Na era da informação, os dados estão em todos os lugares: desde o like que você dá em uma foto na rede social até a compra por aproximação que você faz no supermercado. Essa riqueza de dados que cresce em ritmo maior do que somos capazes de abstrair informações úteis, em conjunto com a proliferação de ferramentas para armazenamento e processamento, leva naturalmente à necessidade de conhecer técnicas e métodos para analisar os dados e resolver problemas de negócio.
Dessa forma, as empresas conseguem fazer recomendação personalizada de produtos e serviços, manter um alto nível de engajamento do usuário em aplicativos ou ainda minimizar o risco de inadimplência oferecendo produtos de crédito com base no perfil do cliente. Esses são apenas alguns exemplos mais comuns e do nosso dia a dia que exploram intensivamente o uso de dados com finalidades comerciais.
No entanto, para que os dados possam ser corretamente analisados e percorrer todo o ciclo, desde sua origem até a aplicação comercial em um serviço ou produto, é necessário primeiro compreender como eles são estruturados, como eles são representados em linguagens de programação modernas e quais ferramentas podem ser usadas para trabalhar com os mesmos. Neste artigo, vamos explorar os conceitos das principais estruturas de dados, ver exemplos e entender como trabalhar dados do tipo série temporal ou corte transversal.
O que são dados de corte transversal (cross section)?
Os dados de corte transversal (cross section, no inglês) são estruturas de dados tabulares que são coletados em apenas um período no tempo, podendo ser sobre diversas observações (como pessoas, empresas, países, etc.). É uma estrutura de dados muito utilizada na estatística e na econometria, especialmente em análise de regressão e para comparar diferenças entre grupos de observações (renda de homens e mulheres, por exemplo).
Uma tabela de dados de corte transversal, em linhas gerais, possui um formato parecido com esse abaixo:
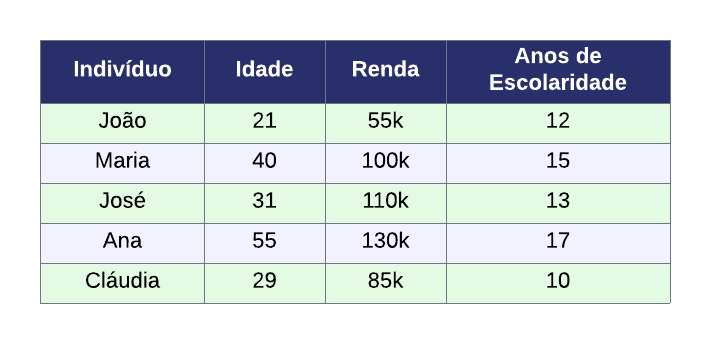
A tabela geralmente possui uma coluna identificando a observação (sejam pessoas, empresas, países, etc.) e outras colunas descrevendo características da observação (por exemplo, idade, renda, escolaridade, etc.). A informação sobre o período de coleta dos dados é única para todas as observações, portanto não consta na tabela.
Alguns exemplos de conjuntos de dados (datasets) públicos com estrutura de corte transversal no Brasil são:
- PNAD Contínua: Pesquisa Nacional por Amostra de Domicílios Contínua, realizada pelo IBGE, com informações sobre mercado de trabalho, renda, educação, saúde e outras características dos domicílios e da população brasileira.
- Censo Demográfico: realizado pelo IBGE a cada 10 anos, é uma pesquisa que tem como objetivo fornecer informações sobre a população brasileira, como idade, sexo, raça, escolaridade, entre outras.
- Censo Escolar: realizado anualmente pelo Instituto Nacional de Estudos e Pesquisas Educacionais Anísio Teixeira (INEP), contém informações sobre as escolas, turmas, alunos e profissionais da educação básica no país.
- Relação Anual de Informações Sociais (RAIS): elaborada pelo Ministério do Trabalho e Emprego, contém informações sobre os empregadores e os trabalhadores formais do país, como número de empregados, salários, setor de atividade, entre outras.
- Sistema de Informações sobre Mortalidade (SIM): mantido pelo Ministério da Saúde, contém informações sobre as causas de morte no país, incluindo dados demográficos dos falecidos e características dos óbitos.
Como usar dados de corte transversal no R e no Python?
As linguagens de programação R e Python possuem estruturas de dados e bibliotecas propícias para o manejo e análise de dados do tipo corte transversal. Desde as etapas de coleta de dados, até os procedimentos de tratamento, análise e visualização de dados, existem diversos pacotes úteis para auxiliar em cada procedimento.
