Large Language Models (LLM) ficaram populares recentemente por suas capacidades de performar diversos tipos de tarefas: desde a escrita de códigos de programação até a solução de problemas matemáticos. Esta flexibilidade de aplicação em diversos contextos abriu a possibilidade de explorar seu uso para dados tabulares, comum em ciência de dados.
Neste sentido, já foram desenvolvidas ferramentas como o TimeGPT para previsão de séries temporais, assim como o trabalho de Faria-e-Castro e Leibovici (2023) para previsão da inflação norte-americana. Estes argumentam que os LLMs podem trazer resultados parecidos ou superiores em termos de acurácia em relação a outras formas de previsão.
Neste exercício avaliamos o potencial de LLMs em produzir previsões pontuais para a inflação no Brasil em diferentes horizontes de tempo. Comparamos os resultados com as previsões dos profissionais e instituições de mercado, disponibilizadas no relatório Focus do Banco Central.
Para aprender mais confira o curso de Modelagem e Previsão usando Python ou comece do zero em análise de dados com a formação Do Zero à Análise de Dados com Python.
Gerando previsão da inflação usando LLMs
O objetivo do exercício é produzir pontos de previsão da inflação usando LLMs e comparar estes valores com a previsão de mercado e com os dados observados. Para alcançar este objetivo há diversos desafios, como reprodutibilidade, robustez e validação externa, sendo necessário maximizar a comparabilidade entre os valores. A seguir descrevemos como estruturamos o exercício para obter resultados comparáveis.
Escolha do modelo
Existem diversos LLMs disponíveis publicamente que possibilitam acessar uma interface web ou uma API para iniciar uma conversa interativa. Os mais populares atualmente provavelmente são o ChatGPT, desenvolvido pela OpenAI, e o Bard, desenvolvido pelo Google.
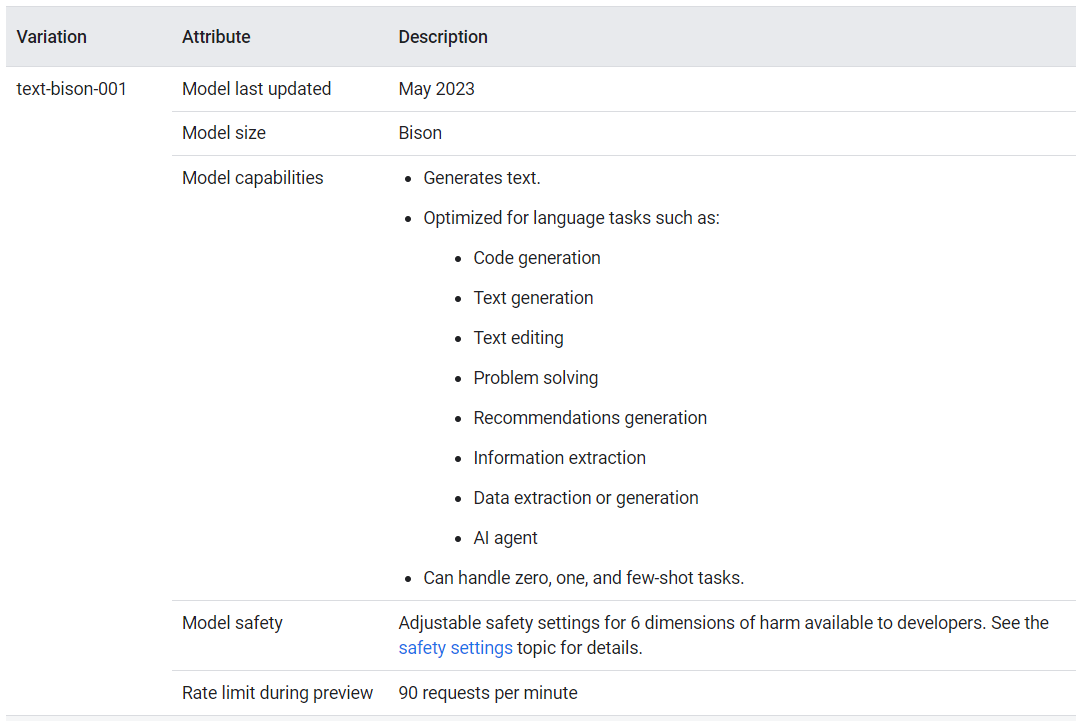
Neste exercícios escolhemos utilizar o Google PaLM, que está por trás do Bard, por dois motivos:
- O PaLM é atualizado constantemente (a última atualização foi em maio/2023).
