Prophet é um modelo de previsão desenvolvido pelo Facebook em 2017 que promete entregar previsões em escala. É ideal para séries temporais com forte sazonalidade e com muitas observações de dados. Ele é baseado em um modelo aditivo ajustado com tendências não lineares, sazonalidades e efeitos de feriado, além de ser robusto a valores ausentes, mudanças de tendência e valores extremos.
Nesse artigo apresentamos o modelo Prophet, através da decomposição das equações e parâmetros, e mostramos um exemplo aplicado com dados para previsão de demanda usando as linguagens de programação R e Python.
Para aprender mais e ter acesso a códigos confira o curso de Modelagem e Previsão usando Python ou comece do zero em análise de dados com a formação Do Zero à Análise de Dados com Python.
Modelo de previsão Prophet
O Prophet foi desenhado pela equipe do Facebook para solucionar os seguintes problemas em um contexto de tarefas de previsão de séries temporais em ambiente empresarial, conforme Taylor e Letham (2017):
- Um grande número de pessoas produzindo previsões, possivelmente sem treinamento técnico aprofundado;
- Um grande número de tarefas de previsão, possivelmente com particularidades únicas;
- Uma demanda por um sistema de previsão automatizado, veloz, eficiente.
Existem muitas séries temporais em ambiente empresarial para as quais é necessário produzir previsão, ao mesmo tempo que é preciso superar os problemas destacados acima. Felizmente, existem algumas características em comum para grande parte dessas séries temporais.
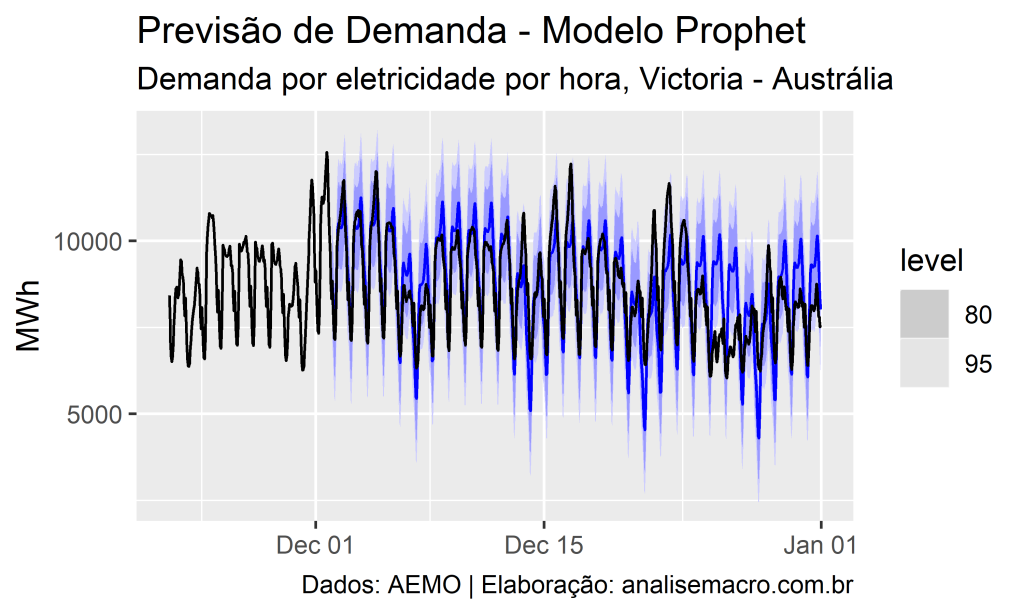
Por exemplo, veja esses dados de demanda por eletricidade por hora na cidade de Victoria na Austrália (fonte Australian Energy Market Operator):

Essa série temporal mostra claramente algumas características:
- Ciclos sazonais anuais e horários
- Aumentos repentinos em grandes feriados (final de ano)
- Valores extremos
Para lidar com essas características comuns em séries temporais o Prophet utiliza um modelo de decomposição, da seguinte forma:
![\[y_t = T_t + S_t + F_t + \epsilon_t\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-7f7a684094d41498a7068f4c5633fbd6_l3.png "Rendered by QuickLaTeX.com")
onde:
 é a série temporal alvo de previsão;
é a série temporal alvo de previsão;
 é o componente de tendência que modela variações não periódicas de ;
é o componente de tendência que modela variações não periódicas de ;
 é o componente de sazonalidade que modela variações periódicas de ;
é o componente de sazonalidade que modela variações periódicas de ;
 é a representação de efeitos de feriados e eventos sobre ;
é a representação de efeitos de feriados e eventos sobre ;
 é o termo de erro que representa variações idiossincráticas, assumido como normalmente distribuído.
é o termo de erro que representa variações idiossincráticas, assumido como normalmente distribuído.
A seguir descrevemos o procedimento de modelagem de cada componente no modelo Prophet.