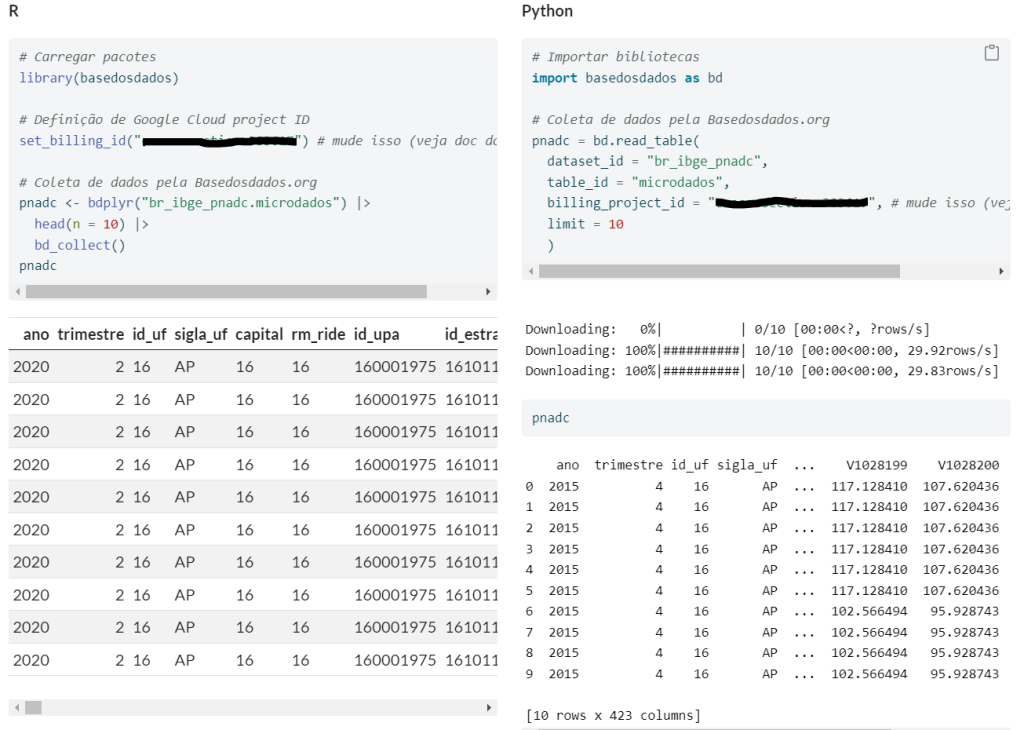
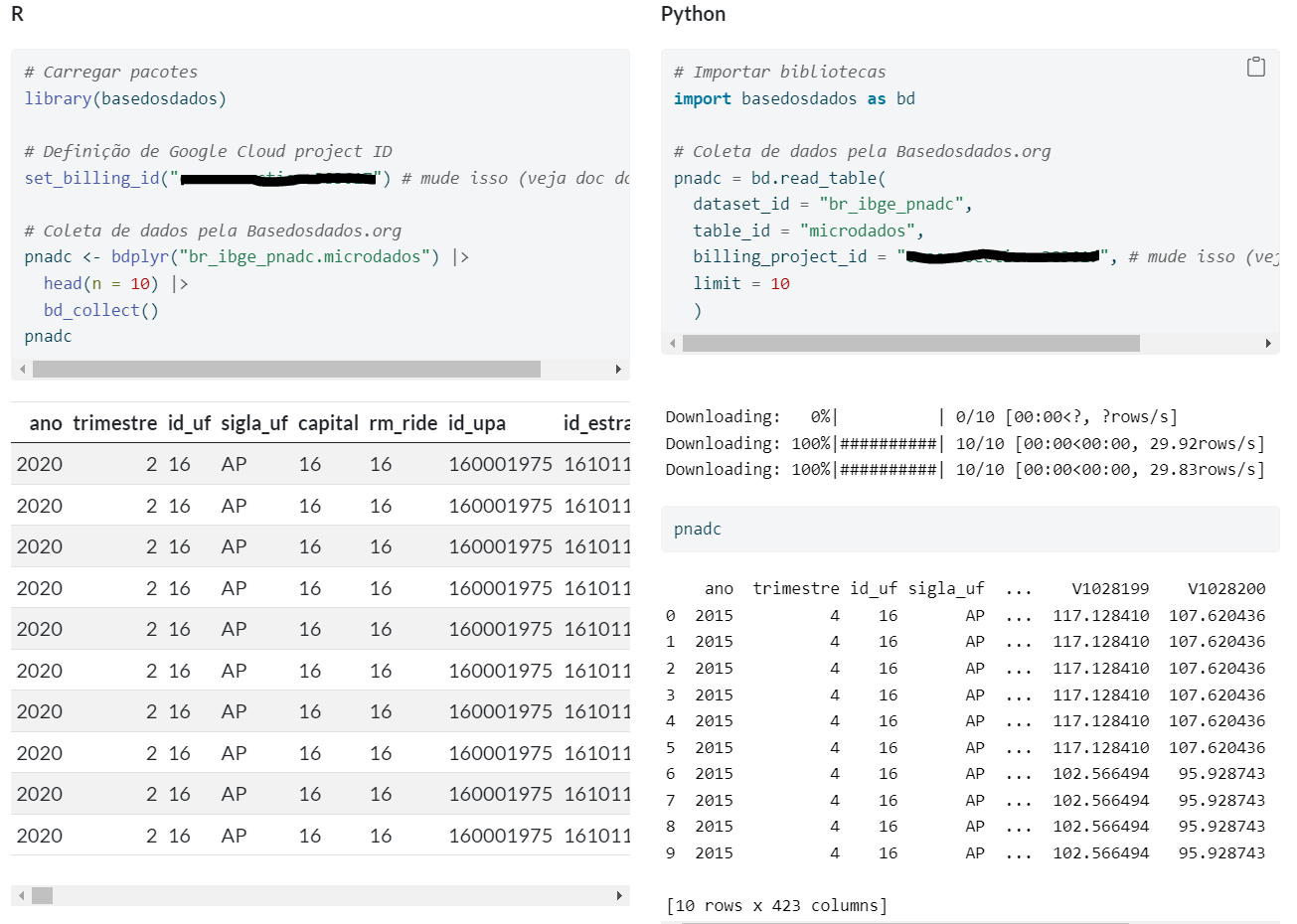
Abaixo está um exemplo de uma tabela de dados de corte transversal, com base na pesquisa PNAD Contínua, coletada pelo R e/ou Python (para saber mais confira o curso de Microdados da Análise Macro):
O que são dados de séries temporais (time series)?
Os dados de séries temporais (time series, no inglês) são estruturas de dados tabulares compostos de observações indexadas no tempo, frequentemente constituindo observações sequenciais e igualmente espaçadas entre períodos diferentes. É uma estrutura de dados muito utilizada em diversas áreas como estatística, econometria, clima, finanças, macroeconomia e outras. A análise e a previsão de séries temporais são as aplicações mais comuns com essa estrutura de dados.
Uma tabela de dados com séries temporais, em linhas gerais, possui um formato parecido com esse abaixo:
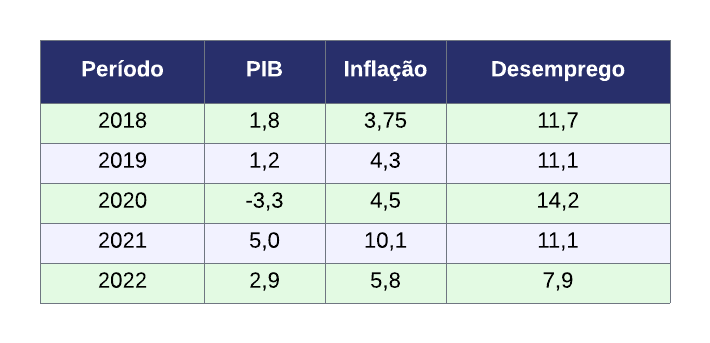
A tabela geralmente possui uma coluna indexando a observação em algum ponto no tempo (dia, semana, mês, ano, etc.) e outras colunas com os valores da série temporal.
Alguns exemplos de conjuntos de dados (datasets) públicos com estrutura de série temporal no Brasil são:
- Índice Bovespa (IBOVESPA): O Ibovespa é um índice de ações da bolsa de valores de São Paulo, que reflete o desempenho das principais empresas listadas na B3. Os dados do Ibovespa podem ser baixados no site da própria B3.
- Índice Nacional de Preços ao Consumidor Amplo (IPCA): O IPCA é o índice oficial de inflação do país, medido pelo Instituto Brasileiro de Geografia e Estatística (IBGE). Os dados do IPCA estão disponíveis no site do IBGE.
- Taxa Selic: A taxa Selic é a taxa básica de juros da economia brasileira, definida pelo Banco Central do Brasil. Os dados da taxa Selic podem ser acessados no site do Banco Central.
- Taxa de câmbio (dólar): A taxa de câmbio representa o valor da moeda brasileira em relação ao dólar americano. Os dados da taxa de câmbio podem ser encontrados no site do Banco Central.
- Produto Interno Bruto (PIB): O PIB é a soma de todos os bens e serviços produzidos em um país durante um período de tempo. Os dados do PIB estão disponíveis no site do IBGE.
Como usar dados de séries temporais no R e no Python?