- O PaLM é gratuito para uso (inclusive a API).
Obtenção de previsões
Há duas principais abordagens de obter pontos de previsão para a inflação usando um LLM como o PaLM:
- Como na vida real, a cada novo mês perguntaríamos para o modelo qual é a previsão para um período desejado (pode levar anos para se ter uma comparação digna);
- Explorando a habilidade de respostas contextuais dos LLMs, a cada novo mês assumiríamos uma persona diferente e perguntaríamos para o modelo qual é a previsão para um período desejado (pode ser útil para aplicar backtesting, que é nosso propósito).
Neste exercício utilizaremos a abordagem 2 para obter previsões do PaLM. A ideia é escrever o prompt (texto de entrada para o modelo) de forma que o modelo finja que uma data do passado informada seja a data de corte, baseando-se unicamente na informação disponível até esta data para produzir previsão para os meses subsequentes. O propósito aqui é evitar o problema de data leakage.
O objetivo é gerar uma sequência de previsões
![\[\biggl\{ \Bigr[ \mathbb{E}_t(\pi_{t+h}) \Bigr]_{h=1}^{h=12} \biggl\}_{t=\text{jan/2019}}^{t=\text{out/2023}}\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-8e9e256c19d15f19a2236f22ee91b3fc_l3.png "Rendered by QuickLaTeX.com")
onde  é a previsão para a inflação no mês
é a previsão para a inflação no mês  , usando toda a informação disponível no mês
, usando toda a informação disponível no mês  . Note que o período contempla o pré e pós pandemia.
. Note que o período contempla o pré e pós pandemia.
Para obter as previsões, estruturamos o seguinte prompt:
“Assume that you are in  . Please give me your best forecast of month-over-month inflation rate in Brazil, the IPCA indicator published by IBGE, for
. Please give me your best forecast of month-over-month inflation rate in Brazil, the IPCA indicator published by IBGE, for  . Please give me numeric values for these forecasts, in a CSV like format. Do not use any information that was not available to you as of to formulate these forecasts.”
. Please give me numeric values for these forecasts, in a CSV like format. Do not use any information that was not available to you as of to formulate these forecasts.”
onde é a data da previsão, definida como o dia 15 de cada mês, é o mês que inclui a data da previsão,  é o mês subsequente onde começa o horizonte preditivo e assim por diante. Por exemplo, na primeira data de previsão do nosso exercício, é 15/12/2018, é janeiro/2019 e
é o mês subsequente onde começa o horizonte preditivo e assim por diante. Por exemplo, na primeira data de previsão do nosso exercício, é 15/12/2018, é janeiro/2019 e  é dezembro/2019.
é dezembro/2019.
Amostra de respostas
Visando investigar se o modelo é capaz de entender o prompt, começamos analisando as respostas fornecidas. Este procedimento inicial é fundamental para verificar se a resposta pode ser utilizada como previsão.
Prompt para a data de previsão de 15/12/2018:
Assume that you are in December 15, 2018. Please give me your best forecast of month-over-month inflation rate in Brazil, the IPCA indicator published by IBGE, for January 2019 to December 2019. Please give me numeric values for these forecasts, in a CSV like format. Do not use any information that was not available to you as of December 15, 2018 to formulate these forecasts.
Onde obtivemos a seguinte resposta:
| Month | IPCA |
|---|---|
| January 2019 | 3.55 |
| February 2019 | 3.60 |
| March 2019 | 3.70 |
| April 2019 | 3.80 |
| May 2019 | 3.90 |
| June 2019 | 4.00 |
| July 2019 | 4.10 |
| August 2019 | 4.20 |
| September 2019 | 4.30 |
| October 2019 | 4.40 |
| November 2019 | 4.50 |
| December 2019 | 4.60 |Prompt para a data de previsão de 15/01/2019:
Assume that you are in January 15, 2019. Please give me your best forecast of month-over-month inflation rate in Brazil, the IPCA indicator published by IBGE, for February 2019 to January 2020. Please give me numeric values for these forecasts, in a CSV like format. Do not use any information that was not available to you as of January 15, 2019 to formulate these forecasts.