Componente de tendência
O componente de tendência do modelo Prophet pode ser representado de duas formas:
- Tendência com crescimento não linear e saturanteA ideia é que a tendência possui um crescimento não linear que "satura" uma capacidade de carga. Por exemplo, a capacidade de carga da demanda por eletricidade de uma cidade pode ser o número de dispositivos que consomem eletricidade. Esse tipo de crescimento no Prophet é dado por uma função de crescimento logístico por partes, permitindo pontos de
![\[T_t = \frac{C_{t}}{1 + \exp(-(k + a_t^T\delta)(t - (m + a_t^T\gamma)))}\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-3874f5d174c298697ca8ba2b03ea98ca_l3.png "Rendered by QuickLaTeX.com")
onde:
 é a capacidade de carga variante no tempo;
é a capacidade de carga variante no tempo;
 é uma taxa básica de crescimento da tendência;
é uma taxa básica de crescimento da tendência;
 é uma taxa de ajuste da taxa básica de crescimento, sendo
é uma taxa de ajuste da taxa básica de crescimento, sendo  igual a 1 se
igual a 1 se  for maior ou igual ao
for maior ou igual ao  ponto de mudança e igual a zero caso contrário;
ponto de mudança e igual a zero caso contrário;
 é a mudança da taxa de ajuste que ocorre no ponto de mudança;
é a mudança da taxa de ajuste que ocorre no ponto de mudança;
 é um parâmetro de deslocamento;
é um parâmetro de deslocamento;
 é a correção do ajuste no ponto de mudança.
é a correção do ajuste no ponto de mudança.
Os pontos de mudança podem ser definidos a priori utilizando datas conhecidas sobre a série temporal ou podem ser automaticamente selecionados.
- Tendência com crescimento linear com pontos de mudançaA ideia dessa versão do componente de tendência é quando a série temporal não possui comportamento "saturante" da capacidade de carga, portanto uma taxa constante de crescimento é aplicável:
![\[T_t = (k + a_t^T\delta)t + (m + a_t^T\gamma)\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-5d51fc407f11dd194bf64535bef2bcb2_l3.png "Rendered by QuickLaTeX.com")
Componente de sazonalidade
O componente de sazonalidade do modelo Prophet é representado da seguinte forma:
![\[S_{t} = \sum_{n=1}^N \left (a_{n} \cos \left ( \frac{2 \pi n t}{P} \right ) + b_n \sin \left (\frac{2 \pi n t}{P} \right) \right )\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-5866fa165b53ce3f22e3bfa35d6e9d6f_l3.png "Rendered by QuickLaTeX.com")
onde:
 e
e  são os parâmetros sazonais a serem estimados, assumidos como normalmente distribuídos;
são os parâmetros sazonais a serem estimados, assumidos como normalmente distribuídos;
 é a periodicidade regular da série (i.e.,
é a periodicidade regular da série (i.e.,  para séries semanais).
para séries semanais).
A ideia por trás desse componente é que a série temporal pode ter múltiplas sazonalidades, como resultado do comportamento humano. Por exemplo, uma jornada de trabalho de 5 dias por semana pode produzir efeitos em uma série temporal que se repetem semanalmente, enquanto que férias escolares e outros podem produzir efeitos que se repetem anualmente.
Componente de feriados e eventos
Feriados e eventos podem produzir um grande efeito sobre uma série temporal sem um padrão periódico. Por exemplo, o evento Rock in Rio acontece na cidade do Rio de Janeiro a cada 2 anos aproximadamente. Já a Páscoa ocorre no primeiro domingo depois da lua cheia após o início do equinócio de verão. Os efeitos destes feriados e eventos nas séries temporais costumam ser similares ano após ano, dessa forma é importante incorporá-los no modelo de previsão.
No modelo Prophet, os efeitos de feriados e eventos são incorporados adicionando uma matriz  de variáveis independentes que assumem o valor 1 se a observação no tempo é durante o feriado/evento e multiplicando por um parâmetro
de variáveis independentes que assumem o valor 1 se a observação no tempo é durante o feriado/evento e multiplicando por um parâmetro  para representar a mudança na previsão. Dessa forma, temos que:
para representar a mudança na previsão. Dessa forma, temos que:
![\[F_{t} = Z_{t} \kappa\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-3da21621c5177796d1257b1816da5e86_l3.png "Rendered by QuickLaTeX.com")
onde:
é assumido como normalmente distribuído.
O modelo é estimado usando a máxima probabilidade a posteriori (MAP), da estatística bayesiana, através da linguagem Stan.
Exemplo aplicado do modelo Prophet: previsão de demanda
Agora vamos mostrar como utilizar o modelo Prophet para previsão, usando como exemplo os dados exibidos acima da demanda por eletricidade por hora na cidade de Victoria na Austrália (fonte Australian Energy Market Operator).
Abaixo reportamos (a) as métricas de acurácia de treino/teste e (b) o gráfico de valores observados e previsão fora da amostra.
