Variáveis fiscais, como o resultado primário, são de grande interesse para o próprio governo, mas também para investidores e consumidores. Suas trajetórias podem impactar decisões de investimento e mudar a dinâmica futura da economia. Ao mesmo tempo, estas variáveis são definidas de forma complexa e, muitas vezes, na "canetada", o que dificulta sua previsibilidade.
Neste exercício, contruímos um modelo simples de previsão para o Resultado Primário do Setor Público Consolidado (acumulado em 12 meses, % PIB), usando apenas dados públicos, modelos econométricos, a literatura recente e a linguagem R. Em uma abordagem automatizada, as previsões do modelo se aproximam das previsões do mercado para o ano de 2025.
Introdução
Não é sempre que encontramos na literatura de previsão de séries temporais trabalhos que possibilitem um ponto de partida para um dado problema de previsão a ser resolvido. No caso de variáveis fiscais isso parece ser mais comum de acontecer e o Resultado Primário é um exemplo.
Sendo assim, iremos recorrer aos livros-texto, utilizando a equação de sustentabilidade da dívida pública em frameworks de previsão já conhecidos. Utilizaremos como referência os trabalhos de Salto (2018) e Hyndman and Athanasopoulos (2021).
Estimaremos o total de 8 modelos para comparação, incluindo variações de:
- Random Walk (RW)
- Auto-regressivo (AR)
- Suavização exponencial em espaço de estado (ETS)
- Auto-Regressivo Integrado de Médias Móveis (ARIMA) univariado e multivariado
- Regressão linear (OLS)
Dados
Para obter o código e o tutorial deste exercício faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
Utilizaremos as seguintes variáveis nos modelos:

Workflow de previsão automática
- Importação de dados online;
- Tratamento prévio de dados e remoção de atrasos de publicação;
- Verificar estacionariedade (ADF, PP e KPSS) e aplicar diferenças necessárias;
- Validação cruzada: estimação e previsão recursiva dos modelos, considerando sequência crescente da amostra de dados (amostra inicial com 90 observações e previsão 12 meses à frente);
- Cálcular medidas de acurácia para comparação e escolha de modelo final;
- Previsão fora da amostra.
Resultados
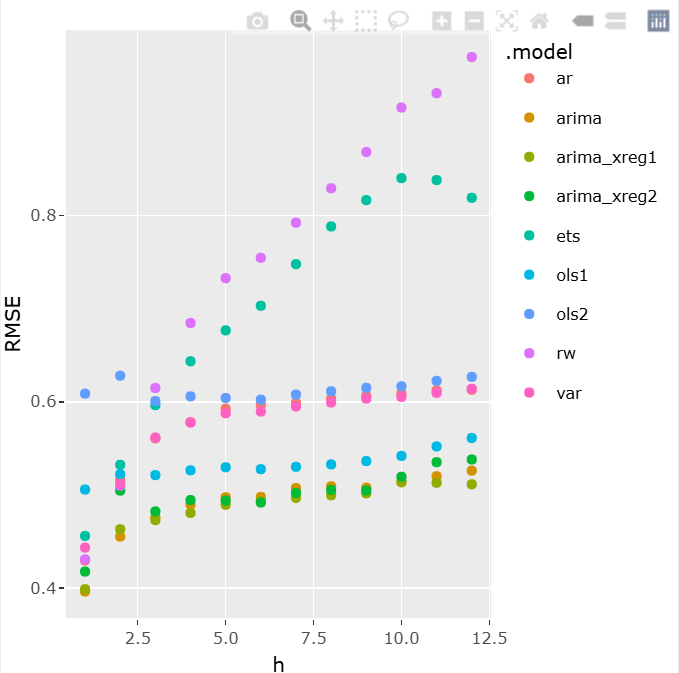
Da etapa de validação cruzada, calculamos métricas de erro de previsão, como o RMSE, de cada modelo. O comparativo entre os modelos é posto no gráfico abaixo:
Modelo final
A família de modelos ARIMA obteve melhor performance preditiva em termos de RMSE, com valores muito próximos entre si para cada horizonte de previsão (meses). O modelo univariado é de simples estimação e previsão, tendo vantagem em relação aos multivariados que precisam de cenários para as variáveis independentes. Esta seria uma forma de escolha entre os modelos.
Por outro lado, o analista poderia preferir um rigor maior na escolha do modelo final verificando se há diferenças entre os mesmos com testes estatísticos conforme abordado no curso de Modelos Preditivos da Análise Macro.
Dito isso, optamos por usar para previsão o modelo ARIMA multivariado que usa como regressores as variáveis da equação de sustentabilidade da dívida pública.
