Variáveis fiscais, como a dívida bruta, são de grande interesse para o próprio governo, mas também para investidores e consumidores. Suas trajetórias podem impactar decisões de investimento e mudar a dinâmica futura da economia. Ao mesmo tempo, estas variáveis são definidas de forma complexa e, muitas vezes, na "canetada", o que dificulta sua previsibilidade.
Neste exercício, contruímos um algoritmo simples de cenarização para a Dívida Bruta do Governo Geral (DBGG) em % do PIB, usando apenas dados públicos, simulações estatísticas, a literatura recente e a linguagem R. Em uma abordagem semi-automatizada, as simulações do modelo se aproximam das previsões do mercado para o ano de 2025.
Introdução
Nem sempre é útil aplicar modelos econométricos ou de machine learning para fazer previsões. Como exemplo, no exercício de hoje exploraremos uma equação proveniente dos livros-texto de macroeconomia que explica a dinâmica da dívida pública no país: a chamada equação de sustentabilidade da dívida pública.
![\[\Delta D = p + (r - \gamma) \times D\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-44ce2847cf01866b2284979d399496b3_l3.png "Rendered by QuickLaTeX.com")
Onde:
 = variação da dívida bruta em p.p. do PIB;
= variação da dívida bruta em p.p. do PIB;
 = resultado primário em % do PIB;
= resultado primário em % do PIB;
 = taxa real de juros em %;
= taxa real de juros em %;
 = taxa de crescimento do PIB em %;
= taxa de crescimento do PIB em %;
 = nível de endividamento bruto em % do PIB.
= nível de endividamento bruto em % do PIB.
Essa equação pode nos ajudar a obter, por exemplo, o esforço necessário em termos de resultado primário para manter a dívida bruta estável (  ). Porém, nosso interesse é projetar a DBGG para o ano seguinte.
). Porém, nosso interesse é projetar a DBGG para o ano seguinte.
Conforme a equação, diversas variáveis explicam a dívida bruta. Neste caso, podemos fazer previsões para a DBGG para o ano seguinte com base no que esperamos através de cenários para estas variáveis explicativas.
Por exemplo, atualmente a economia brasileira se encontra em um ciclo de aperto monetário, portanto esperamos que a taxa de juros continue subindo nos próximos meses. Sendo assim, podemos projetar a DBGG para diferentes cenários para os juros, além de também considerar a interação com as demais variáveis da equação.
Nesse contexto, uma prática comum é gerar distribuições que reflitam o nosso balanço de riscos (por exemplo, aperto monetário) para cada variável e então usar essas distribuições para gerar n cenários conjuntos para a variável final (DBGG).
Sendo assim, se quisermos usar essa equação para projetar a dívida bruta para o ano seguinte, precisamos de cenários para quatro variáveis: resultado primário, taxa de juros nominal (Selic), inflação (IPCA) e crescimento do PIB.
Dados
Para obter o código e o tutorial deste exercício faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
Para simplificar, usaremos os dados do último relatório Focus/BCB para servir de base na criação dos cenários das variáveis.
Para o resultado primário, utilizaremos a última expectativa disponível (mediana). Já para as demais variáveis, utilizaremos dois parâmetros: a mediana e o desvio padrão da última expectativa disponível, que serão úteis para criar distribuições assimétricas com a ajuda do pacote sn (Skew-Normal distribution).
Estes parâmetros (diretos) serão transformados em parâmetros centrados que denotam a localização, escala e inclinação da distribuição assimétrica a ser gerada para cada variável. Verifique a documentação de sn::cp2dp para detalhes.
A inclinação será apontada com base na análise do último Relatório de Distribuições de Frequência (Expectativas de Mercado) do BCB, levando em conta o horizonte de interesse nesse exercício (2025), dando a assimetria à distribuição.
Para gerar os cenários a partir dos parâmetros centrados, rodaremos 50 ou 100 simulações (tamanho da amostra da distribuição) de cada variável usando a função sn::rsn e, então, utilizaremos todas as combinações possíveis desses cenários para construir a simulação da DBGG para o próximo ano, partindo do nível atual e das expectativas para o resultado primário.
