Uma etapa crucial ao construir modelos de regressão é avaliar a qualidade da estimação, investigando o quão bem os modelos se ajustam aos dados. Em um mundo com uma infinidade de modelos e pacotes, essa tarefa pode se tornar demasiadamente trabalhosa, mas graças ao pacote performance desenvolvido pela equipe do easystats é possível realizar o "trabalho sujo" de maneira rápida e fácil.
O pacote oferece diversas funcionalidades para reportar medidas de acurácia como R2, RMSE, AIC, BIC, ICC, resultados de testes de multicolinearidade, heterocedasticidade, autocorrelação, etc. Em resumo, parece ser um excelente pacote para adicionar ao framework de modelagem! Vamos a alguns exemplos de uso do pacote, provenientes da própria documentação.

Medidas de performance do modelo
Com a função model_performance() podemos obter as principais medidas de performance de variados modelos que o pacote contempla. Como exemplo, vamos estimar três modelos básicos: linear, logístico e misto (mixed model) usando o dataset mtcars. Os pacotes utilizados podem ser instalados/carregados conforme abaixo:
# Instalar/carregar pacotes
if(!require("pacman")) install.packages("pacman")
pacman::p_load(
"performance",
"lme4",
"see",
"qqplotr"
)
1) Regressão linear
m1 <- lm(mpg ~ wt + cyl, data = mtcars) model_performance(m1)

2) Regressão logística
m2 <- glm(vs ~ wt + mpg, data = mtcars, family = "binomial") model_performance(m2)

3) Mixed model
m3 <- lmer(mpg ~ hp * cyl + wt + (1 | am), data = mtcars) model_performance(m2)
 Comparar modelos
Comparar modelos
Usualmente estimamos diversos modelos para, posteriormente, compará-los. No entanto, não podemos comparar modelos que não são comparáveis, ou seja, modelos de tipos diferentes (por exemplo, linear vs. mixed model).
A função compare_performance() compara os modelos especificados fornecendo uma mensagem de aviso útil (veja abaixo). Adicionalmente, a função fornece uma classificação (ranking do melhor ao pior) superficial mas útil dos modelos.
compare_performance(m1, m2, m3, rank = TRUE) Warning messages: 1: When comparing models, please note that probably not all models were fit from same data. 2: Following indices with missing values are not used for ranking: R2, R2_adjusted, R2_Tjur, Log_loss, Score_log, Score_spherical, PCP, R2_conditional, R2_marginal, ICC
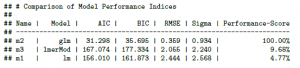
No entanto, se compararmos modelos que são comparáveis, nenhuma mensagem será exibida:
m3_1 <- lmer(mpg ~ hp + cyl + wt + (1 | am), data = mtcars) compare_performance(m3, m3_1, rank = TRUE)

Também é possível analisar visualmente essa comparação através de um gráfico:
plot(compare_performance(m3, m3_1))
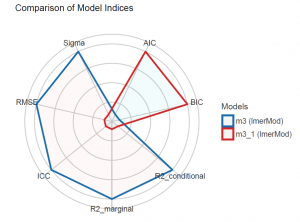
Até agora vimos que o pacote é muito útil para rapidamente obter medidas de performance dos modelos, mas ainda pode ficar melhor.
Verificar hipóteses do modelo
Outra etapa importante na modelagem é verificar as hipóteses do modelo estimado, como multicolinearidade, heterocedasticidade, autocorrelação, etc. Para isso existe a função check_model(), que gera visualmente os resultados dos testes para todas as hipóteses que você precisa verificar e oferece uma visão geral das hipóteses para quase todos os modelos que você pode estimar (ao menos para todos os modelos comuns).
Abaixo, dois exemplos mostram uma visão geral do modelo linear e do modelo misto que estimamos. Note que os subtítulos dos gráficos individuais até mesmo explicam o que você deveria encontrar!
check_model(m1)

check_model(m3)
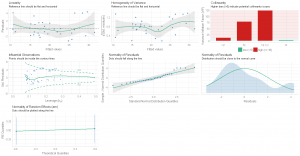
Além disso, o pacote oferece funções individuais (check_) para testes de hipóteses com o report das estatísticas.
Existem muitas outras funções úteis neste pacote. E não há necessidade de descrevê-las todas aqui. Se você gostou do que viu até agora, basta procurar a documentação do mesmo e aproveitar as facilidades que ele oferece!
Referências úteis
- Blogdown do pacote: https://easystats.github.io/performance/
- Manual do CRAN: https://cran.r-project.org/web/packages/performance/performance.pdf

________________________
(*) Para entender mais sobre modelagem estatística, confira nossos Cursos de Econometria e Machine Learning.

