gt é um pacote de R para gerar tabelas bem formatadas, usando uma gramática/sintaxe intuitiva. Neste texto exploramos como construir tabelas que prendem a atenção do leitor, partindo de um exemplo básico a um exemplo avançado.
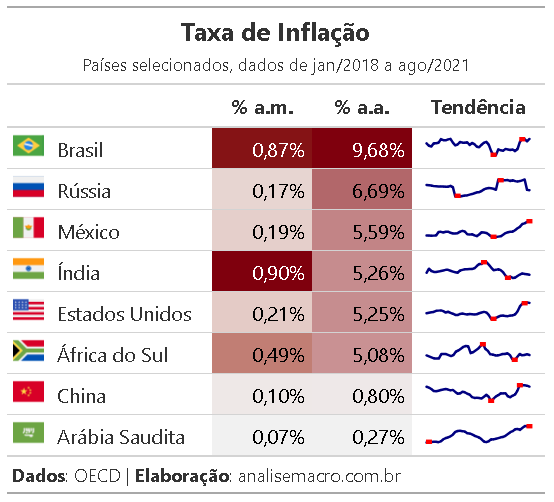
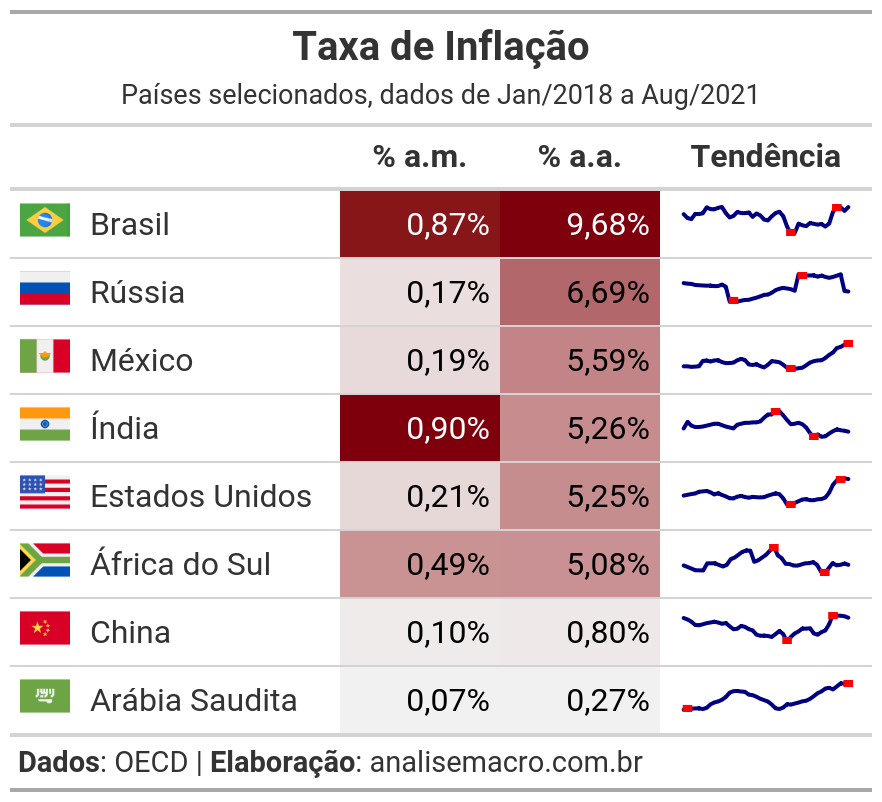
Prévia da tabela a ser construída:
Pacotes
Para reproduzir os códigos certifique-se de que tenha os seguintes pacotes de R instalados:
Preparar dados
Vamos começar primeiro preparando alguns dados para o exercício. Utilizaremos novamente dados de inflação provenientes da base de dados da OECD, já abordados anteriormente aqui. Além disso, utilizaremos alguns arquivos de imagens que são os PNGs com as bandeiras de alguns países. Essas imagens serão utilizadas na tabela, conforme visto acima.
O código abaixo realiza o download do arquivo ZIP de imagens para uma pasta temporária, descompacta o arquivo, coleta dados de inflação de países selecionados da OECD e realiza tratamentos necessários.
