Uma das questões mais delicadas ao longo de 2020 era evitar que (1) a população vulnerável ficasse desamparada na maior crise sanitária dos últimos 100 anos e (2) as micro e pequenas empresas falissem ou solicitassem recuperação judicial. Evitar que (2) ocorresse implicava em irrigar o mercado de crédito com dinheiro subsidiado, mitigando assim o risco de crédito associado a esse tipo de empréstimo.
Empresas falidas ou em recuperação judicial têm impacto sobre o PIB Potencial da economia, conforme exercício que fizemos em meados do ano passado. Quanto maior o número de empresas nessa condição, menor a capacidade de produção do país, logo menor será o PIB Potencial.
Isso dito, cabe nos perguntar: houve um aumento de falências e recuperações judiciais ao longo de 2020?
Para responder essa pergunta, podemos recorrer aos índices da Serasa e da Boa Vista. Os arquivos estão disponíveis nos respectivos sites dessas instituições. De posse desses dados, podemos importá-los conforme o código abaixo.
library(tidyverse)
library(readxl)
library(xts)
library(zoo)
library(timetk)
library(vars)
library(seasonal)
## Dados de Falências, RJ e concordatas SERASA
falencias = read_excel('FACONS.xls', sheet=1, skip=4) %>%
rename(date = "...1",
falencias_requeridas_total = "Total...5",
falencias_decretadas_total = "Total...9",
rj_requeridas_total = "Total...13",
rj_deferidas_total = "Total...17") %>%
filter(date > '2006-01-01') %>%
mutate(falencias_requeridas_sa = final(seas(ts(falencias_requeridas_total,
start=c(1991,01), freq=12))),
falencias_decretadas_sa = final(seas(ts(falencias_decretadas_total,
start=c(1991,01), freq=12))),
rj_requeridas_sa = final(seas(ts(rj_requeridas_total,
start=c(1991,01), freq=12))),
rj_deferidas_sa = final(seas(ts(rj_deferidas_total,
start=c(1991,01), freq=12)))) %>%
dplyr::select(date, falencias_requeridas_sa, falencias_decretadas_sa,
rj_requeridas_sa, rj_deferidas_sa) %>%
gather(variavel, valor, -date)
## Índice de Falências Boa Vista
fal_boavista = read_excel('Falências-e-Recuperações-Judiciais.xlsx',
skip=3) %>%
rename(date = "...1",
falencias_requeridas = "(média 2011 = 100)...2",
falencias_decretadas = "(média 2011 = 100)...3",
rj_pedidos = "(média 2014 = 100)...4",
rj_deferimentos = "(média 2014 = 100)...5") %>%
mutate(falencias_requeridas_sa = final(seas(ts(falencias_requeridas,
start=c(2006,01), freq=12))),
falencias_decretadas_sa = final(seas(ts(falencias_decretadas,
start=c(2006,01), freq=12))),
rj_pedidos_sa = final(seas(ts(rj_pedidos,
start=c(2006,01), freq=12))),
rj_deferimentos_sa = final(seas(ts(rj_deferimentos,
start=c(2006,01), freq=12)))) %>%
dplyr::select(date, falencias_requeridas_sa, falencias_decretadas_sa,
rj_pedidos_sa, rj_deferimentos_sa) %>%
gather(variavel, valor, -date)
Uma vez que tenhamos tratados os dados, podemos gerar os gráficos a seguir.
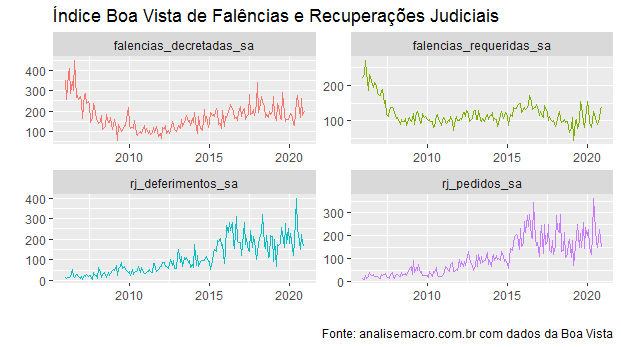
O índice Boa Vista de falências e recuperações judiciais indica que, de fato, houve um aumento tanto no número de pedidos quanto de deferimentos de recuperações judiciais ao longo de 2020. O número de falências, por outro lado, não parece ter descolado muito do que se observou em anos recentes.
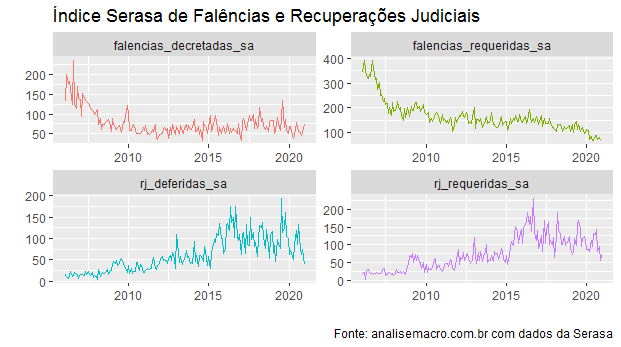
O índice Serasa, por seu turno, também não mostra um avanço atípico no número de falências, mas captura um aumento no número de recuperações judiciais ao longo dos primeiros meses de 2020.
Os membros do Clube AM, a propósito, têm acesso aos códigos completos dos nossos Comentários e Exercícios.
_______________________


