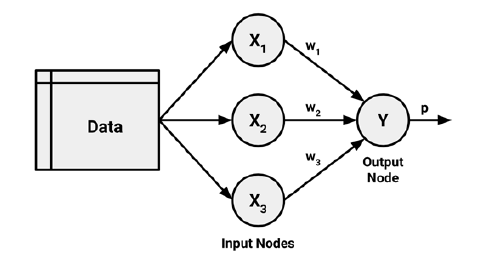
Uma rede neural artificial (ANN, do inglês) modela a relação entre um conjunto de inputs e um output utilizando para isso um modelo derivado do nosso entendimento sobre como um cérebro biológico responde aos estímulos de inputs sensoriais. Tal como o cérebro utiliza uma rede de células interconectadas designadas como neurônios de modo a criar um processador paralelo maciço, uma ANN utiliza uma rede de nós de modo a resolver problemas de aprendizado.1

A figura acima mostra a versão de uma rede neural baseada em uma regressão linear com quatro preditores. Os coeficientes anexados aos preditores são chamados de pesos. As previsões são então obtidas como uma combinação linear dos inputs.
Aprenda mais e tenha acesso aos códigos desse e outros modelos de previsão e classificação usando Estatística, Econometria e Machine Learning através do curso de Modelagem e Previsão usando Python da Análise Macro.
Os pesos são selecionados a partir de um algoritmo de aprendizado que minimiza uma função custo como o Erro Quadrático Médio (EQM).
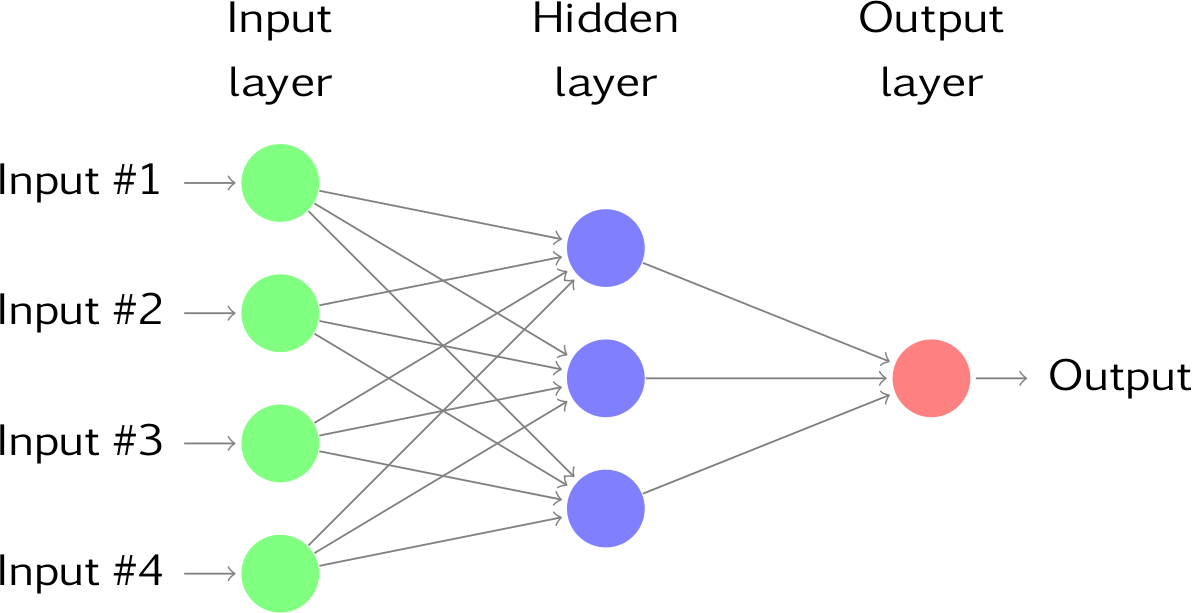
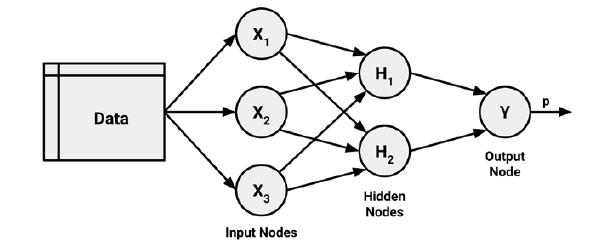
Ao adicionarmos uma camada (layer) intermediária com neurônios ocultos, a nossa rede neural se torna não linear como no exemplo acima. Ela é conhecida como rede neural feed-forward multicamadas, onde cada camada de nós recebe inputs da camada anterior.
