(1) 
onde, para cada  é uma variável aleatória no espaço amostral
é uma variável aleatória no espaço amostral  , e a realização desse processo estocástico é dada por
, e a realização desse processo estocástico é dada por  para cada
para cada  com respeito a um ponto no tempo
com respeito a um ponto no tempo  .
.
(2) 
Cada  em
em  é, desse modo, apenas um valor possível de uma variável aleatória. Uma variável aleatória, por seu turno, é aquela que assume valores numéricos e tem um resultado que é determinado por um experimento.
é, desse modo, apenas um valor possível de uma variável aleatória. Uma variável aleatória, por seu turno, é aquela que assume valores numéricos e tem um resultado que é determinado por um experimento.
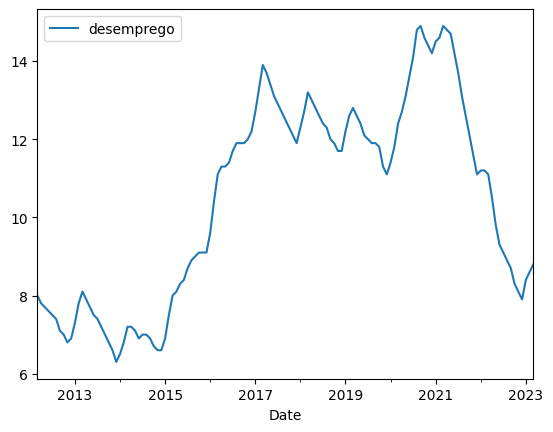
O desafio do econometrista será, portanto, tendo acesso apenas à série temporal, buscar compreender esse processo estocástico desconhecido. Quanto melhor for essa compreensão, melhor será a modelagem e, com efeito, a previsão de observações futuras.
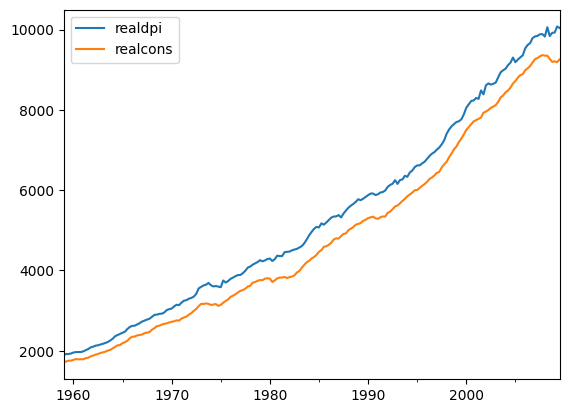
Tomemos duas séries contidas nesse dataset: realcons, Despesas reais de consumo pessoal e realdpi, Rendimento disponível privado real.
(3) 
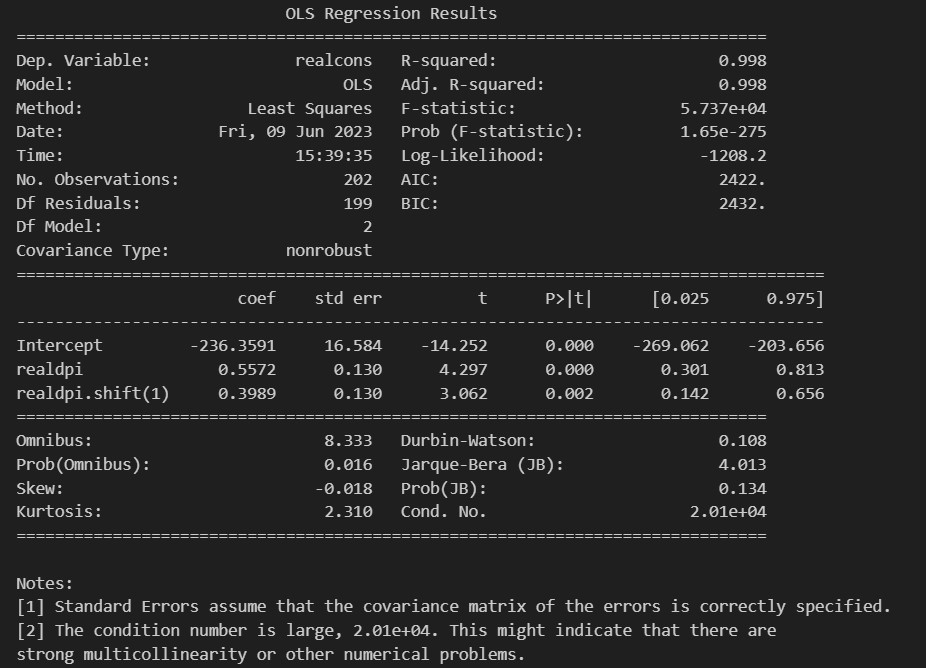
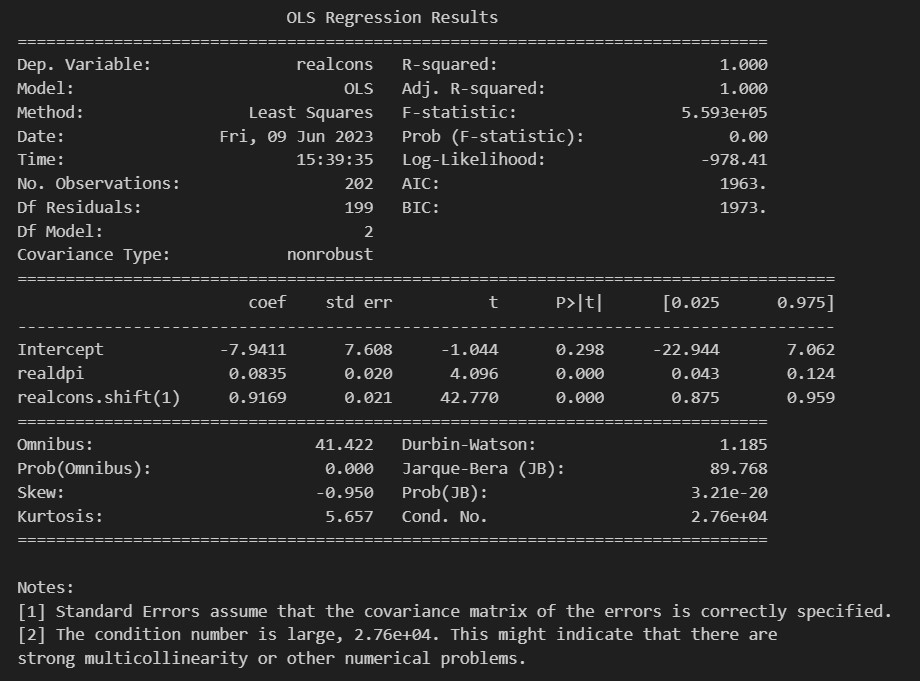
Que além dos resultados da estimação de ambas as especificações, é possível visualizar os valores ajustados e os resíduos, como nos gráficos abaixo.
