Quando trabalhamos em uma equipe, nem sempre podemos contar que todos usem as mesmas ferramentas. No ramo de dados isso pode ser um complicador importante, dado a necessidade de padrões que possam ser utilizado por diversos meios. Assim, quem está acostumado a utilizar R para análises deve estar habituado com o padrão tidy, que segue três regras principais: 1) Cada variável é uma coluna; 2) Cada observação é uma linha e 3) Cada célula tem apenas uma medida. No entanto, quando esse padrão não é seguido, pode ser difícil seguir com o trabalho. Frequentemente, as pessoas utilizam o Excel para criar análises, gerando planilhas muito elaboradas, mas que se tornam impossíveis de serem importadas por qualquer outra ferramenta.
Os pacotes tidyxl e unpivotr cobrem essa dificuldade, facilitando an importação de planilhas mal estruturadas no R. O primeiro serve para ler a planilha de excel de maneira diferente do usual, célula por célula. O segundo serve para estruturar essa informação em uma tabela em formato tidy.
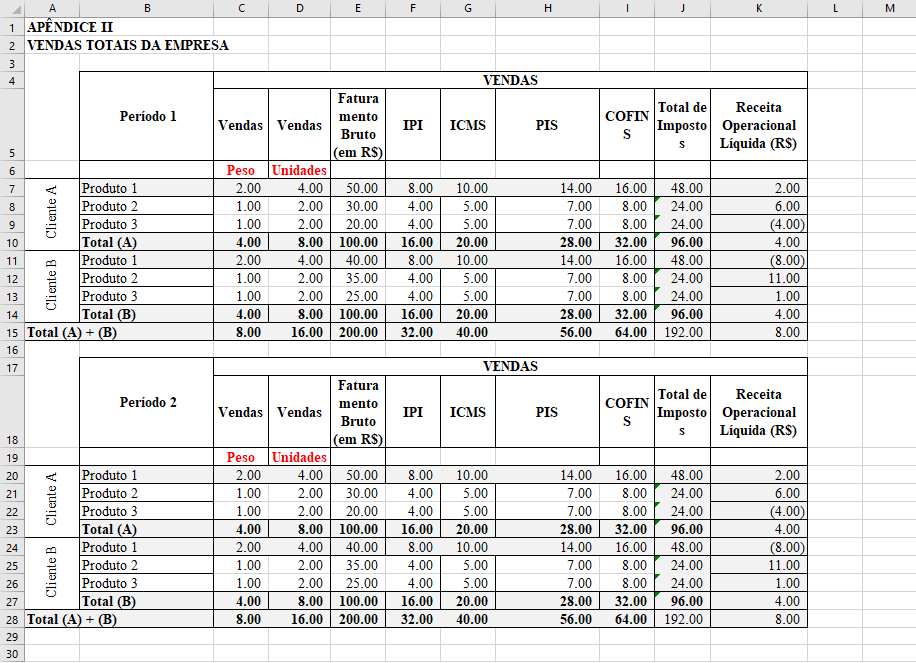
Utilizaremos um exemplo simples para mostrar as funcionalidades destes pacotes. Veja que a mesma planilha traz diversas informações financeiras para três produtos, dois clientes e dois períodos, que são arranjados em duas tabelas diferentes.
library(tidyverse) library(readxl) library(tidyxl) library(unpivotr) library(knitr)
Veja que se tentarmos ler o arquivo pelo modo tradicional, pelo pacote readxl, não há possibilidade nenhuma de prosseguirmos.
kable(readxl::read_xlsx("exemplo.xlsx")[1:5,1:5])
| APÊNDICE II | ...2 | ...3 | ...4 | ...5 |
|---|---|---|---|---|
| VENDAS TOTAIS DA EMPRESA | NA | NA | NA | NA |
| NA | NA | NA | NA | NA |
| NA | Período 1 | VENDAS | NA | NA |
| NA | NA | Vendas | Vendas | Faturamento Bruto |
| NA | NA | Peso | Unidades | NA |
Agora importando pelo pacote tidyxl
cells = xlsx_cells("exemplo.xlsx")
A partir daqui a funções utilizadas dependem muito da estrutura da planilha. No caso estamos filtrando todas as células em branco. Além disso, estamos retirando as linhas iniciais e as linhas apenas com os nomes das colunas na segunda tabela. Isso vai ser útil para trabalharmos apenas com uma tabela.
