A pandemia do coronavírus impôs diversos desafios para a humanidade, nos mais diferentes campos. Em termos de previsão de variáveis macroeconômicas, não é diferente. O ajuste dos modelos tem sido um desafio para economistas e analistas de mercado, que possuem a árdua e ingrata tarefa de antecipar eventos futuros. Pensando nisso, nesse Comentário de Conjuntura buscamos implementar um modelo de previsão para a taxa de desemprego medida pela PNAD Contínua que utiliza termos de busca do Google Trends.
A base de dados do Google Trends é hoje em dia bastante conhecida por especialistas que se dedicam à tarefa de forecasting, tendo um amplo conjunto de artigos e papers que fazem uso da mesma para esse fim. D´Amuri e Marcucci, 2017, por exemplo, fazem uso dessa base para construir um modelo de previsão para o desemprego nos Estados Unidos. Os resultados encontrados sugerem que essa base de dados é um bom preditor para a taxa de desemprego norte-americana.
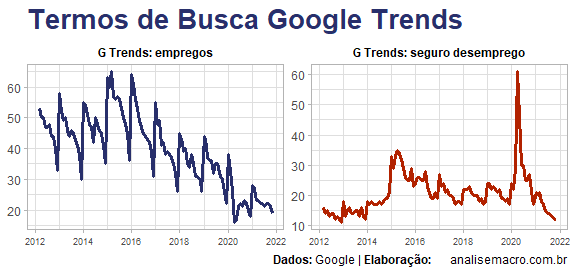
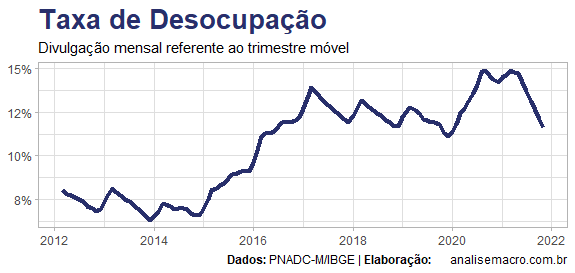
Tendo o mesmo objetivo que os autores, nós revisamos um modelo de cointegração para o desemprego que inclui os termos de busca empregos e seguro desemprego, que são ilustrados acima. A inclusão do termo seguro desemprego procura "tratar" o efeito pandemia, que causou um forte choque sobre a taxa de desemprego medida pela PNAD Contínua, como pode ser visto abaixo.
Além dos termos de busca do GT, também adicionamos mais algumas co-variáveis ao modelo, listadas a seguir.

O modelo é implementado, então, no R, com o auxílio da biblioteca vars e uso da metodologia de Johansen. A seguir, um gráfico que apresenta a previsão fora da amostra considerada.

Os códigos que implementam o exercício estão disponíveis para os membros do Clube AM.

