Amanhã, o IBGE divulga o resultado do IPCA de maio. O consenso formado pela média suavizada do Focus indica uma variação de 0,7%, a mesma que indica o nosso modelo de previsão, conforme mostramos ontem no Relatório AM. Se for confirmado, a inflação acumulada em 12 meses romperá a casa dos 7% a.a. A despeito da boa notícia do PIB do 1º trimestre, o hiato do produto ainda encontra-se em terreno negativo, o que indica que estamos basicamente flertando com o que os economistas chamam de estagflação, aquele momento do ciclo onde temos inflação alta (ou em elevação, para ser mais claro) e estagnação econômica. Nesse Comentário de Conjuntura, vamos falar um pouco sobre o conceito.
(*) Aprenda a fazer esse tipo de análise através dos nossos Cursos Aplicados de R.
O comentário de conjuntura 22 começa carregando os seguintes pacotes:
library(tidyverse) library(readxl) library(rbcb) library(forecast) library(vars) library(tstools) library(latex2exp) library(sidrar) library(lubridate) library(scales) library(RcppRoll) library(ggrepel) library(seasonal) library(zoo)
A seguir, pegamos os dados da inflação medida pelo IPCA, assim como os núcleos de inflação desenvolvidos e acompanhados pelo Banco Central.
## Criar Inflação mensal e acumulada em 12 meses
ipca_indice =
'/t/1737/n1/all/v/2266/p/all/d/v2266%2013' %>%
get_sidra(api=.) %>%
mutate(date = ymd(paste0(`Mês (Código)`, '01'))) %>%
dplyr::select(date, Valor) %>%
mutate(mensal = round((Valor/lag(Valor, 1)-1)*100, 2),
anual = round((Valor/lag(Valor, 12)-1)*100, 2))
## Criar amostra
ipca_subamostra = ipca_indice %>%
filter(date >= as.Date('2007-06-01'))
## Pegar núcleos
series = c(ipca_ex2 = 27838,
ipca_ex3 = 27839,
ipca_ms = 4466,
ipca_ma = 11426,
ipca_ex0 = 11427,
ipca_ex1 = 16121,
ipca_dp = 16122)
nucleos = get_series(series, start_date = '2006-07-01') %>%
purrr::reduce(inner_join)
nucleos_12m <- nucleos %>%
mutate(across(!date, (function(x) 1+x/100))) %>%
mutate(across(!date, (function(x) (roll_prod(x, n=12, align='right',
fill = NA)-1)*100 )))
data_nucleos_12 = nucleos_12m %>%
filter(date >= as.Date('2007-06-01'))
## Inflação vs. Núcleos
meta = c(rep(4.5, 139), rep(4.25, 12),
rep(4, 12), rep(3.75, 12), rep(3.5, 12), rep(3.25, 12))
meta_max = c(rep(4.5+2, 115), meta[-(1:115)]+1.5)
meta_min = c(rep(4.5-2, 115), meta[-(1:115)]-1.5)
metas = tibble(lim_sup=meta_max, meta=meta,
lim_inf=meta_min)
media.nucleos <- rowMeans(dplyr::select(data_nucleos_12, -date))
df = tibble(nucleos = round(media.nucleos, 2),
lim_sup = head(metas$lim_sup, n = nrow(ipca_subamostra)),
meta = head(metas$meta, n = nrow(ipca_subamostra)),
lim_inf = head(metas$lim_inf, n = nrow(ipca_subamostra)),
inflacao = ipca_subamostra$anual,
date = data_nucleos_12$date)
Na sequência, plotamos o primeiro gráfico do comentário.
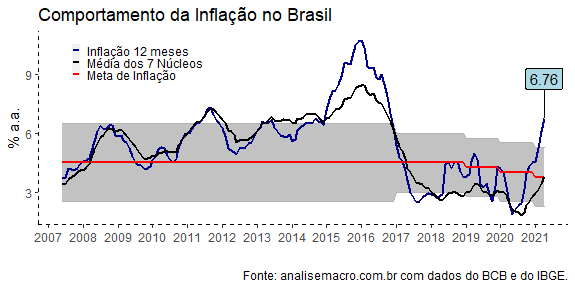
Como se pode ver, a inflação acumulada em 12 meses está acima do limite superior da meta, resultado de diversos choques que têm ocorrido sobre a economia brasileira desde o ano passado. O aumento de commodities está por trás tanto do aumento de alimentos quanto do aumento dos combustíveis, que afetam diretamente a inflação medida pelo IPCA.
url = 'https://www12.senado.leg.br/ifi/dados/arquivos/estimativas-do-hiato-do-produto-ifi/at_download/file'
download.file(url, destfile='hiato.xlsx', mode='wb')
hiato = read_excel('hiato.xlsx', sheet = 2, skip=1)
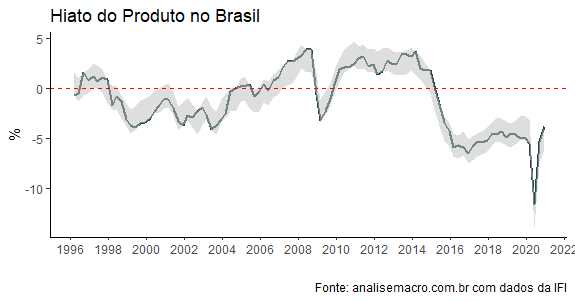
Em meio a esses choques, está um hiato do produto em recuperação, como se pode ver pela figura acima, produzida pela IFI. Ainda em terreno negativo (os dados vão até 2021Q4), o hiato respira por aparelhos em meio a uma sucessão de crises que assola a economia brasileira desde meados de 2014.