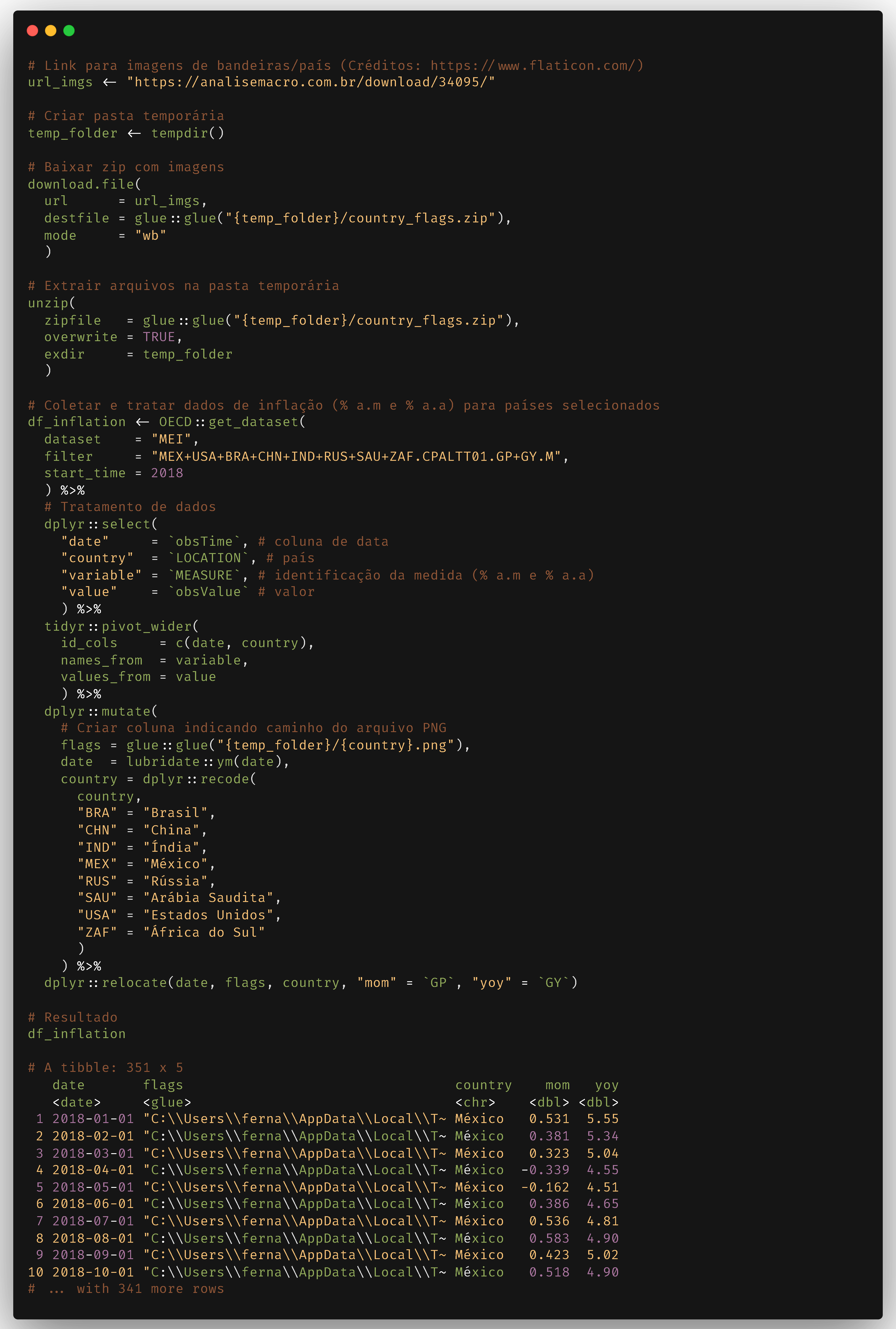
Tabela simples
Com os dados preparados, vamos ao primeiro exemplo básico gerando uma tabela com o gt:

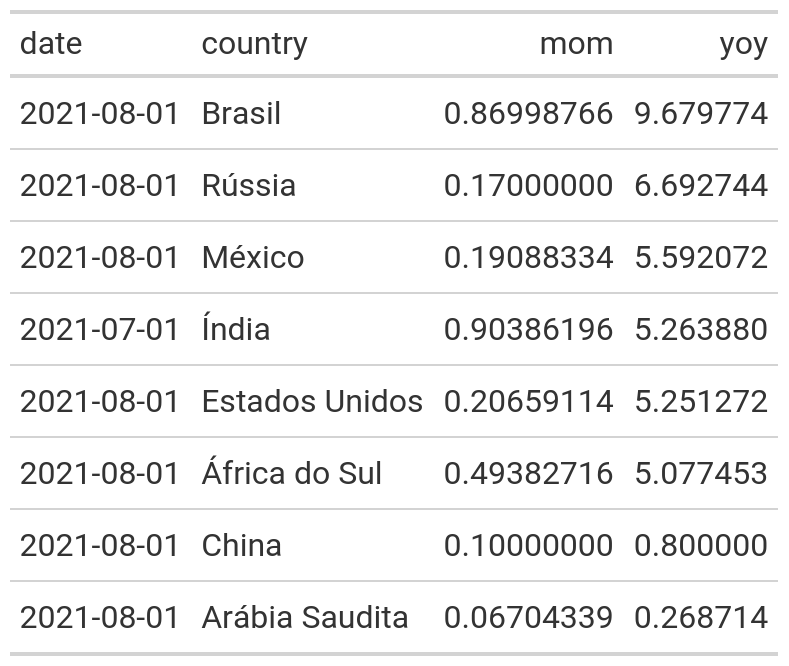
Com uma única função o gt cria uma tabela de dados através de um data frame ou tibble! Mas podemos deixá-la mais informativa, colocando título, subtítulo, fonte, nomes de colunas, etc.:
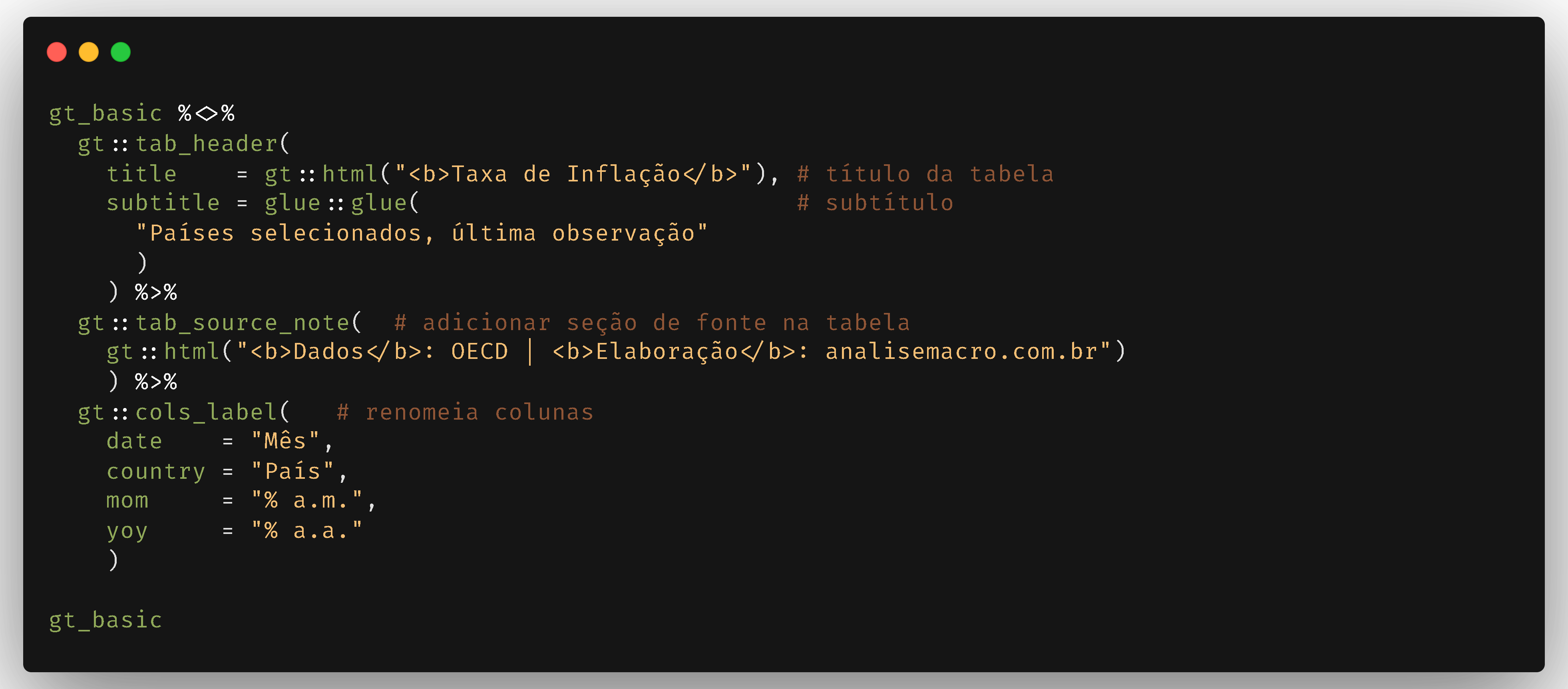
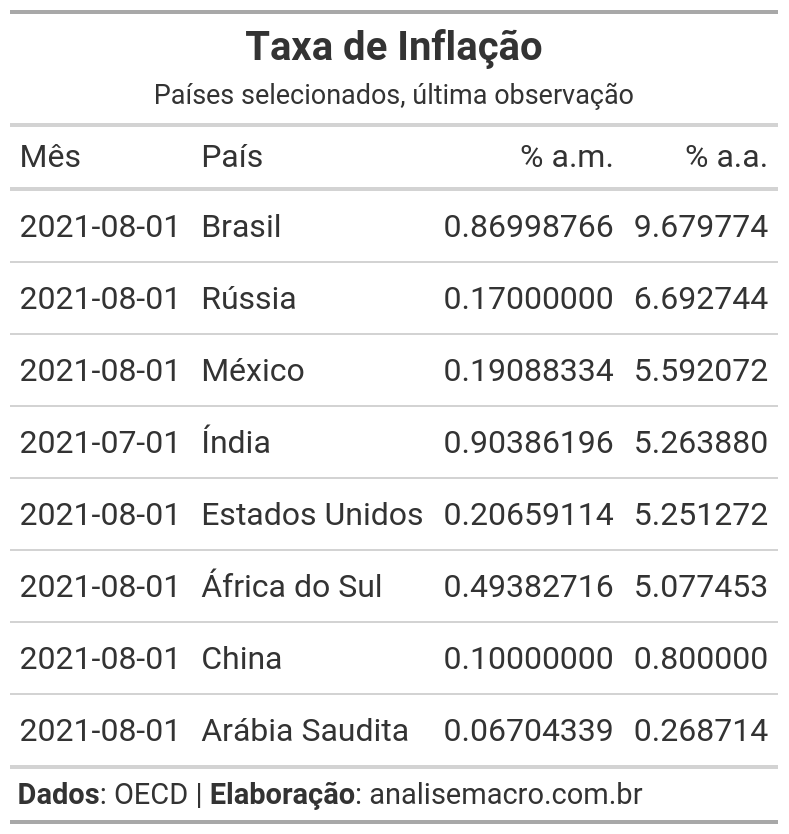