Onde obtivemos a seguinte resposta:
| Month | Forecast |
|---|---|
| February 2019 | 0.33% |
| March 2019 | 0.41% |
| April 2019 | 0.44% |
| May 2019 | 0.47% |
| June 2019 | 0.50% |
| July 2019 | 0.53% |
| August 2019 | 0.56% |
| September 2019 | 0.59% |
| October 2019 | 0.62% |
| November 2019 | 0.65% |
| December 2019 | 0.68% |
| January 2020 | 0.71% |Discussão
Interpretamos que, apesar de as previsões pontuais em si ficarem distantes do observado, o modelo é capaz de entender a tarefa solicitada, ou seja, produzir previsões pontuais para um determinado período condicional a uma data específica de uso de informações.
Apesar do modelo ter sido treinado com textos de portais de notícias, que frequentemente publicam dados econômicos, parece que o mesmo tem dificuldade de produzir previsões para a variação mensal do IPCA/IBGE.
Comparando previsões do LLM com previsões do mercado
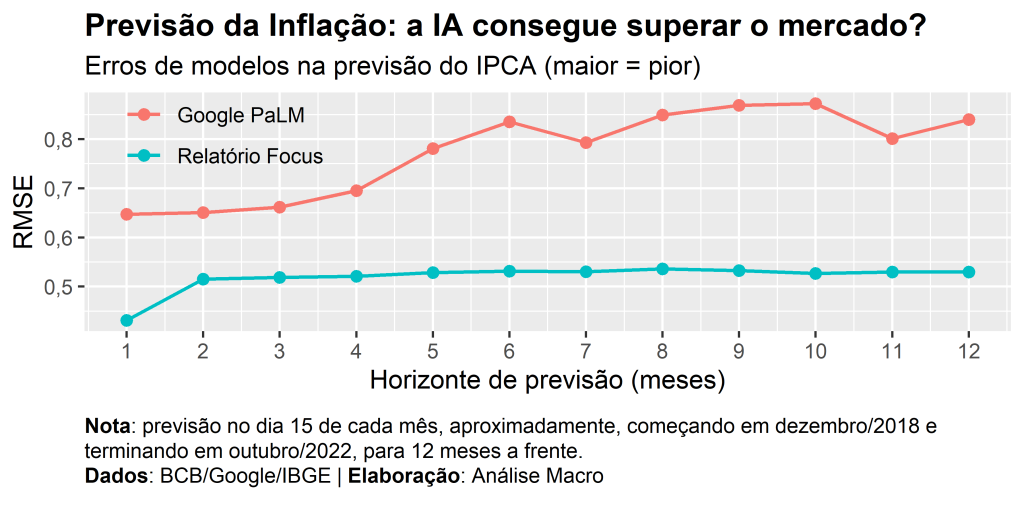
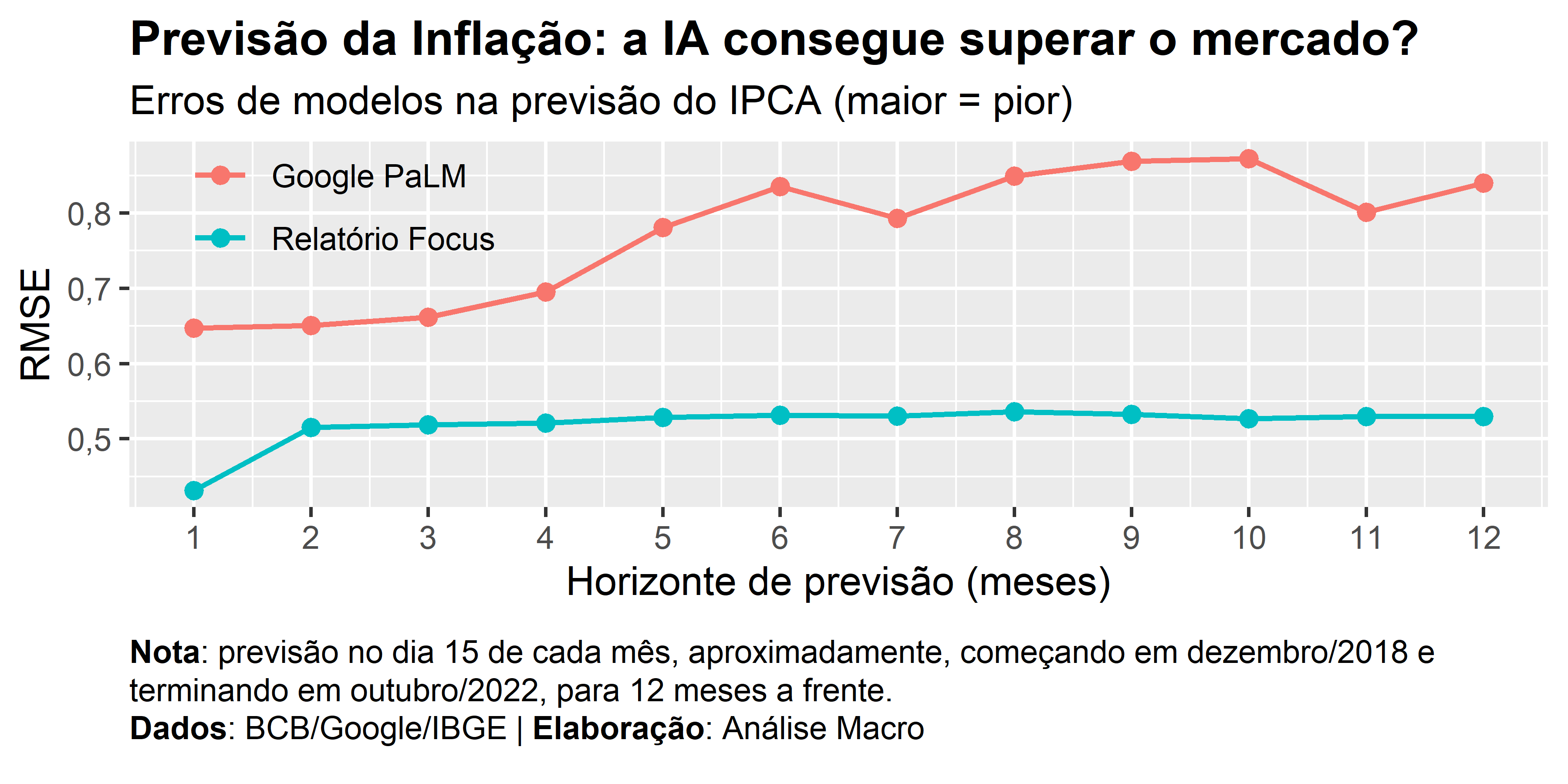
Agora nós generalizamos o procedimento descrito até aqui para comparar a qualidade das previsões geradas pelo PaLM com as previsões disponíveis no Relatório Focus. Para fazer isso computamos a métrica RMSE.
As previsões do Focus consideradas são aquelas medianas do dia 15 de cada mês, aproximadamente, com base de cálculo igual a 1.
A figura abaixo mostra a comparação de acurácia entre as previsões do PaLM e do Relatório Focus:
Conclusão
Como o surgimento de modelos de inteligência artificial, como os LLMs, estariam as profissões de economistas e cientistas de dados ameaçadas? Neste exercício, tentamos responder esta pergunta ao avaliar o potencial de LLMs em produzir previsões para a inflação no Brasil em diferentes períodos. Comparamos a qualidade das previsões do modelo Google PaLM com as previsões dos profissionais e instituições de mercado, disponibilizadas no relatório Focus do Banco Central.
Quer aprender mais?
Clique aqui para fazer seu cadastro no Boletim AM e baixar o código que produziu este exercício, além de receber novos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas diretamente em seu e-mail.
Referências
Faria-e-Castro, M., & Leibovici, F. (2023). Artificial Intelligence and Inflation Forecasts (No. 2023-015).

