- Oferta (produto): PIB é igual ao valor bruto da produção, a preços básicos, menos o consumo intermediário, a preços de consumidor, mais os impostos, líquidos de subsídios, sobre produtos;
- Demanda (despesa): PIB é igual a despesa de consumo das famílias, mais o consumo do governo, mais o consumo das instituições sem fins de lucro a serviço das famílias (consumo final), mais a formação bruta de capital fixo, mais a variação de estoques, mais as exportações de bens e serviços, menos as importações de bens e serviços;
- Renda: PIB é igual à remuneração dos empregados, mais o total dos impostos, líquidos de subsídios, sobre a produção e a importação, mais o rendimento misto bruto, mais o excedente operacional bruto.
Os dados do PIB são divulgados trimestralmente pelo IBGE nas Contas Nacionais Trimestrais. Nesse sistema são disponibilizados os valores correntes (R$) e índice de volume (base: média de 1995 = 100) para o PIB e seus componentes.
A evolução do PIB brasileiro no período recente pode ser conferida no gráfico abaixo:

A economia brasileira já passou por diversas crises nas últimas décadas, internas e externas, o que faz com que sua taxa de crescimento seja um tanto quando volátil. A média de crescimento, medida pelo PIB, desde o final dos anos 90 gira em torno de 2,2%, em termos anuais.
Pela complexidade de cômputo e pela sensibilidade a crises e choques adversos, é razoável pensar que produzir previsões para o PIB é uma tarefa difícil e não muito glamourosa para profissionais que trabalham com previsão. De fato, é um desafio e neste exercício vamos explorar algumas abordagens disponíveis, desde as mais simples até as mais complexas, com o objetivo de comparar opções em termos de acurácia.
Modelos
Abordagem 1: modelos univariados
A abordagem mais simples possível é modelar o PIB com o uso de modelos univariados de séries temporais, como o modelo ARIMA que é usado pelo próprio IBGE para o processo de ajuste sazonal da série do PIB.
Por sua simplicidade, não podemos esperar resultados muito interessantes destes modelos, dado que eles exploram, basicamente, os valores passados da série temporal para previsão de valores futuros. Na economia nem sempre o passado é útil para explicar ou prever o futuro. A forma geral destes modelos é essa:
yt′ = c + ϕ1yt−1′ + ⋯ + ϕpyt−p′ + θ1εt−1 + ⋯ + θqεt−q + εt
Aqui y′ é a série temporal estacionária (em nível ou nas diferenças), c é uma constante (intercepto) do modelo, ε é o erro defasado e os demais termos são parâmetros a serem estimados. Na prática utiliza-se a metodologia de Box & Jenkins e para mais detalhes veja Hyndman e Athanasopoulos (2021).
Abordagem 2: modelos hierárquicos
A série do PIB é resultado da soma de alguns componentes, a depender da ótica de cálculo empregada. Explorando essa característica, existe uma literatura que explora técnicas envolvendo modelos de previsão hierárquicos de maneira a, por exemplo, desagregar a série “total” em componentes, modelar e produzir previsões para estes componentes e, por fim, agregar as previsões individuais para obter a previsão da série “total”.
De modo geral, podemos representar essa técnica, aplicada ao PIB pela ótica da oferta, como:
PIBt = VAAgropecuária,t + VAIndústria,t + VAServiços,t + Impostos líquidost
Ou seja, para qualquer observação no tempo t para a série PIB, as observações no nível inferior da hierarquia da série (neste caso, os componentes de valor adicionado e impostos líquidos) serão agregadas para formar as observações da série acima.
Existem várias abordagens para gerar previsões hierárquicas com séries temporais, a mais comum e intuitiva é a bottom-up (de baixo para cima), descrita acima, onde primeiro geramos as previsões para cada série no nível inferior e, em seguida, somamos os pontos de previsão para obter previsões da série acima.
Por outro lado, a abordagem top-down (de cima para baixo) envolve primeiro a geração de previsões para a série agregada e, em seguida, desagregá-la na hierarquia utilizando proporções (geralmente baseadas na série histórica).
Ainda existem outras abordagens como a do Minimum Trace e suas variantes, sendo que cada uma tem seus prós e contras. Para um exemplo veja este artigo e para mais detalhes veja Hyndman e Athanasopoulos (2021).