Inflação em aceleração em meio a um hiato do produto negativo é a definição de estagflação. Por um lado, a inflação aumenta por causa de choques que afetam a economia doméstica. Por outro, o ciclo econômico se mantém em baixa como consequência de alguma crise externa/interna.
É, basicamente, o pior dos mundos para o cenário macroeconômico, porque afeta em última instância a taxa de desemprego, como pode ser visto abaixo.
desemprego = get_sidra(api="/t/6381/n1/all/v/4099/p/all/d/v4099%201") %>% mutate(date = parse_date(`Trimestre Móvel (Código)`, format='%Y%m')) %>% dplyr::select(date, Valor) %>% rename(desemprego = Valor) %>% mutate(desemprego_sa = final(seas(ts(desemprego, start=c(2012,03), freq=12)))) %>% as_tibble()
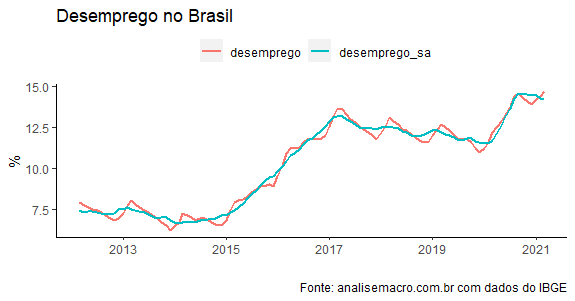
A taxa de desemprego tem aumentado no Brasil desde 2014, como resultado da crise interna que vivemos à época. Passou por um momento de leve redução nos anos pré-pandemia e reagiu forte ao choque mundial provocado pela Covid-19.
Em outras palavras, o desemprego no Brasil mudou de nível e, dificilmente, voltará aos níveis de 2013/2014 no curto prazo. Isto porque, o desemprego é a última variável a reagir à melhora do ambiente econômico. Há muitos motivos para isso. Um deles é que o desemprego afeta o capital humano das pessoas. Quanto maior o tempo desemprego, maior a parte de capital humano, o que torna difícil para o trabalhador voltar ao mercado.
Dito isso, é bastante preocupante ver o comportamento do desemprego de longo prazo no Brasil, como pode ser visto abaixo.
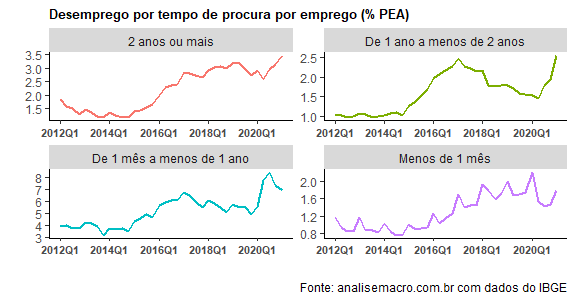
table = get_sidra(api='/t/1616/n1/all/v/4092/p/all/c1965/all') %>% mutate(date = as.yearqtr(`Trimestre (Código)`, format='%Y%q')) %>% dplyr::select(date, `Tempo de procura de trabalho`, Valor) %>% spread(`Tempo de procura de trabalho`, Valor) %>% as_tibble() ratio = table %>% mutate(across(!date, (function(x) x / Total *100))) %>% dplyr::select(-Total) ratio %>% gather(variavel, valor, -date) %>% ggplot(aes(x=date, y=valor, colour=variavel))+ geom_area(aes(colour=variavel, fill=variavel))+ theme(legend.title = element_blank(), legend.position = 'left', plot.title = element_text(size=8, face='bold'))+ scale_x_yearqtr(breaks= pretty_breaks(n=4), format="%YQ%q")+ labs(x='', y='', title='Desemprego por tempo de procura por trabalho', caption='Fonte: analisemacro.com.br com dados do IBGE')
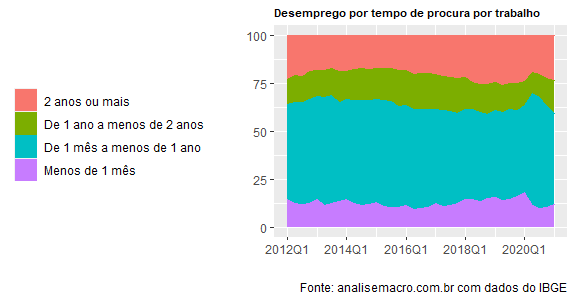
O desemprego de mais de 2 anos tem aumentado de forma consistente nos últimos anos, como mostra a normalização pela PEA vista abaixo.
Os dados são da PNAD Trimestral, com o último dado disponível de 2020Q4.
Quanto maior o tempo da crise, maiores vítimas vão sendo acumuladas dentro do desemprego de longo prazo. A perda de capital humano, por suposto, afeta de forma direta o PIB Potencial da economia, com consequências não desprezíveis sobre o crescimento de longo prazo da economia brasileira.
(*) Aprenda a fazer esse tipo de análise através dos nossos Cursos Aplicados de R.
____________________
(**) Para quem quiser ter acesso a todos os códigos desse e de todos os exercícios que publicamos ao longo da semana, visite o Clube AM.