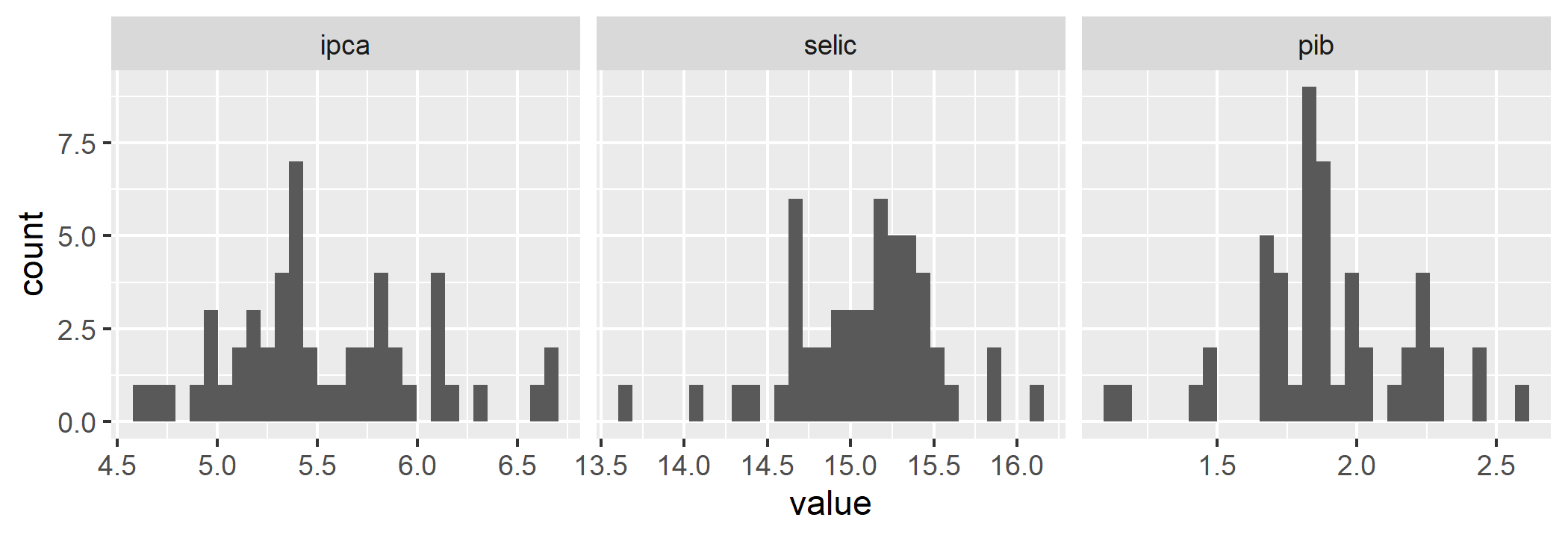
O gráfico abaixo apresenta as simulações das variáveis "exógenas":
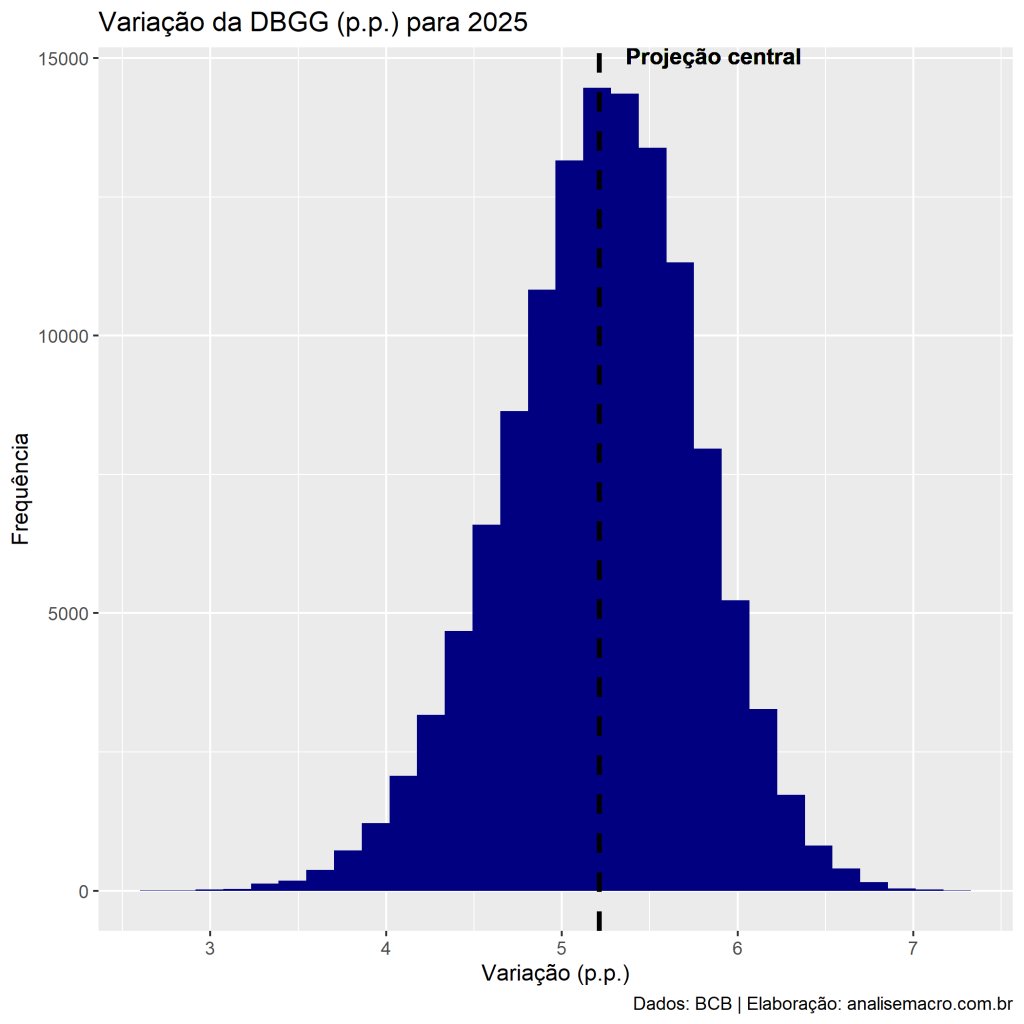
Por fim, combinamos os cenários gerados e usamos estes valores na equação de sustentabilidade da dívida pública para simular a variação da DBGG no próximo ano:
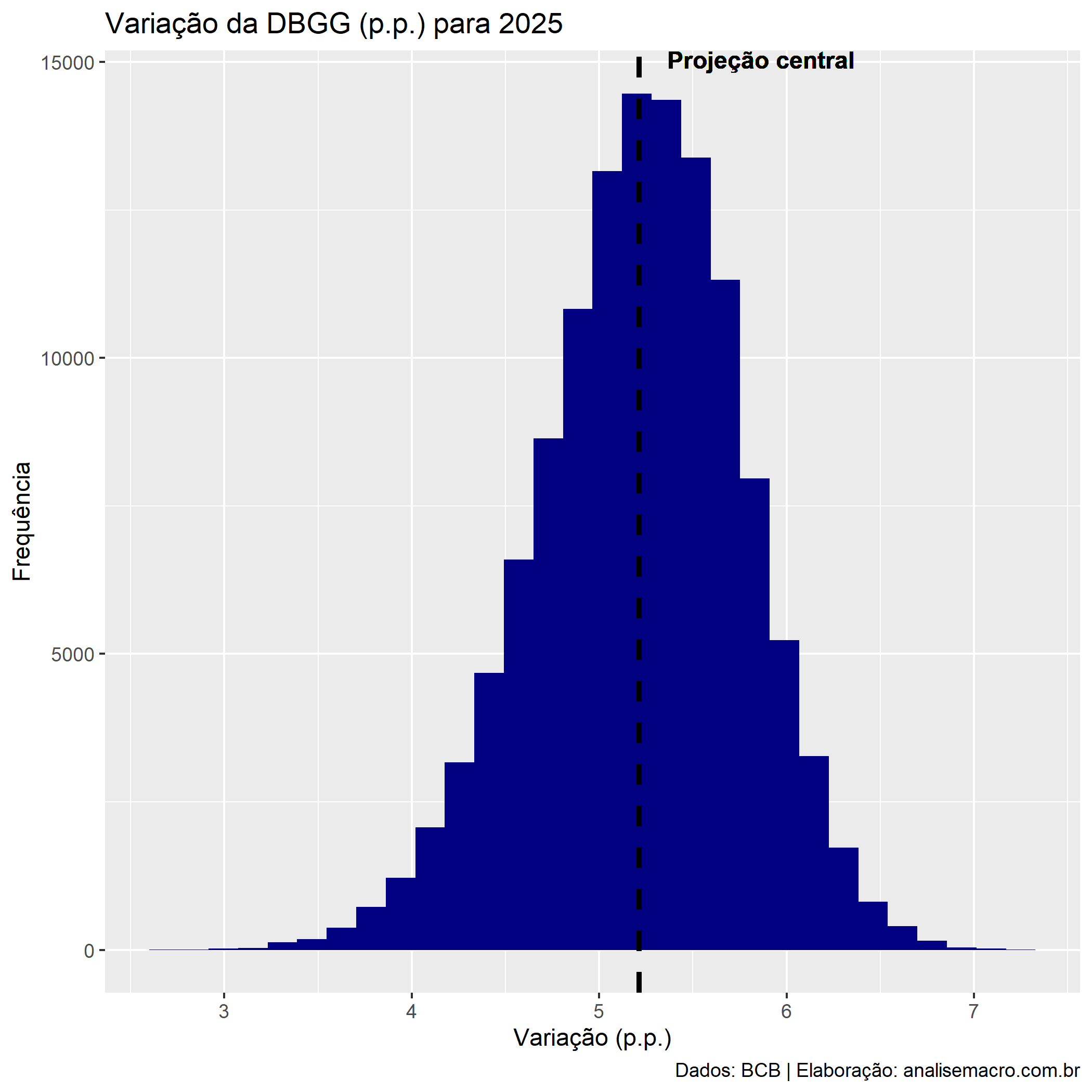
A simulação diz que em 2025 a DBGG deve variar cerca de 5,1 p.p, ou seja, deve encerrar o ano em 76,11% (ano anterior) + 5,1 p.p (projeção do ano corrente) = 81,21%. Esse valor é praticamente idêntico ao projetado pelo último relatório Focus.
Referências
Salto, F. S. (2018). "Dívida bruta: evolução e projeções". In: Senado Federal: Instituição Fiscal Independente, Estudo Especial n. 7.
Tenha acesso ao código e suporte desse e de mais 500 exercícios no Clube AM!
Quer o código desse e de mais de 500 exercícios de análise de dados com ideias validadas por nossos especialistas em problemas reais de análise de dados do seu dia a dia? Além de acesso a vídeos, materiais extras e todo o suporte necessário para você reproduzir esses exercícios? Então, fale com a gente no Whatsapp e veja como fazer parte do Clube AM, clicando aqui.