Abordagem 3: modelos de nowcasting
Nowcasting é uma abordagem moderna para monitorar as condições econômicas em tempo real. Diferentemente das técnicas de previsão tradicionais, nesta abordagem o interesse é em prever os indicadores durante o período de referência dos mesmos, ou logo após.
Por exemplo, o PIB é divulgado para os trimestres de cada ano — esse é o período de referência da série —, no entanto, a publicação dos dados só é realizada após a compilação dos dados e cálculos internos pelo IBGE, o que costuma acontecer dois meses após o período de referência. Neste caso, a abordagem de nowcasting seria empregada durante o período de referência ou até antes da data de divulgação dos dados.
O método mais utilizado por trás das previsões de um nowcasting é o modelo de fator dinâmico, que condensa a informação de numerosas séries de dados em um pequeno número de fatores. A representação em espaço de estado do modelo de fator dinâmico formaliza como os mercados leem os dados econômicos em tempo real. O filtro de Kalman gera projeções para todas as séries de dados e estimativas para cada lançamento. Quando há o anúncio de novos dados, há uma alteração no modelo, chamada de “notícia”.
Formalmente, o modelo de fator dinâmico é representado com duas equações:
xt = μ + Λft + εt
ft = ∑i=1p Aift−i + But
Na primeira equação, x representa séries temporais observáveis que são expressadas como uma função de um intercepto μ, de r fatores comuns não observáveis f e de um termo de erro aleatório ε. As variáveis observáveis x são carregadas para fatores comuns não observáveis via Λ. Na segunda equação, é imposto uma estrutura de um processo VAR(p) para os fatores f, onde A são os coeficientes autorregressivos e u é um termo de erro aleatório. Para mais detalhes veja De Valk et al. (2019).
Abordagem 4: técnicas de aprendizagem de máquina
Em um contexto crescente de abundância de dados e de recursos computacionais, as técnicas de aprendizagem de máquina têm sido cada vez mais utilizadas no contexto de previsão de variáveis macroeconômicas. Existem diversos métodos disponíveis e a literatura especializada está em constante evolução.
Para o propósito deste exercício selecionamos alguns métodos para testar, descritos na tabela abaixo.
Estratégia de previsão
Propomos uma estratégia como uma forma sistemática de acompanhamento dos dados, previsão e avaliação de modelos para o PIB do Brasil.
A principal motivação de ter uma estratégia bem definida é por conta do “problema de borda irregular” ou, no inglês, ragged edge problem (Wallis, 1986). Esse problema acontece quando há diferenças nos atrasos de publicação entre as variáveis de um modelo, resultando em um conjunto incompleto de dados para o período mais recente. Existem algumas alternativas para contornar o problema, mas, em geral, é empregado um método de imputação de dados.
Para o propósito deste exercício de previsão a ideia é produzir previsões utilizando toda a informação disponível sempre um mês antes da divulgação do próximo dado do PIB para qualquer período de referência, o que totaliza 4 previsões por ano. Um mês após gerar previsões, h períodos à frente, o PIB do último período de referência é divulgado e então é hora de avaliar a acurácia das últimas previsões dos modelos. Entre período de avaliação de acurácia dos modelos e a próxima produção de previsões para o PIB, os dados de maior frequência devem ser acompanhados e ajustes dos modelos podem ser feitos.
