[et_pb_section admin_label="section"][et_pb_row admin_label="row"][et_pb_column type="4_4"][et_pb_text admin_label="Texto" background_layout="light" text_orientation="justified" text_font="Verdana||||" text_font_size="18" use_border_color="off" border_color="#ffffff" border_style="solid"]
O principal índice da Bolsa de SP, o IBOVESPA, se aproxima da inédita marca dos 100 mil pontos. E não demorará muito, dado que o mercado segue confiante na agenda econômica do novo governo, que inclui privatizações e reformas, em particular a reforma da previdência. Para coletar os dados do IBOV com o R, como fazemos em nosso curso de Econometria Financeira usando o R, podemos utilizar o pacote quantmod como no código abaixo.
library(quantmod)
## Ibovespa
env = new.env()
getSymbols("^BVSP",src="yahoo",
env=env,
from=as.Date('2018-12-01'))
ibovespa = env$BVSP[,4]
ibovespa = ibovespa[complete.cases(ibovespa)]
Uma vez que pegamos os dados do índice, podemos plotar um gráfico na sequência.
autoplot(ibovespa)+
geom_line(size=.8, colour='red')+
xlab('')+ylab('Pontos')+
scale_x_date(date_breaks = '7 days',
labels = date_format("%b %d"))+
labs(title='Índice Bovespa',
caption='Fonte: analisemacro.com.br com dados do Yahoo Finance.')
E o gráfico segue abaixo...
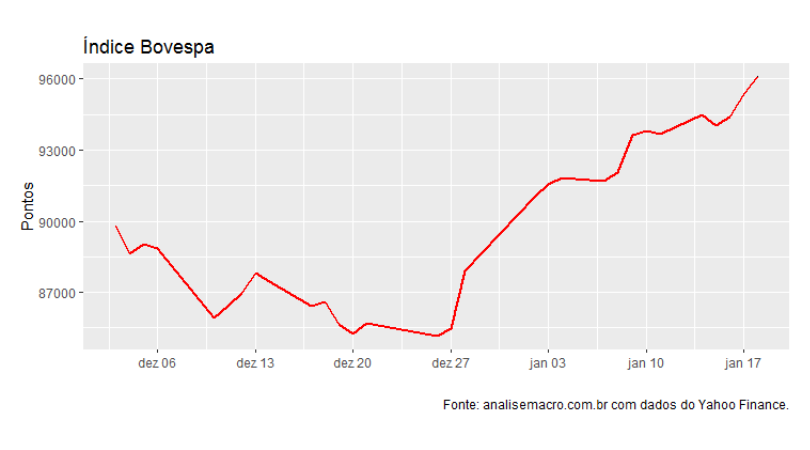
A ascensão do índice se correlaciona com a proximidade do novo governo e, portanto, com os pronunciamentos da nova equipe econômica. Conheça nossos Cursos Aplicados de R para saber como coletar, tratar, analisar e apresentar dados como esse utilizando uma das mais poderosas ferramentas de data science atualmente disponíveis!
[/et_pb_text][/et_pb_column][/et_pb_row][/et_pb_section]