extracted <- cells %>% filter(!is_blank, row > 4 & !(row %in% c(16,17,18,19))) %>% select(row, col, data_type, numeric, character)
Agora utilizaremos o comando "behead" do unpivotr para extraírmos as colunas. O comando é dividido em duas partes. Na primeira dizemos a direção em que está o título da coluna/linha e na segundo o nome que daremos a esta coluna. Na primeira a direção é para cima ("up"), pois é onde está a linha com os nomes das colunas (Vendas, Faturamento, etc.). Na segunda vamos de novo para cima, para selecionar a linha que diferencia as duas colunas de vendas, entre peso e unidade. Na terceira, a direção é esquerda-baixo ("left-down"). Esse é um caso importante, pois estamos tratando de células mescladas. Neste caso, os títulos estão à esquerda e abaixo os valores que ela descreve. Por último, criamos a coluna de produtos, também à esquerda.
Além disso, criamos uma coluna com o período. Se a linha for menor ou igual a 15, as informações são sobre o período 1, caso contrário, do período 2. Também juntamos a coluna de variável com a de unidade, para os casos das variáveis de vendas, onde há a separação. Perceba que agora temos uma tabela "tidy".
tidied <- extracted %>%
behead("up", "variable") %>%
behead("up", "tipo") %>%
behead("left-down", "cliente") %>%
behead("left", "produto") %>%
mutate(periodo = ifelse(row <= 15, 1,2),
variable = ifelse(is.na(tipo), variable, paste0(variable,"_",tipo))) %>%
select(variable, cliente, periodo, produto, numeric) %>%
drop_na(cliente)
kable(head(tidied,10))
| variable | cliente | periodo | produto | numeric |
|---|---|---|---|---|
| Vendas_Peso | Cliente A | 1 | Produto 1 | 2 |
| Vendas_Unidades | Cliente A | 1 | Produto 1 | 4 |
| Faturamento Bruto (em R$) | Cliente A | 1 | Produto 1 | 50 |
| IPI | Cliente A | 1 | Produto 1 | 8 |
| ICMS | Cliente A | 1 | Produto 1 | 10 |
| PIS | Cliente A | 1 | Produto 1 | 14 |
| COFINS | Cliente A | 1 | Produto 1 | 16 |
| Total de Impostos | Cliente A | 1 | Produto 1 | 48 |
| Receita Operacional Líquida (R$) | Cliente A | 1 | Produto 1 | 2 |
| Vendas_Peso | Cliente B | 1 | Produto 2 | 1 |
Para torna-la no formato semelhante ao da tabela inicial, basta utilizarmos a função pivot_wider do tidyr.
kable(tidied %>% pivot_wider(names_from = variable, values_from = numeric) %>% select(1:6))
| cliente | periodo | produto | Vendas_Peso | Vendas_Unidades | Faturamento Bruto (em R$) |
|---|---|---|---|---|---|
| Cliente A | 1 | Produto 1 | 2 | 4 | 50 |
| Cliente B | 1 | Produto 2 | 1 | 2 | 30 |
| Cliente B | 1 | Produto 3 | 1 | 2 | 20 |
| Cliente B | 1 | Total (A) | 4 | 8 | 100 |
| Cliente B | 1 | Produto 1 | 2 | 4 | 40 |
| Total (A) + (B) | 1 | Produto 2 | 1 | 2 | 35 |
| Total (A) + (B) | 1 | Produto 3 | 1 | 2 | 25 |
| Total (A) + (B) | 1 | Total (B) | 4 | 8 | 100 |
| Total (A) + (B) | 1 | NA | 8 | 16 | 200 |
| Cliente A | 2 | Produto 1 | 2 | 4 | 50 |
| Cliente B | 2 | Produto 2 | 1 | 2 | 30 |
| Cliente B | 2 | Produto 3 | 1 | 2 | 20 |
| Cliente B | 2 | Total (A) | 4 | 8 | 100 |
| Cliente B | 2 | Produto 1 | 2 | 4 | 40 |
| Total (A) + (B) | 2 | Produto 2 | 1 | 2 | 35 |
| Total (A) + (B) | 2 | Produto 3 | 1 | 2 | 25 |
| Total (A) + (B) | 2 | Total (B) | 4 | 8 | 100 |
| Total (A) + (B) | 2 | NA | 8 | 16 | 200 |