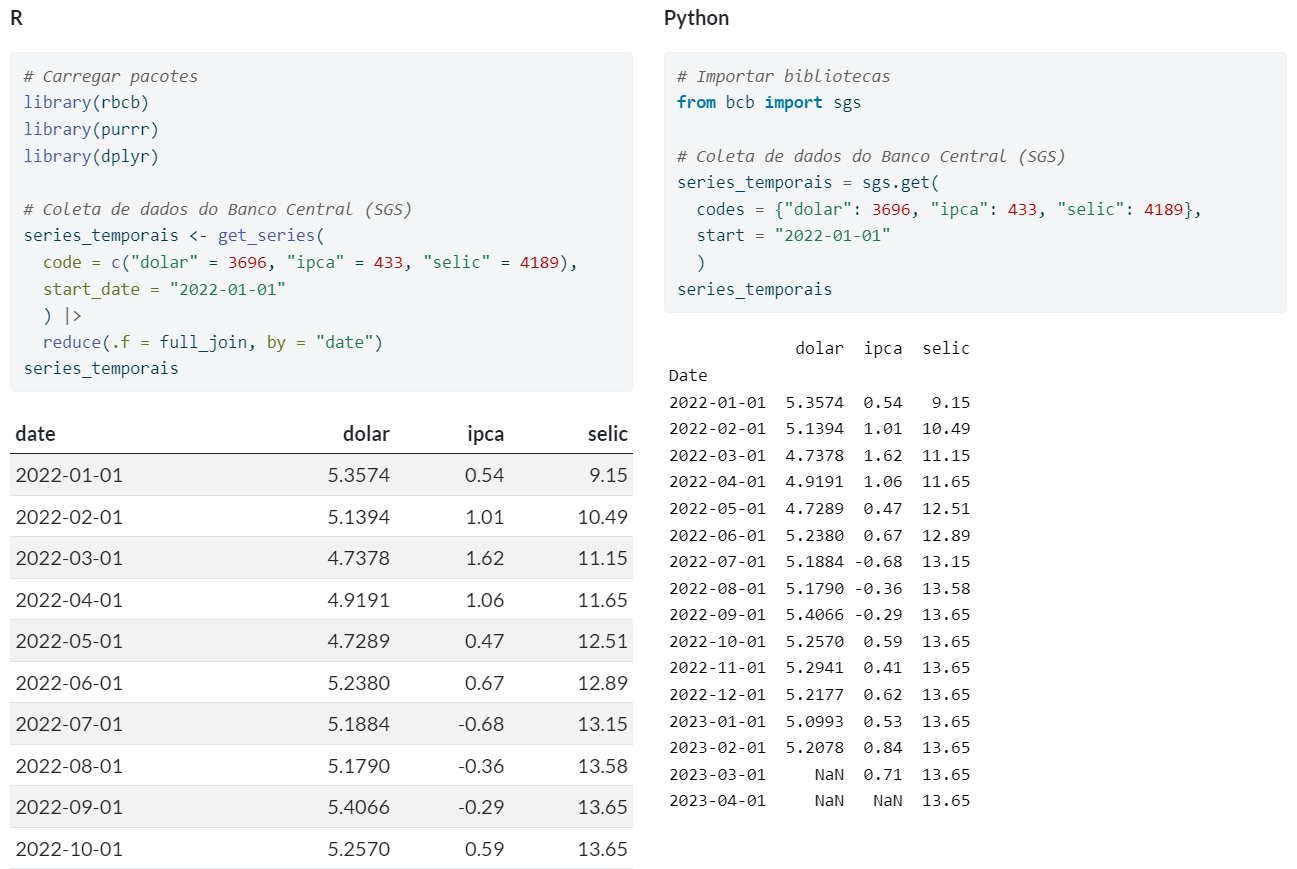
As linguagens de programação R e Python possuem estruturas de dados e bibliotecas propícias para o manejo e análise de dados do tipo série temporal. Desde as etapas de coleta de dados, até os procedimentos de tratamento, análise e visualização de dados, existem diversos pacotes úteis para auxiliar em cada procedimento.
Abaixo está um exemplo de uma tabela de dados de séries temporais, com base nos conjuntos de dados do Banco Central, coletada pelo R e/ou Python (para saber mais confira o curso de Análise de Conjuntura:
Conclusão
Com o aumento da disponibilidade de dados, torna-se fundamental conhecer técnicas e métodos para analisá-los e utilizá-los de forma estratégica. Nesse contexto, é importante compreender como os dados são estruturados e quais ferramentas podem ser usadas para trabalhar com eles. As estruturas de dados de corte transversal são amostras de dados de diversas observações em um único período de tempo. Já as séries temporais são conjuntos sequências de dados indexados no tempo. Esses dados são importantes em diversas áreas, como estatística e econometria, permitindo comparar observações e analisar características conforte a estrutura do dado. As linguagens de programação R e Python são excelentes ferramentas para manipulação e análise desses dados, oferecendo uma grande variedade de bibliotecas para auxiliar em todas as etapas do processo.
Saiba mais
Se você se interessa por análise e ciência de dados e quiser adquirir os conhecimentos e habilidades destacados neste artigo, dê uma olhadinha nessa formação especial que a Análise Macro preparou:

