O IBGE divulgou na última sexta-feira a PNAD Contínua em seu recorte trimestral - os dados podem ser vistos aqui. A pesquisa tem diversos indicadores interessantes, como o tempo de procura por emprego entre os desocupados e medidas de subutilização da força de trabalho. Nesse Comentário de Conjuntura, vamos ilustrar o desemprego pelo tempo de procura, dando uma ideia do desemprego de longo prazo no Brasil e sua relação com o desemprego total.
O desemprego de longo prazo é uma medida internacionalmente conhecida e pode ser definida pelo tempo de procura por emprego superior a dois anos. Ela é um indicador importante não apenas por sinalizar o nível e o tempo de ociosidade da economia, mas também por refletir a perda de produtividade dentro do ciclo econômico. Em particular, quanto mais tempo a pessoa fica desempregada, maior a perda de capital humano, mais difícil é conseguir um novo posto de trabalho (Ball e Mankiw, 2002).
Nesse contexto, uma retomada demorada da economia pode agravar um fenômeno conhecido na literatura de economia do trabalho chamado de histerese. Isto é, a dificuldade de um objeto, no caso a taxa de desemprego, em voltar ao seu estado original após sofrer um determinado choque. Ou, em outras palavras, a dificuldade do desemprego ceder após uma alta pronunciada como a que temos observado nos últimos anos.
Essa dificuldade estaria relacionada justamente à perda de capital humano associada ao desemprego por longo período.
Para verificar o estágio do desemprego de longo prazo no Brasil, vamos pegar os dados da tabela 1616 com a ajuda do pacote sidrar. O código abaixo implementa.
table = get_sidra(api='/t/1616/n1/all/v/4092/p/all/c1965/all') pea = get_sidra(api='/t/4093/n1/all/v/4088/p/all/c2/6794')$Valor total = table$Valor[table$`Tempo de procura de trabalho (Código)`==40310] ummes = table$Valor[table$`Tempo de procura de trabalho (Código)`==31827] umano = table$Valor[table$`Tempo de procura de trabalho (Código)`==31828] umdosanos = table$Valor[table$`Tempo de procura de trabalho (Código)`==31829] doisanos = table$Valor[table$`Tempo de procura de trabalho (Código)`==101227]
O código pega os dados referentes ao tempo de procura por emprego. A seguir, nós preparamos nossos dados para um gráfico de área empilhado.
time = seq(as.Date('2012-03-01'), as.Date('2019-12-01'), by='3 month')
data = cbind(ummes/total, umano/total, umdosanos/total,
doisanos/total)*100
colnames(data) = c('Menos de 1 mês', 'De 1 mês a menos de 1 ano',
'De 1 ano a menos de 2 anos', '2 anos ou mais')
longrun = xts(data, order.by=time)
longrun = data.frame(time = index(longrun),
melt(as.data.frame(longrun)))
colnames(longrun) = c('time', 'Indexador', 'value')
E o gráfico.
ggplot(longrun, aes(x = time, y = value)) +
geom_area(aes(colour = Indexador, fill = Indexador))+
xlab('')+ylab('Participação Percentual')+
labs(title='Desemprego de Longo Prazo no Brasil',
caption='Fonte: analisemacro.com.br')+
theme(legend.position = 'top',
legend.title = element_blank())
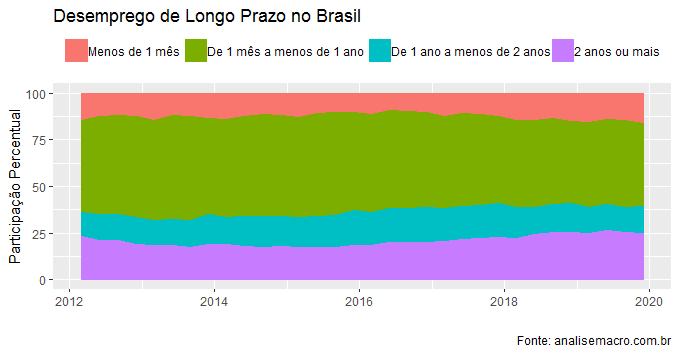
O desemprego de longo prazo representa algo como 1/4 do desemprego total. No quarto trimestre de 2019, eram 2,9 milhões de pessoas nessa situação. Acompanhar o avanço dessa métrica é uma maneira de verificar o quanto a retomada da economia está ganhando tração.
(*) Ver Ball, Laurence, and N. Gregory Mankiw. 2002. "The NAIRU in Theory and Practice ." Journal of Economic Perspectives, 16 (4): 115-136.
(**) Aprenda a analisar dados em nossos Cursos Aplicados de R.
___________________

