Os dados do Cadastro Geral de Empregados e Desempregados (CAGED) divulgados pelo Ministério da Economia mostram que o fluxo de emprego líquido formal se acelerou ao longo de 2019. O saldo dessazonalizado saiu de uma média de 32 mil empregos líquidos no 1º trimestre para 48 mil no terceiro. Dada a relação existente entre o saldo do CAGED e o crescimento do PIB, como mostro na Edição 58 do Clube do Código, espera-se que essa aceleração vista no CAGED tenha efeito sobre o crescimento econômico. Para ilustrar, abaixo nós coletamos os dados do PIB e do saldo do CAGED.
#####################################
####### CAGED vs. PIB ###############
## Pacotes
library(ecoseries)
library(sidrar)
library(xts)
library(ggplot2)
library(scales)
library(BMR)
### Pacote Seasonal
library(seasonal)
Sys.setenv(X13_PATH = "C:/Séries Temporais/R/Pacotes/seas/x13ashtml")
#checkX13()
## Baixar dados
caged = ts(series_ipeadata('272844966',
periodicity = 'M')$serie_272844966$valor,
start=c(1999,05), freq=12)
tabela = get_sidra(api='/t/1620/n1/all/v/all/p/all/c11255/90707/d/v583%202')
pib = ts(tabela$Valor, start=c(1996,01), freq=4)
O saldo do CAGED é mensal enquanto o PIB é uma série trimestral. Assim, precisaremos fazer alguns ajustes nas séries. O código abaixo implementa.
## Dessazonalizar Caged
cagedsa <- final(seas(caged))
## Criar variação anual
anual <- (((pib+lag(pib,-1)+lag(pib,-2)+lag(pib,-3))/4)/
((lag(pib,-4)+lag(pib,-5)+lag(pib,-6)+lag(pib,-7))/4)-1)*100
## Trimestralizar Caged
dates = seq(as.Date('1999-07-01'), as.Date('2019-09-01'),
by='1 month')
caged = window(cagedsa, start=c(1999,07), end=c(2019,09))
caged = data.frame(dates=dates, caged=caged)
caged = xts(caged$caged, order.by = caged$dates)
caged = apply.quarterly(caged, FUN=mean)
caged = caged[-1]
## Juntar os dados
pib = window(anual, start=c(1999,4))
pib = data.frame(dates=as.Date(time(caged)), pib=pib)
pib = xts(pib$pib, order.by = index(caged))
data = cbind(caged/1000, pib)
colnames(data) = c('Saldo CAGED', 'Crescimento PIB')
Uma vez que os dados estejam tratados, podemos criar um gráfico como abaixo.
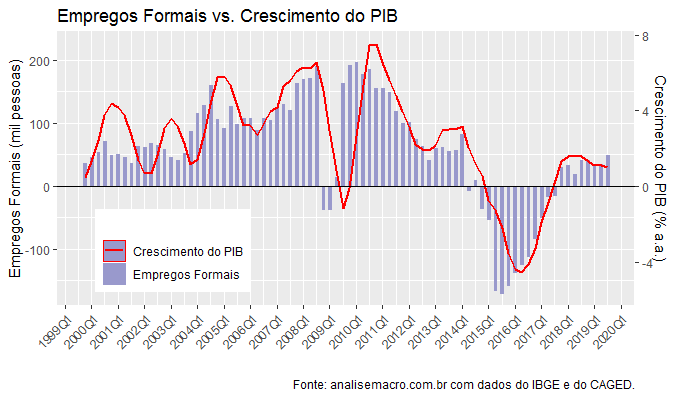
A elevada correlação entre as séries também implica em uma causalidade, no sentido do saldo do CAGED para o crescimento do PIB. Em outras palavras, o maior emprego líquido formal vai gerar maior crescimento econômico nos próximos trimestres. Na margem, isso já foi sentido, inclusive, com o número acima do esperado no 3º tri. Isso deve ser visto nas métricas mais suavizadas daqui para frente.
________________________
(*) Aprenda a usar o R para fazer análise de dados com nossos Cursos Aplicados de R.