Os outputs dos nós em uma camada serão então inputs na próxima camada. Os inputs em cada nó serão combinados usando uma combinação linear ponderada. O resultado é então modificado por uma função não-linear antes de ser transformado em output.
Por exemplo, os inputs no neurônio oculto  da figura acima são linearmente combinados de modo a dar
da figura acima são linearmente combinados de modo a dar
![\[z_j = b_j + \sum_{i=1}^{4} w_{i,j} x_i. \nonumber\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-ab39a73e45378b5731f3cce50e79014d_l3.png "Rendered by QuickLaTeX.com")
No camada oculta, isso é então modificado usando uma função não-linear tão qual
![\[s(z) = \frac{1}{1 + e^{-z}},\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-59584d0917ef092e269c60a9a52cce97_l3.png "Rendered by QuickLaTeX.com")
de modo a gerar o input para a próxima camada.
Isso tende a reduzir o efeito de valores extremos, fazendo com que a rede seja robusta a outliers.
Os parâmetros  e
e  são aprendidos dos dados. Os valores dos pesos são em geral restritos de modo a prevenir que os mesmos se tornem muito grandes.
são aprendidos dos dados. Os valores dos pesos são em geral restritos de modo a prevenir que os mesmos se tornem muito grandes.
O parâmetro que restringe os pesos é chamado de parâmetros de decaimento e é comum ser setado como 0.1.
Os pesos tomam então valores aleatórios, sendo atualizados a partir dos dados observados. Consequentemente, existe um elemento de aleatoriedade nas previsões produzidas por uma rede neural. Por isso, uma rede é em geral treinada diversas vezes usando diferentes pontos de partida aleatórios, de modo a produzir um resultado médio.
Características das Redes Neurais
Embora exista inúmeras variantes de redes neurais, cada uma pode ser definida com base nas seguintes características:
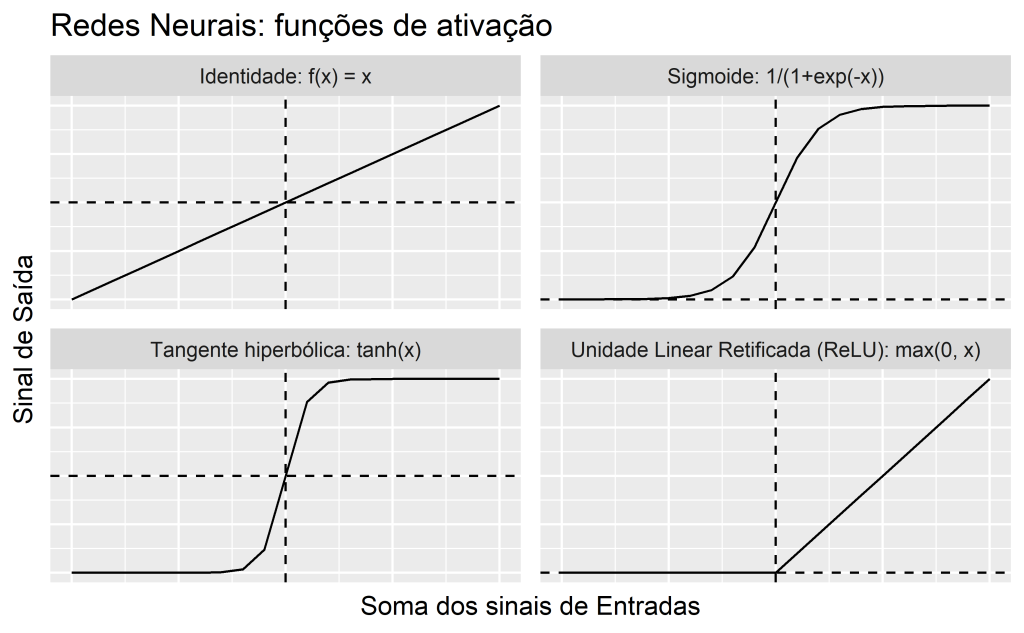
- Função de Ativação: é a função que transforma a combinação de inputs em um único output que será então transmitido para frente na rede;
- Topologia de rede: irá descrever o número de neurônios e camadas no modelo, bem como o modo como eles estarão conectados;
- Algoritmo de Treino: irá especificar como os pesos serão criados de modo a lidar com os inputs associados na rede.