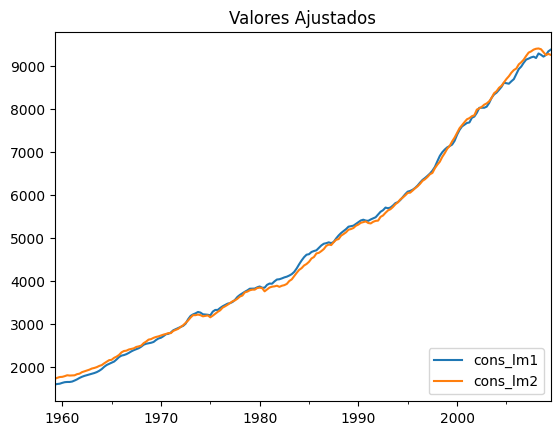 Enquanto cons_lm1 representa a primeira equação, cons_lm2 representa a segunda. Vemos que ambas possuem um resultado muito próximo, com apenas alguns desvios em diferentes pontos do tempo.
Enquanto cons_lm1 representa a primeira equação, cons_lm2 representa a segunda. Vemos que ambas possuem um resultado muito próximo, com apenas alguns desvios em diferentes pontos do tempo.
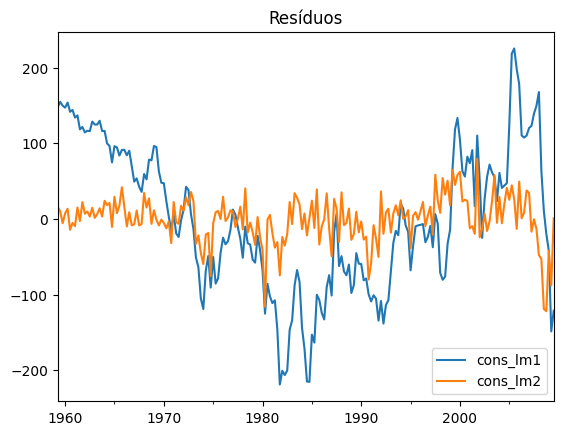
Em relação aos resíduos, o resultado é diferente. Enquanto a primeira equação possui maior variância (implicando em heterocedasticidade) e tendência descendente/ascendente (possivelmente implicando em autocorrelação), a segunda equação se comporta como um ruído branco, tornando-a melhor que o seu par.
Heterocedasticidade e Autocorrelação
 . Feito isso, nós regredimos o valor dos resíduos ao quadrado em relação às variáveis explicativas da equação original. Assim, basta verificar o teste
. Feito isso, nós regredimos o valor dos resíduos ao quadrado em relação às variáveis explicativas da equação original. Assim, basta verificar o teste  de significância ou utilizar um teste
de significância ou utilizar um teste  multiplicando o
multiplicando o  da segunda regressão pelo número de observações.
da segunda regressão pelo número de observações.A Heteroskedasticity and Autocorrelation Consistent (HAC) standard errors, também conhecidos como Newey-West standard errors, são uma forma de corrigir a matriz de covariância na presença de heterocedasticidade e autocorrelação nos dados.A abordagem HAC, desenvolvida por Newey e West (1987), é uma extensão da matriz de covariância robusta que leva em consideração tanto a heterocedasticidade quanto a autocorrelação dos erros.
A ideia básica por trás dos erros padrão HAC é ponderar as observações de forma que as correlações entre os erros sejam devidamente consideradas ao calcular a matriz de covariância. Essa ponderação leva em conta o número de defasagens (lags) a serem considerados para capturar a autocorrelação, bem como a forma como as observações distantes no tempo devem ser menos ponderadas do que as observações próximas.
_____________________________________
Quer aprender mais?
Seja um aluno da nossa trilha de Macroeconomia Aplicada e aprenda a criar projetos voltados para a Macroeconomia.
________________________________________________