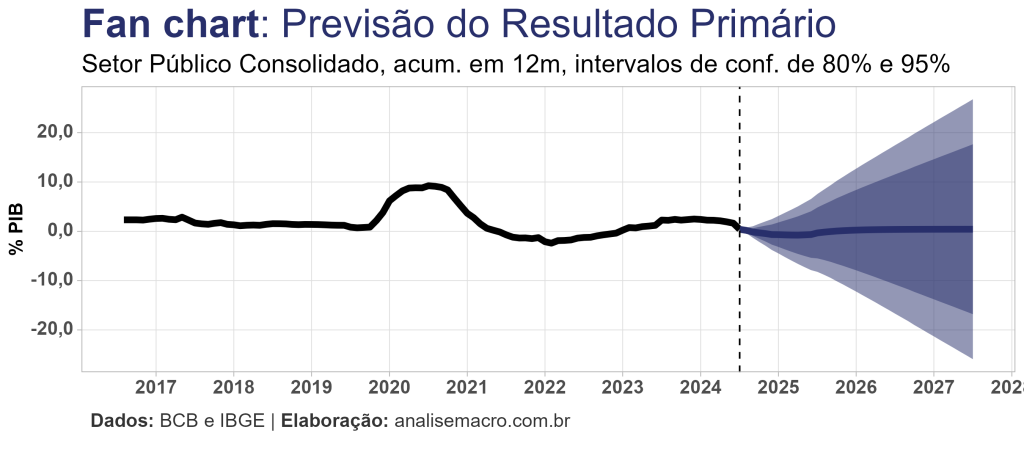
Previsão fora da amostra
Por fim, reestimamos o melhor modelo identificado com a amostra completa de dados, diagnosticamos os resíduos e geramos previsão 36 meses à frente:
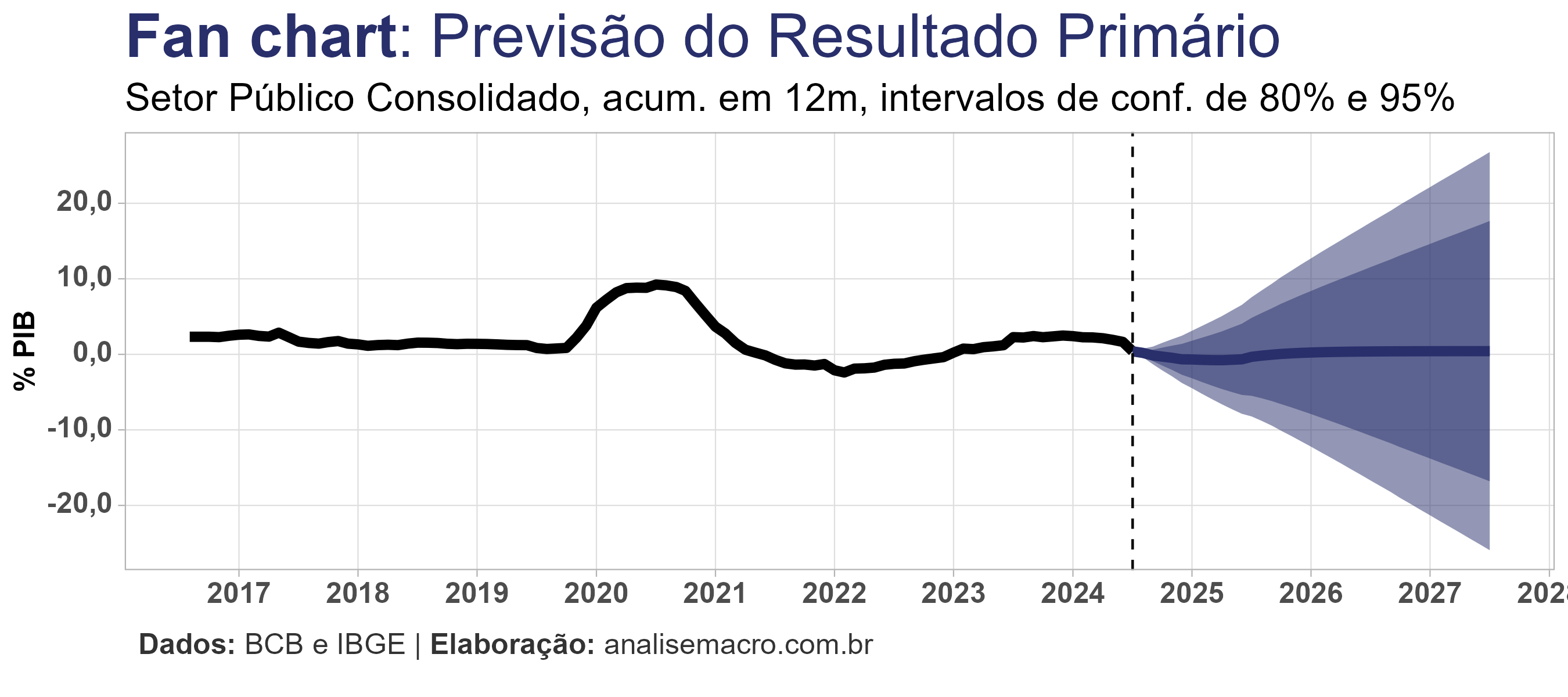
Optou-se por gerar cenários para as variáveis independentes através de modelos univariados de previsão (auto ARIMA).
Para o fim de 2025 o modelo prevê um défict de 0,33%, enquanto que o mercado projeta um déficit de 0,60.
Referências
Hyndman, R. and G. Athanasopoulos (2021). Forecasting: principles and practice. 3rd ed. OTexts: Melbourne, Australia.
Salto, F. S. (2018). "Dívida bruta: evolução e projeções". In: Senado Federal: Instituição Fiscal Independente, Estudo Especial n. 7.
Tenha acesso ao código e suporte desse e de mais 500 exercícios no Clube AM!
Quer o código desse e de mais de 500 exercícios de análise de dados com ideias validadas por nossos especialistas em problemas reais de análise de dados do seu dia a dia? Além de acesso a vídeos, materiais extras e todo o suporte necessário para você reproduzir esses exercícios? Então, fale com a gente no Whatsapp e veja como fazer parte do Clube AM, clicando aqui.