Função de Ativação
A função de ativação é o mecanismo pelo qual a rede neural processa a informação que entra e a passa para frente na rede.
Uma função de ativação será escolhida de acordo com sua habilidade de demonstrar características matemáticas desejáveis e acurácia na relação com os dados.
Topologia de Rede
A habilidade da rede neural em aprender está intimamente ligada à sua topologia. Uma topologia de rede possui as seguintes características chaves:
- O número de camadas;
- O quanto de informação na rede é repassada para trás;
- O número de nós em cada camada da rede.
A topologia de rede irá determinar a complexidade das tarefas que podem ser aprendidas na rede.
De modo a definir a topologia, nós precisamos de uma terminologia que distinga os nós de acordo com a sua posição na rede.
A direção da informação
Nos exemplos que vimos até aqui, a informação viaja sempre para frente. Isto é, são redes onde o sinal dos inputs será levado, conexão a conexão, até a camada de saída. São redes feedforwards.
A despeito dessa restrição no fluxo de informação, redes feedforwards são bastante flexíveis, podendo conter diversos tipos de arquitetura.2
Backpropagation
A topologia de rede é uma tela em branco que por si só não aprende nada. Conforme a rede processa os dados de entrada, as conexões entre os nós podem ser fortes ou fracas, similarmente ao aprendizado de uma criança. Os pesos, por sua vez, serão ajustados de modo a refletir os padrões observados a cada ponto do tempo.
Isso, entretanto, irá requerer bastante poder computacional. Por esse motivo, redes neurais eram pouco utilizadas na prática até meados dos anos 80, quando um eficiente algoritmo de treino chamado de backpropagation (retropropagação do erro) foi descoberto.
O algoritmo de retropropagação itera através de muitos ciclos de dois processos. Cada ciclo é conhecido como uma época. Dado que a rede não contém informação prévia, os pesos iniciais são setados de forma aleatória. A partir disso, o algoritmo itera pelo processo, até que um critério de parada é acionado. Cada época inclui:
- Uma fase forward: de modo que os neurônios são ativados do input para o output, aplicando cada peso e função de ativação ao longo do caminho. Ao atingir a camada final, um sinal de saída é produzido.
- Uma fase backward: aqui o sinal de saída produzido na fase forward é comparado com o valor do target nos dados de treino. A diferença entre eles resulta em um erro que é propagado para trás na rede de modo a modificar os pesos e reduzir futuros erros.
Exemplo de Redes Neurais: previsão de inadimplência
Nesta seção apresentamos um exemplo do modelo de Redes Neurais Artificiais.
O problema que utilizaremos para exemplificar é o seguinte:
- Deseja-se definir se um empréstimo será totalmente pago, classificando como adimplente (bom/good) ou inadimplente (ruim/bad).
Os dados utilizados para abordar esse problema são os seguintes:
- Conjunto de dados Lending Club Loan Data disponibilizado neste link, contendo uma amostra de dados referente ao primeiro trimestre de 2016.
- Um dicionário sobre as variáveis pode ser conferido neste link.
Não houve nenhum pré-processamento nos dados.
Aprenda mais e tenha acesso aos códigos desse e outros modelos de previsão e classificação usando Estatística, Econometria e Machine Learning através do curso de Modelagem e Previsão usando Python da Análise Macro.
Uma pequena análise exploratória é exibida abaixo:
┌────────────────────────────── skimpy summary ───────────────────────────────┐
│ Data Summary Data Types │
│ ┌───────────────────┬────────┐ ┌─────────────┬───────┐ │
│ │ dataframe │ Values │ │ Column Type │ Count │ │
│ ├───────────────────┼────────┤ ├─────────────┼───────┤ │
│ │ Number of rows │ 9857 │ │ int32 │ 14 │ │
│ │ Number of columns │ 23 │ │ string │ 6 │ │
│ └───────────────────┴────────┘ │ float64 │ 3 │ │
│ └─────────────┴───────┘ │
│ number │
│ ┌──────┬────┬──────┬──────┬──────┬──────┬──────┬──────┬─────┬──────┬─────┐ │
│ │ colu │ │ │ │ │ │ │ │ │ │ │ │
│ │ mn_n │ │ │ │ │ │ │ │ │ │ his │ │
│ │ ame │ NA │ NA % │ mean │ sd │ p0 │ p25 │ p50 │ p75 │ p100 │ t │ │
│ ├──────┼────┼──────┼──────┼──────┼──────┼──────┼──────┼─────┼──────┼─────┤ │
│ │ fund │ 0 │ 0 │ 1600 │ 8900 │ 1000 │ 8500 │ 1500 │ 210 │ 4000 │ ▆▇▇ │ │
│ │ ed_a │ │ │ 0 │ │ │ │ 0 │ 00 │ 0 │ ▃▂▂ │ │
│ │ mnt │ │ │ │ │ │ │ │ │ │ │ │
│ │ int_ │ 0 │ 0 │ 13 │ 4.9 │ 5.3 │ 8.5 │ 12 │ 15 │ 29 │ ▇▇▅ │ │
│ │ rate │ │ │ │ │ │ │ │ │ │ ▃▁ │ │
│ │ annu │ 0 │ 0 │ 8000 │ 5300 │ 0 │ 5000 │ 6900 │ 960 │ 9600 │ ▇ │ │
│ │ al_i │ │ │ 0 │ 0 │ │ 0 │ 0 │ 00 │ 00 │ │ │
│ │ nc │ │ │ │ │ │ │ │ │ │ │ │
│ │ deli │ 0 │ 0 │ 0.33 │ 0.89 │ 0 │ 0 │ 0 │ 0 │ 22 │ ▇ │ │
│ │ nq_2 │ │ │ │ │ │ │ │ │ │ │ │
│ │ yrs │ │ │ │ │ │ │ │ │ │ │ │
│ │ inq_ │ 0 │ 0 │ 0.58 │ 0.88 │ 0 │ 0 │ 0 │ 1 │ 5 │ ▇▃▁ │ │
│ │ last │ │ │ │ │ │ │ │ │ │ │ │
│ │ _6mt │ │ │ │ │ │ │ │ │ │ │ │
│ │ hs │ │ │ │ │ │ │ │ │ │ │ │
│ │ revo │ 0 │ 0 │ 52 │ 24 │ 0 │ 33 │ 52 │ 70 │ 140 │ ▃▇▇ │ │
│ │ l_ut │ │ │ │ │ │ │ │ │ │ ▅▁ │ │
│ │ il │ │ │ │ │ │ │ │ │ │ │ │
│ │ acc_ │ 0 │ 0 │ 0.00 │ 0.08 │ 0 │ 0 │ 0 │ 0 │ 2 │ ▇ │ │
│ │ now_ │ │ │ 63 │ 3 │ │ │ │ │ │ │ │
│ │ deli │ │ │ │ │ │ │ │ │ │ │ │
│ │ nq │ │ │ │ │ │ │ │ │ │ │ │
│ │ open │ 0 │ 0 │ 2.8 │ 2.9 │ 0 │ 1 │ 2 │ 3 │ 32 │ ▇▁ │ │
│ │ _il_ │ │ │ │ │ │ │ │ │ │ │ │
│ │ 6m │ │ │ │ │ │ │ │ │ │ │ │
│ │ open │ 0 │ 0 │ 0.74 │ 1 │ 0 │ 0 │ 0 │ 1 │ 20 │ ▇ │ │
│ │ _il_ │ │ │ │ │ │ │ │ │ │ │ │
│ │ 12m │ │ │ │ │ │ │ │ │ │ │ │
│ │ open │ 0 │ 0 │ 1.6 │ 1.7 │ 0 │ 0 │ 1 │ 2 │ 30 │ ▇ │ │
│ │ _il_ │ │ │ │ │ │ │ │ │ │ │ │
│ │ 24m │ │ │ │ │ │ │ │ │ │ │ │
│ │ tota │ 0 │ 0 │ 3500 │ 4200 │ 0 │ 9400 │ 2400 │ 460 │ 5900 │ ▇ │ │
│ │ l_ba │ │ │ 0 │ 0 │ │ │ 0 │ 00 │ 00 │ │ │
│ │ l_il │ │ │ │ │ │ │ │ │ │ │ │
│ │ all_ │ 0 │ 0 │ 60 │ 20 │ 0 │ 47 │ 62 │ 75 │ 200 │ ▂▇▇ │ │
│ │ util │ │ │ │ │ │ │ │ │ │ │ │
│ │ inq_ │ 0 │ 0 │ 0.93 │ 1.5 │ 0 │ 0 │ 0 │ 1 │ 15 │ ▇▁ │ │
│ │ fi │ │ │ │ │ │ │ │ │ │ │ │
│ │ inq_ │ 0 │ 0 │ 2.2 │ 2.4 │ 0 │ 0 │ 2 │ 3 │ 32 │ ▇▁ │ │
│ │ last │ │ │ │ │ │ │ │ │ │ │ │
│ │ _12m │ │ │ │ │ │ │ │ │ │ │ │
│ │ deli │ 0 │ 0 │ 12 │ 570 │ 0 │ 0 │ 0 │ 0 │ 4200 │ ▇ │ │
│ │ nq_a │ │ │ │ │ │ │ │ │ 0 │ │ │
│ │ mnt │ │ │ │ │ │ │ │ │ │ │ │
│ │ num_ │ 0 │ 0 │ 8.6 │ 7.5 │ 0 │ 4 │ 7 │ 11 │ 82 │ ▇▂ │ │
│ │ il_t │ │ │ │ │ │ │ │ │ │ │ │
│ │ l │ │ │ │ │ │ │ │ │ │ │ │
│ │ tota │ 0 │ 0 │ 4500 │ 4500 │ 0 │ 1600 │ 3400 │ 610 │ 5500 │ ▇▁ │ │
│ │ l_il │ │ │ 0 │ 0 │ │ 0 │ 0 │ 00 │ 00 │ │ │
│ │ _hig │ │ │ │ │ │ │ │ │ │ │ │
│ │ h_cr │ │ │ │ │ │ │ │ │ │ │ │
│ │ edit │ │ │ │ │ │ │ │ │ │ │ │
│ │ _lim │ │ │ │ │ │ │ │ │ │ │ │
│ │ it │ │ │ │ │ │ │ │ │ │ │ │
│ └──────┴────┴──────┴──────┴──────┴──────┴──────┴──────┴─────┴──────┴─────┘ │
│ string │
│ ┌─────────────────────────┬─────┬───────┬─────────────────┬──────────────┐ │
│ │ column_name │ NA │ NA % │ words per row │ total words │ │
│ ├─────────────────────────┼─────┼───────┼─────────────────┼──────────────┤ │
│ │ term │ 0 │ 0 │ 1 │ 9857 │ │
│ │ sub_grade │ 0 │ 0 │ 1 │ 9857 │ │
│ │ addr_state │ 0 │ 0 │ 1 │ 9857 │ │
│ │ verification_status │ 0 │ 0 │ 1 │ 9857 │ │
│ │ emp_length │ 0 │ 0 │ 1 │ 9857 │ │
│ │ Class │ 0 │ 0 │ 1 │ 9857 │ │
│ └─────────────────────────┴─────┴───────┴─────────────────┴──────────────┘ │
└──────────────────────────────────── End ────────────────────────────────────┘As classificações produzidas pelo algoritmo são exibidas abaixo:
array(['good', 'good', 'good', ..., 'good', 'good', 'good'], dtype='<U4')Por fim reportamos algumas medidas de acurácia:
array([[ 0, 155], [ 0, 2803]], dtype=int64)
0.9475997295469912Conclusão
Neste artigo introduzimos a base de muitas aplicações de inteligência artificial: o modelo de Redes Neurais. Mostramos a intuição, sua formulação matemática e uma aplicação com dados de empréstimo bancário usando R e Python.
Quer aprender mais?
Clique aqui para fazer seu cadastro no Boletim AM e baixar o código que produziu este exercício, além de receber novos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas diretamente em seu e-mail.
Referências
Brett Lantz. Machine Learning with R. Packt Publishing, 2013.
R. Hyndman and G. Athanasopoulos. Forecasting principles and practice. 1rd edition. OTexts, 2019.