Um resumo do problema da borda irregular e um desenho de estratégia de previsão aplicada ao PIB é exposto abaixo:
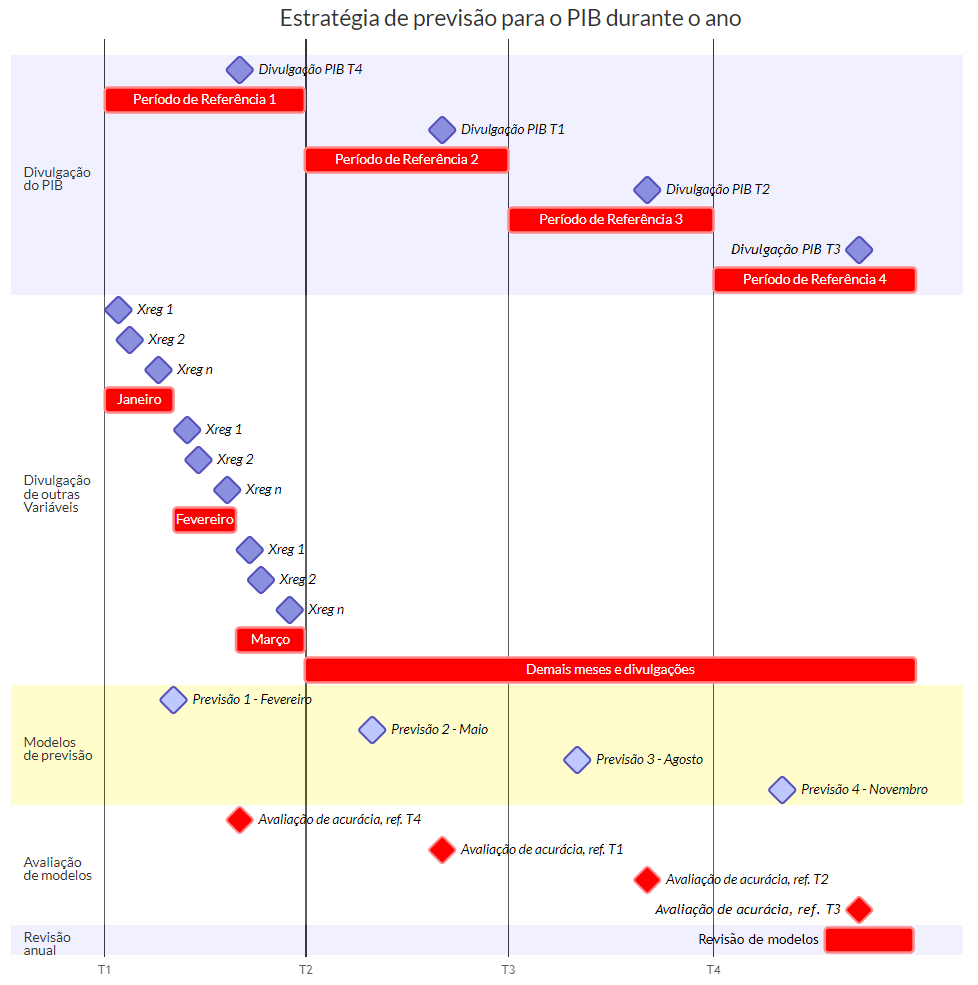
Essa é apenas uma visão geral e didática da estratégia, não constituindo uma regra a ser seguida à risca. Muitos profissionais que trabalham com previsão macroeconômica produzem novas previsões, por exemplo, logo após a divulgação do indicador de interesse ou quando há fatos relevantes, como mudanças de política econômica ou de legislação.
Métodos
| N | Método | Descrição | Abordagem | Tipo | Biblioteca | Código | Referência |
|---|---|---|---|---|---|---|---|
| 1 | Passeio Aleatório | Previsão é o último valor observado | Estatística | Estatística | skforecast |
ForecasterEquivalentDate() |
Hyndman and Athanasopoulos (2021) |
| 2 | ARIMA | Previsão com base na inércia, médias móveis e diferenciação da série | Econometria | Regressão | skforecast |
ForecasterSarimax() |
Durbin et al. (2012) |
| 2 | VAR | Regressão linear multivariada | Econometria | Regressão | skforecast |
ForecasterAutoregMultiVariate() |
Lütkepohl (2005) |
| 3 | Ridge | Penaliza os coeficientes da regressão linear com α | Estatística | Regressão | sklearn |
Ridge() |
Friedman et al. (2010) |
| 4 | Lasso | Penaliza os coeficientes da regressão linear e selecionar variáveis com α | Estatística | Regressão | sklearn |
Lasso() |
Kim et al. (2007) |
| 6 | Elastic-Net | Combina Ridge e Elastic-Net | Estatística | Regressão | sklearn |
ElasticNet() |
Link |
| 7 | Bayesian Ridge | Estimativas probabilísticas p/ parâmetros, com prior Gamma para α e λ | Estatística | Regressão | sklearn |
BayesianRidge() |
Tipping (2001) |
| 8 | Huber Regression | Aplica uma perda linear em outliers | Estatística | Regressão | sklearn |
HuberRegressor() |
Huber and Ronchetti (2009) |
| 9 | Quantile Regression | Estima um determinado quantil da distribuição (ex: mediana), não exatamente a média | Estatística | Regressão | sklearn |
QuantileRegressor() |
Koenker and Bassett (1978) |
| 10 | Support Vector Machines | Busca encontrar hiperplano que melhor se ajusta aos dados dentro de uma margem de erro. | Machine Learning | Regressão | sklearn |
LinearSVR() |
Link |
| 11 | K Nearest Neighbors Regression | Previsão é a média dos pontos de dados mais próximos | Machine Learning | Não paramétrico | sklearn |
KNeighborsRegressor() |
Link |
| 12 | Decision Trees | Previsão com base em regras de decisão (if-then-else) inferidas dos dados | Machine Learning | Árvore de decisão | sklearn |
DecisionTreeRegressor() |
Breiman et al. (1984) |
