Escrevi nesse espaço no último domingo sobre a forte relação (negativa) entre a taxa de desemprego e a razão entre emprego com carteira e população ocupada. Isto é, mais desemprego está associado a menos emprego formal como proporção da população ocupada. Naquela oportunidade, meu ponto principal era mostrar que mesmo para níveis muito baixos de desemprego, o grau de formalização era pouco superior à metade da população ocupada.
Volto ao tema nesse Comentário de Conjuntura, cujos códigos completos estarão disponíveis logo mais no Clube do Código, para revelar que não apenas existe uma correlação forte entre as séries, mas também há uma relação de causalidade unidirecional entre elas, se aplicado às mesmas a metodologia proposta por Toda e Yamamoto (1995). De modo a relembrar, abaixo o código que carrega alguns pacotes e importa o arquivo clt.csv, contendo as séries que utilizei no exercício.
library(magrittr)
library(dplyr)
library(readr)
library(ggplot2)
library(scales)
library(forecast)
library(vars)
library(aod)
### Pacote Seasonal
library(seasonal)
Sys.setenv(X13_PATH = "C:/Séries Temporais/R/Pacotes/seas/x13ashtml")
data = read_csv2('clt.csv',
col_types = list(col_date(format='%d/%m/%Y'),
col_double(), col_double(),
col_double())) %>%
mutate(razao = po_carteira/po*100)
desemprego_sa = ts(data$desemprego, start=c(2002,03), freq=12)
desemprego_sa = final(seas(desemprego_sa))
data = mutate(data, desemprego_sa=desemprego_sa)
E a seguir, um gráfico das séries de desemprego com ajuste sazonal e a razão entre população ocupada com carteira assinada e população ocupada total.
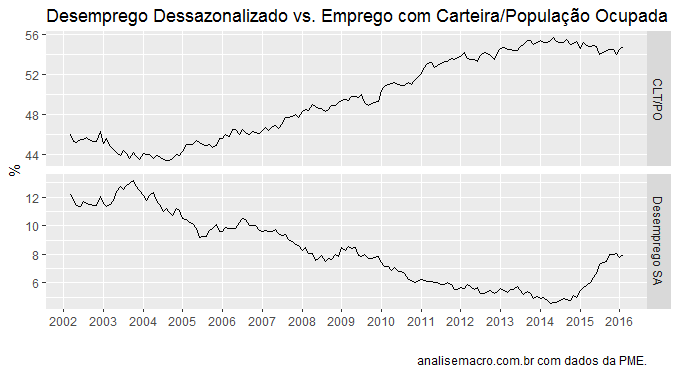
Como mostrei no post anterior, há uma forte correlação negativa entre as séries de -0,93. A relação entre as séries, contudo, não fica apenas nisso. Além de correlacionadas, existe uma relação de causalidade unidirecional entre elas. Para verificar esse ponto, utilizamos a metodologia proposta por Toda e Yamamoto (1995), já que as séries não são estacionárias em nível. O código a seguir implementa o teste.
################ TESTE DE CAUSADALIDE ######################### ### VAR(1) subdata = data[,5:6] var1 <- VAR(subdata, p=1, type='none') serial.test(var1) ### Teste de Wald var2 <- VAR(subdata, p=2, type='none') ### Wald Test 01: Desemprego não granger causa formalização wald.test(b=coef(var2$varresult[[1]]), Sigma=vcov(var2$varresult[[1]]), Terms=2) ### Wald Test 02: formalização não granger causa desemprego wald.test(b=coef(var2$varresult[[2]]), Sigma=vcov(var2$varresult[[2]]), Terms= 1)
De fato, quando a hipótese nula é que o desemprego não granger causa a razão de formalização, temos uma rejeição da mesma. Para o caso contrário, nós não conseguimos essa rejeição. Assim, podemos dizer que mais desemprego causa menos formalização no mercado de trabalho. O que, diga-se, é meio intuitivo. À medida que a taxa de desemprego aumenta, as pessoas costumam se virar, o que aumenta a proporção de emprego informal na população ocupada.
Tudo isso dito, meu ponto no post anterior é bastante simples: mesmo para níveis muito baixos de desemprego, o emprego com carteira alcançou pouco mais da metade da população ocupada. Isso sugere que é impossível universalizar o emprego com carteira assinada para toda a população ocupada.
__________________
Toda H.Y.; Yamamoto T. (1995). Statistical inference in vector autoregressions with possibly integrated processes. Journal of Econometrics, 66, 225–250.


