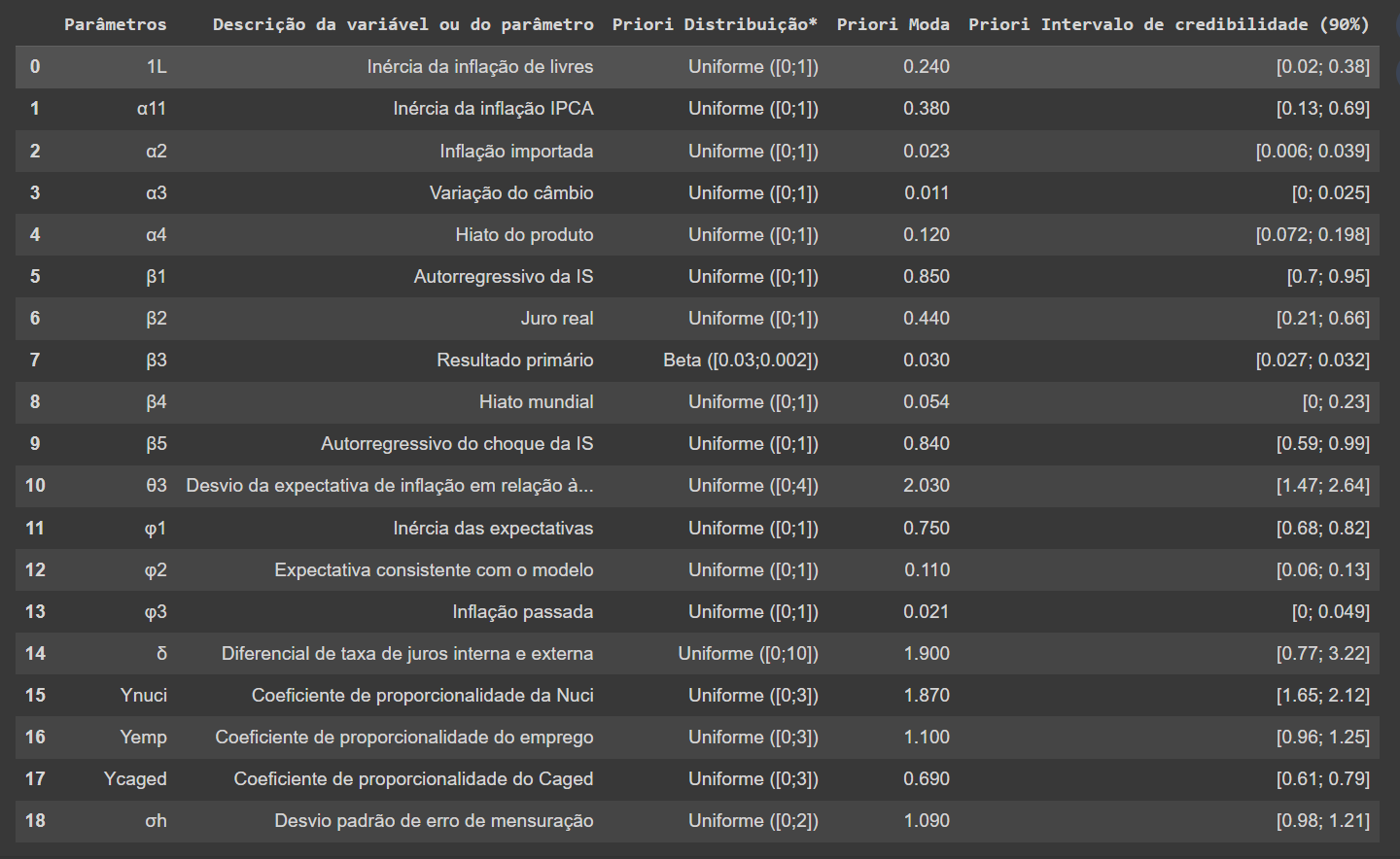
O resultado final é este:
Conclusão
Apesar de serem muito utilizados para compartilhar informações, os arquivos PDFs podem ser um empecilho para extrair dados. Neste artigo mostramos como usar IA para superar este desafio facilmente através do Python.
Quer aprender mais?
Clique aqui para fazer seu cadastro no Boletim AM e baixar o código que produziu este exercício, além de receber novos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas diretamente em seu e-mail.