| 13 | Gradient Boosted Decision Trees | Constrói múltiplas árvores de decisão sequencialmente, cada um corrigindo o erro da anterior | Machine Learning | Ensemble | sklearn |
GradientBoostingRegressor() |
Link |
| 14 | Random Forests | Retorna a média das árvores individuais | Machine Learning | Ensemble | sklearn |
RandomForestRegressor() |
Breiman (2001) |
| 15 | Bagging | Estima um método a ser escolhido em sub-amostras dos dados e agrega as previsões individuais | Machine Learning | Ensemble | sklearn |
BaggingRegressor() |
Breiman (1996) |
| 16 | Voting Regressor | Combinar múltiplos métodos de regressão retornando a média dos mesmos | Machine Learning | Ensemble | sklearn |
VotingRegressor() |
Link |
| 17 | AdaBoost | Estima uma sequência de métodos fracos em amostras modificadas dos dados e combina previsões por voto ou soma. | Machine Learning | Ensemble | sklearn |
AdaBoostRegressor() |
Drucker (1997) |
| 18 | Gemini | Modelo de linguagem grande | Inteligência Artificial | LLM | google.generativeai |
GenerativeModel() |
Link |
Dados
A especificação dos modelos acima neste exercício está limitada à disponibilidade da base de dados utilizada. Ajustes e adequações, quando pertinentes, serão feitos.
Resultados
Para obter a aula referente à esse exercício faça parte do Curso de Previsão Macroeconômica usando IA e Python.
Para simplificar, aplicamos dois modelos citados acima, ARIMA e Gemini, e separamos os dados em uma amostra de treino e uma de teste para comparar a acurácia entre os modelos. Abaixo exibimos as previsões dos modelos, uma previsão média e os valores observados no período:
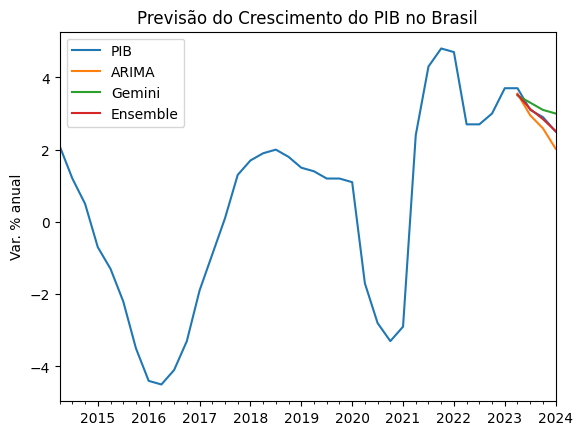
Erro médio do ARIMA é: 0.272
Erro médio do Gemini é: -0.175
Erro médio do Ensemble é: 0.048Sendo assim, para esta amostra sugere-se que o melhor modelo é a média de duas abordagens, ARIMA e Gemini, tirando proveito dos dois mundos.
Referências
Chen, T., & Guestrin, C. (2016). Xgboost: A scalable tree boosting system. In 22nd SIGKDD Conference on Knowledge Discovery and Data Mining.
De Valk, S., de Mattos, D., & Ferreira, P. (2019). Nowcasting: An R package for predicting economic variables using dynamic factor models. The R Journal, 11(1), 230-244.
Hyndman, R. J., & Athanasopoulos, G. (2021) Forecasting: principles and practice, 3rd edition, OTexts: Melbourne, Australia. OTexts.com/fpp3. Accessed on 2023-02-27.
Wallis, K. F. (1986). Forecasting with an econometric model: The ‘ragged edge’ problem. Journal of Forecasting, 5(1), 1-13.
Quer aprender mais?
Para obter a aula referente à esse exercício faça parte do Curso de Previsão Macroeconômica usando IA e Python.