Muito melhor, não? Mas ainda podemos melhorar, formatando os valores das células para 2 casas decimais com sufixo, além de criar um mapa de calor nas colunas numéricas:
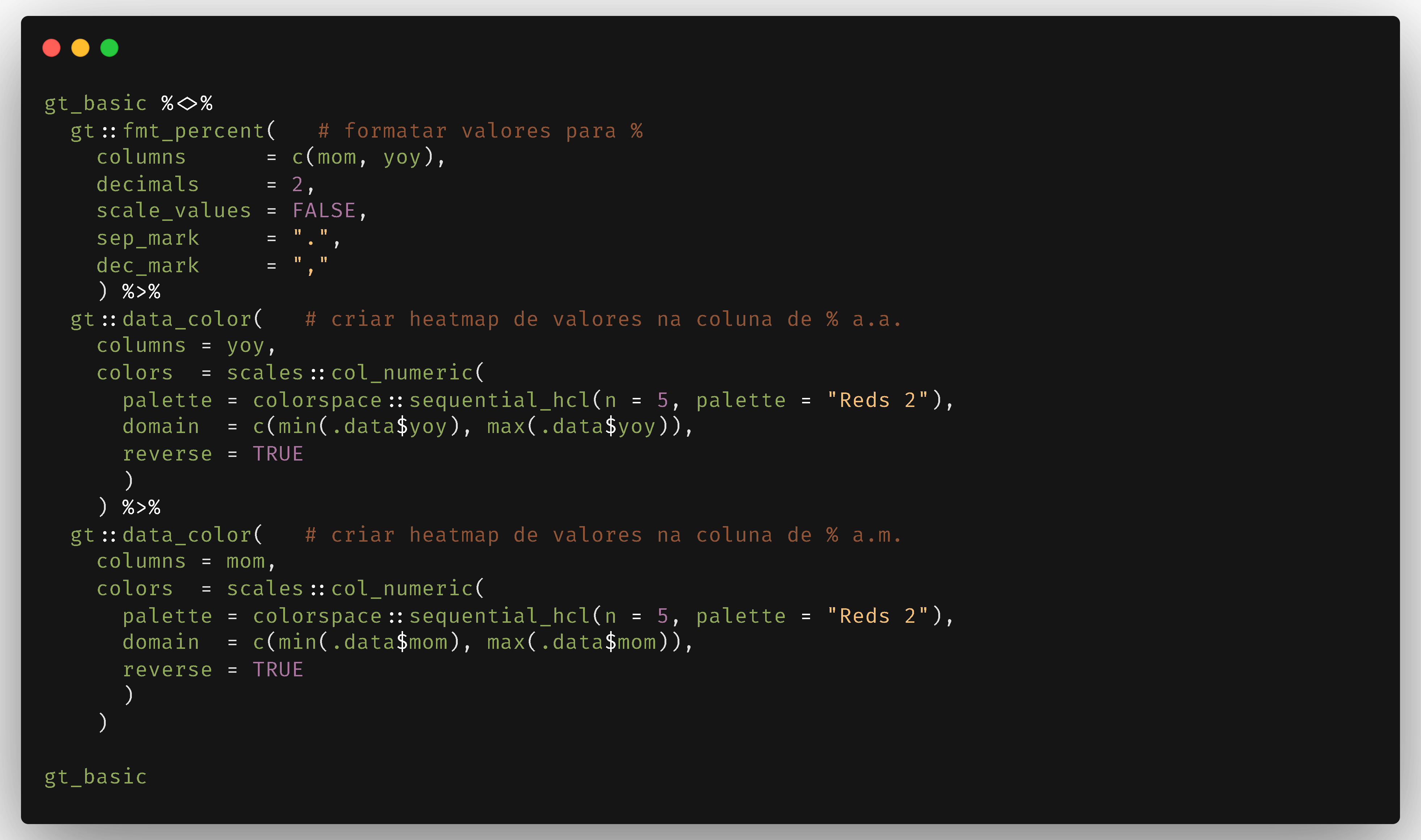
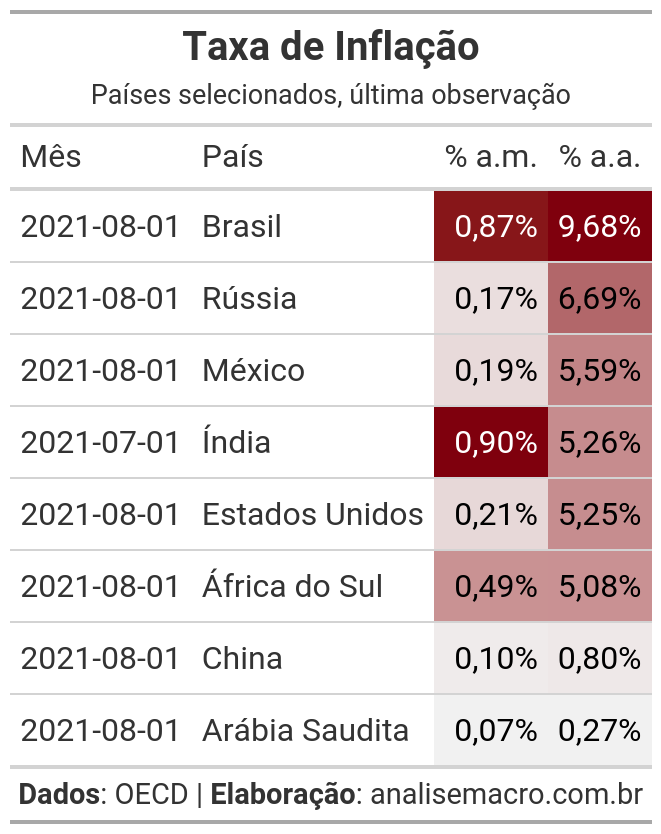
Tabela estilizada
Agora que já exploramos o básico das funcionalidades do pacote gt, chegando a uma tabela mais "apresentável", vamos avançar mais uns passos para construir a tabela final que apresentamos logo no início.
O objetivo agora é adicionar em nossa tabela básica duas coisas: (1) uma linha de tendência que demonstra o comportamento da taxa de inflação de 2018 em diante e (2) as bandeiras de cada país.
Para as linhas de tendência, recurso que é chamado de "sparkline", primeiro criamos um objeto lista que vai armazenar vetores com os dados da taxa de inflação (% a.a.) de cada país. São esses vetores da lista que formarão as linhas de tendência, que serão lidos e interpretados pela função gt_sparklines que criamos na sequência. Essa função transformará os valores de uma determinada coluna de um objeto gt em sparklines usando dados externos (lista de vetores).
Já para adicionar as imagens de bandeiras de cada país usamos a função text_transform em conjunto com a função local_image, que farão a leitura do caminho para os arquivos de imagens informado na coluna flags e transformarão essa coluna com a renderização das imagens.
Abaixo colocamos o código completo, contemplando o que foi visto acima com essas duas adições:
________________________
(*) Para entender mais sobre a linguagem R e suas ferramentas, confira nosso Curso de Introdução ao R para análise de dados.

