Quando estimamos um modelo para previsão de séries temporais precisamos avaliar sua performance preditiva. Separar os dados em uma amostra de treino e outra de teste é a forma mais simples de verificar como o modelo performa em dados pseudo fora da amostra, através do cálculo do erro de previsão. Entretanto, a escolha das amostras é arbitrária, o que traz a tona um método mais sofisticado: a validação cruzada. Neste exercício abriremos a caixa preta por trás do assunto mostrando como implementar a técnica no R.
Neste método há uma série de amostras de teste, cada uma consistindo em h observações, ou seja, são os períodos usados para gerar previsões a partir do modelo. A amostra de treino correspondente, usada para estimação do modelo, consiste apenas de observações que ocorreram antes das observações que formam a amostra de teste. Assim, nenhuma observação futura pode ser usada na construção da previsão.
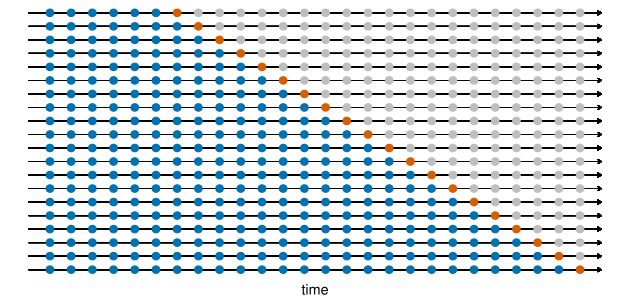
O diagrama a seguir ilustra um esquema de validação cruzada de séries temporais, com uma série de amostras de treino e de teste, para quando se deseja avaliar a performance preditiva do modelo em h = 1 períodos à frente, onde as observações azuis formam as amostras de treino e as observações laranja formam as amostras de teste.
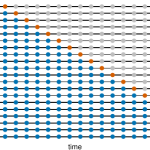
Fonte: Hyndman e Athanasopoulos (2021).
Operacionalização
Dado esse esquema de separação de uma série de amostras de treino e de teste de uma série temporal, o método de validação cruzada pode ser resumido como um procedimento recursivo:
- Para cada amostra de treino estime o modelo;
- Utilize o modelo estimado para gerar previsões h períodos à frente;
- Calcule o erro de previsão com a amostra de teste e a saída da etapa 2.
Ao final, obtém-se a métrica de acurácia (ME, RMSE, MAE, etc.) do modelo pela média de cada iteração.
Esse método é relativamente simples, mas bastante útil para validar a performance de modelos independentemente da amostra de treino/teste escolhida, trazendo uma "visão global" do modelo. A validação cruzada é largamente utilizada por praticantes de machine learning, além de ser uma prática comum em papers que tratam de previsão de séries temporais. Vale pontuar que existem variações do método, que deixaremos para explorar em uma outra oportunidade.
Implementação no R
Mostraremos duas formas de implementar validação cruzada de séries temporais no R:
- Através da família de pacotes {tidyverts};
- Abrindo a caixa preta e escrevendo o código manualmente.
Em ambos os casos utilizaremos modelos univariados simples, apenas para demonstrar o método, aplicados ao principal índice de preços da economia brasileira, o IPCA, com a finalidade de avaliar as previsões 12 períodos à frente. A primeira amostra de validação cruzada conterá 180 observações e será acrescentado 1 observação sucessivamente até o total de observações excluindo as últimas 12.
Antes de começar você deve ter disponível os seguintes pacotes no seu ambiente de R:
O código abaixo prepara os dados de exemplo. Para saber mais sobre coleta de dados macroeconômicos confira este post no blog da Análise Macro.
Exemplo com {tidyverts}
O primeiro exemplo de implementação de validação cruzada utilizará os pacotes da família {tidyverts}, que é um ótimo framework para trabalhar com séries temporais no R (confira este post sobre o assunto). Sendo assim, o primeiro passo que precisamos fazer é criar as amostras de treino de validação cruzada (observações azuis na ilustração). Isso pode ser feito conforme abaixo (note que removemos as últimas 12 observações, para poder calcular o erro de previsão da última amostra corretamente):
Agora temos uma série de amostras, partindo de 180 observações e acrescentando 1 sucessivamente, que utilizaremos para estimar os modelos de exemplo e gerar previsões. Isso é feito conforme o código abaixo. Note que criamos uma coluna para salvar a informação do horizonte temporal da previsão (isso é opcional, sendo útil apenas quando você quer analisar a acurácia por horizonte preditivo).
Por fim, podemos calcular as métricas de acurácia média considerando todas as amostras e previsões geradas, conforme abaixo:
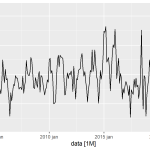
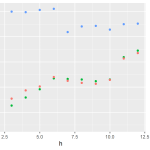
Como resultado podemos gerar a visualização abaixo, onde é possível analisar os modelos em termos de acurácia (RMSE) por horizonte preditivo:
Exemplo manual
Conforme visto, os procedimentos adotados para implementar o método de validação cruzada de séries temporais são extremamente simples utilizando os pacotes do {tidyverts}. Entretanto, nem sempre teremos à disposição, dentro deste ou outros frameworks, todos os modelos de interesse para implementação rápida através de um pacote. Na vida real, é comum que surjam novos modelos ou que os pacotes implementem e disponibilizem apenas uma parcela do que existe por aí. Nestes casos, será seu trabalho escrever um código que implemente a validação cruzada com tal modelo.
Para exemplificar, abaixo escrevo uma função que implementa o esquema de validação cruzada de forma semelhante ao que acabamos de ver. O modelo utilizado é, por conveniência, o ARIMA automatizado e a definições de amostras são idênticas ao exemplo anterior. Note que o código fica significativamente mais complexo, principalmente para iniciantes, mas é um destino natural de todo profissional que deseje se aventurar por estes caminhos.
A função implementa o que foi destacado previamente, referente ao método recursivo da validação cruzada, retornando uma lista com uma tabela do RMSE por horizonte preditivo e outra com as previsões geradas a cada iteração. Fique à vontade para adaptar ou melhorar a função conforme suas necessidades.
Com a função criada, basta utilizá-la junto aos dados para obter os resultados:
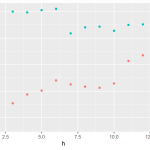
Por fim, plotamos os resultados desta abordagem manual com a abordagem anterior. Note que o RMSE calculado difere levemente. Não investiguei o motivo, mas acredito que seja decorrente de alguma parametrização diferente entre o algoritmo de forecast::auto.arima() e fable::ARIMA().
Saiba mais
Este exercício simples é um ponto de partida para você começar a implementar a validação cruzada em seus modelos de previsão de séries temporais. Caso deseje se aprofundar, confira o curso de Modelos Preditivos da Análise Macro, onde implementamos diversos modelos para séries temporais da economia brasileira.
Referências
Hyndman, R.J., & Athanasopoulos, G. (2021) Forecasting: principles and practice, 3rd edition, OTexts: Melbourne, Australia. OTexts.com/fpp3. Accessed on <2022-05-12>.

