No nosso Curso de Análise de Conjuntura usando o R, ensino os alunos a analisar os dados da Pesquisa Nacional por Amostra de Domicílios Contínua (PNAD Contínua), que traz diversos dados sobre o mercado de trabalho brasileiro. A análise desses dados dá uma dimensão interessante sobre os efeitos da pandemia do Covid-19. Para ilustrar, vamos olhar alguns dados agregados nesse Comentário de Conjuntura.
O script, como de hábito, começa com alguns pacotes...
## Pacotes utilizados nessa apresentação library(tidyverse) library(lubridate) library(sidrar) library(zoo) library(scales) library(timetk) library(knitr)
Uma vez que os pacotes estejam carregados, eu posso pegar alguns dados agregados da PNAD, como no código abaixo.
populacao = get_sidra(api='/t/6022/n1/all/v/606/p/all') %>%
mutate(date = parse_date(`Trimestre Móvel (Código)`,
format='%Y%m')) %>%
select(date, Valor) %>%
as_tibble()
names = c("date", 'pnea', 'pea', 'desocupada', 'ocupada', 'pia')
condicao = get_sidra(api='/t/6318/n1/all/v/1641/p/all/c629/all') %>%
mutate(date = parse_date(`Trimestre Móvel (Código)`,
format='%Y%m')) %>%
select(date, "Condição em relação à força de trabalho e condição de ocupação", Valor) %>%
spread("Condição em relação à força de trabalho e condição de ocupação", Valor) %>%
`colnames<-`(names) %>%
as_tibble()
Com o código acima, eu pego dados de duas tabelas, a 6022 e 6318. Assim, consigo criar as variáveis que eu mais quero, que são a taxa de desemprego e a taxa de participação com o código a seguir.
agregado_pnad = inner_join(populacao, condicao, by='date') %>% rename(populacao = Valor) %>% mutate(inativos = populacao - pia, desemprego = desocupada/pea*100, participacao = pea/pia*100) %>% select(date, populacao, inativos, pia, pea, pnea, ocupada, desocupada, desemprego, participacao)
Uma vez que os dados estejam disponíveis, posso visualizá-los como abaixo.
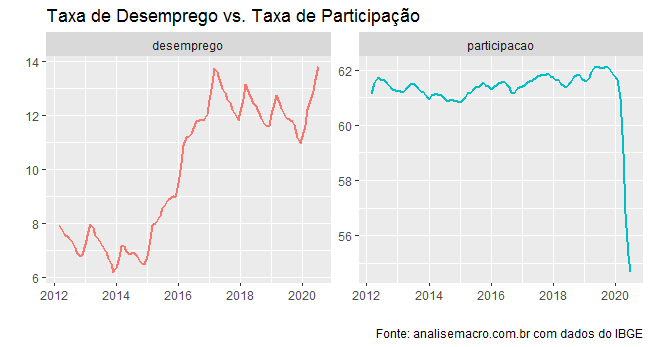
Observe que o desemprego se aproxima dos 14% da PEA (População Economicamente Ativa). Porém, isso se dá com uma taxa de participação (PEA sobre a PIA) bastante reduzida por conta da pandemia do Covid-19. Em palavras outras, com o fim do auxílio emergencial e também com a proximidade da vacina e/ou da imunidade de rebanho na maioria das capitais, espera-se que o desemprego dê um salto ainda maior nos próximos meses.
________________
(*) Para ter acesso aos códigos completos de nossos futuros exercícios, cadastre-se na nossa Lista VIP aqui.
(**) As inscrições para as Turmas de Verão começam no próximo dia 27/10. Para ser avisado por e-mail, cadastre-se aqui.

