No próximo dia 15/12, darei uma aula ao vivo sobre como automatizar um departamento de pesquisa macroeconômica com o R. A aula faz parte do lançamento do Clube AM, um grupo fechado e exclusivo de pessoas que buscam estar atualizadas com o que há de mais moderno no mundo da Análise de dados com R, com reuniões mensais e acesso a materiais e descontos exclusivos. Para se inscrever na aula, clique aqui. Para ilustrar o que faremos nessa aula, no Comentário de Conjuntura dessa semana vou mostrar como é possível automatizar a coleta e tratamento dos dados do Produto Interno Bruto (PIB) brasileiro.
Em termos simples, o PIB é a soma de bens e serviços finais produzidos por um determinado país em um período de tempo. Em geral, um trimestre. No Brasil, cabe ao Instituto Brasileiro de Geografia e Estatística (IBGE) a coleta e divulgação dos dados do PIB.
Para ilustrar como é possível coletar os dados do PIB com o R, vamos usar aqui o pacote sidrar, que coleta dados diretamente do SIDRA/IBGE. O código a seguir carrega alguns pacotes que usaremos.
library(tidyverse) library(sidrar) library(zoo) library(tstools) library(scales)
Na sequência, nós coletamos os dois números-índices do PIB e criamos três métricas de crescimento: a variação marginal, a variação interanual e a variação acumulada em 4 trimestres. Com isso, poderemos ter uma dimensão da recuperação pós-pandemia.
## Coletar Números Indices do PIB ### Número Indice com ajuste sazonal pib_sa = get_sidra(api='/t/1621/n1/all/v/all/p/all/c11255/90707/d/v584%202') %>% mutate(date = as.yearqtr(`Trimestre (Código)`, format='%Y%q')) %>% rename(pib_sa = Valor) %>% mutate(var_marginal = (pib_sa/lag(pib_sa,1)-1)*100) %>% select(date, pib_sa, var_marginal) %>% as_tibble() ### Número Índice sem ajuste pib = get_sidra(api='/t/1620/n1/all/v/all/p/all/c11255/90707/d/v583%202') %>% mutate(date = as.yearqtr(`Trimestre (Código)`, format='%Y%q')) %>% rename(pib = Valor) %>% mutate(var_interanual = (pib/lag(pib,4)-1)*100) %>% mutate(var_anual = acum_i(pib, 4)) %>% select(date, pib, var_interanual, var_anual) %>% as_tibble() ### Juntar os dados df_pib = inner_join(pib_sa, pib, by='date') %>% drop_na()
Um gráfico do número-índice do PIB e das principais métricas de crescimento que criamos é colocado abaixo.
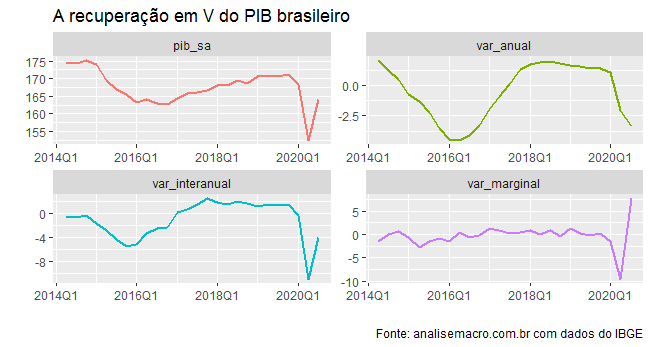
Pelos gráficos, observa-se um início de recuperação em V da economia brasileira no pós-pandemia. Para a continuidade da recuperação, contudo, ainda restam diversas incertezas no horizonte, como a solvência fiscal e o fim do auxílio emergencial.
____________________
(*) Conheça o Clube AM aqui.