Python
Código
12:26:17 - cmdstanpy - INFO - Chain [1] start processing
12:26:33 - cmdstanpy - INFO - Chain [1] done processing
RMSE de treino: 940.9689553290613
RMSE de teste: 913.6017458369588
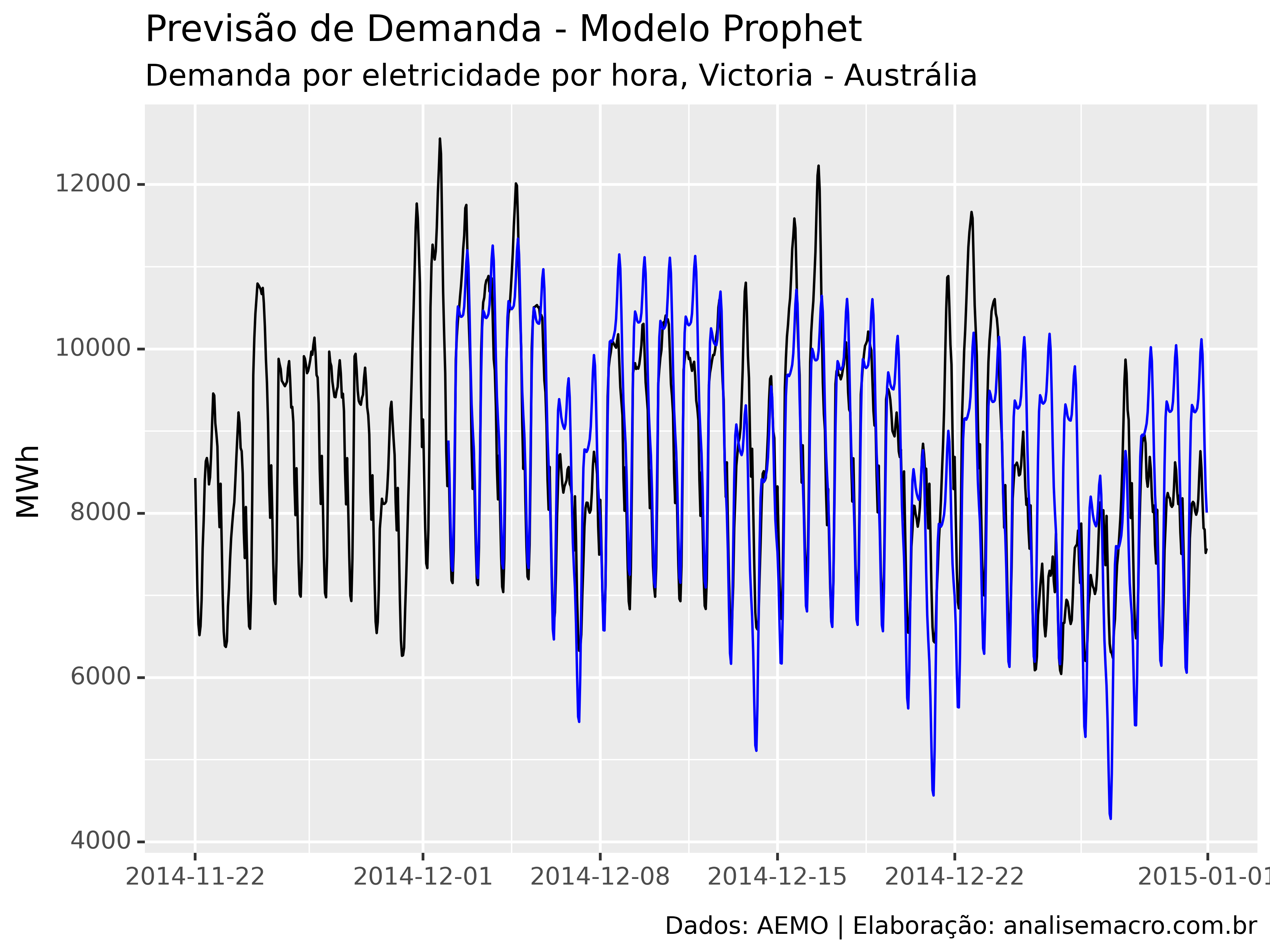
Note que o modelo gera previsões que estão, analisando apenas os resultados acima, se generalizando bem.
A linha preta no gráfico mostra os dados observados, enquanto que a linha azul mostra a previsão fora da amostra.
Note que avaliar pontos de previsão sem levar em consideração o intervalo de confiança pode esconder uma grande incerteza e levar a conclusões errôneas.
Conclusão
Nesse artigo apresentamos o modelo Prophet, através da decomposição das equações e parâmetros, e mostramos um exemplo aplicado com dados para previsão de demanda usando as linguagens de programação R e Python.
Referências
Taylor SJ, Letham B. 2017. Forecasting at scale. PeerJ Preprints 5:e3190v2 https://doi.org/10.7287/peerj.preprints.3190v2
Quer aprender mais?
- Cadastre-se gratuitamente aqui no Boletim AM e receba toda terça-feira pela manhã nossa newsletter com um compilado dos nossos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas;
- Quer ter acesso aos códigos, vídeos e scripts de R/Python desse exercício? Vire membro do Clube AM aqui e tenha acesso à nossa Comunidade de Análise de Dados;
- Quer aprender a programar em R ou Python com Cursos Aplicados e diretos ao ponto em Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas? Veja nossos Cursos aqui.

