Ontem, no Relatório AM, falamos um pouco sobre o setor de serviços. Como se sabe, o setor de serviços foi de fato o mais impacto pelas medidas de restrição de mobilidade impostas pelos governos. Imagina-se, por suposto, que a volta à normalidade pré-pandemia tenha impactos positivos sobre esse setor. De modo a vislumbrar essa volta, vamos analisar nesse Comentário de Conjuntura os índices de mobilidade do Google e da Apple, com base no pacote covid19mobility.
library(tidyverse)
library(lubridate)
## Mobility Index
remotes::install_github("covid19r/covid19mobility")
library(covid19mobility)
### Apple Mobility Trends
amt_country = refresh_covid19mobility_apple_country()
amt_country %>%
filter(location == 'Brazil') %>%
select(date, data_type, value) %>%
spread(data_type, value) %>%
drop_na() %>%
group_by(date = floor_date(date, 'month')) %>%
summarise(across(everything(), list(mean))) %>%
gather(variavel, valor, -date) %>%
ggplot(aes(x=date, y=valor, colour=variavel))+
geom_hline(yintercept=100, colour='black', linetype='dashed')+
geom_line(size=.8)+
facet_wrap(~variavel, scales='free')+
theme(legend.position = 'none',
axis.text.x.bottom = element_text(size=7, face='bold'))+
labs(x='', y='',
title='Apple Mobility Trends',
caption='Fonte: analisemacro.com.br')
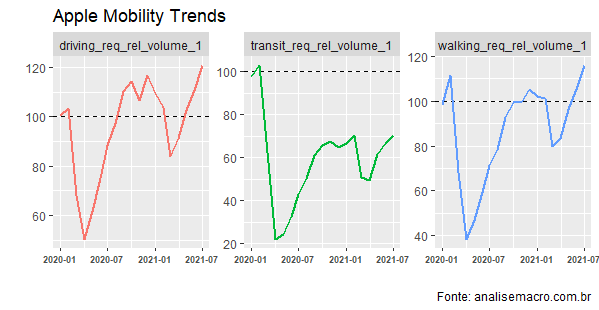
O AMT mostra uma reversão da queda na mobilidade vista ao longo de 2020. O índice base refere-se ao nível pré-pandemia. Como se pode ver pelo gráfico, o item trânsito ainda está aquém do nível pré-pandemia para o agregado do Brasil. Possivelmente, isso explica o fato dos serviços ainda estarem atrás na recuperação do comércio e da indústria.
Outro índice de mobilidade, talvez mais abrangente, seja o do Google. A seguir, ilustramos.
### Google Mobility Trends gmt = refresh_covid19mobility_google_country() gmt %>% filter(location == "Brazil") %>% select(date, data_type, value) %>% drop_na() %>% ggplot(aes(x=date, y=value, colour = data_type))+ geom_hline(yintercept=0, colour='black', linetype='dashed')+ geom_line()+ facet_wrap(~data_type, scales='free')+ theme(legend.position = 'none', strip.text = element_text(size=7, face='bold'), axis.text.x.bottom = element_text(size=7, face='bold'))+ labs(x='', y='', title='Google Mobility Trends', caption='Fonte: analisemacro.com.br')
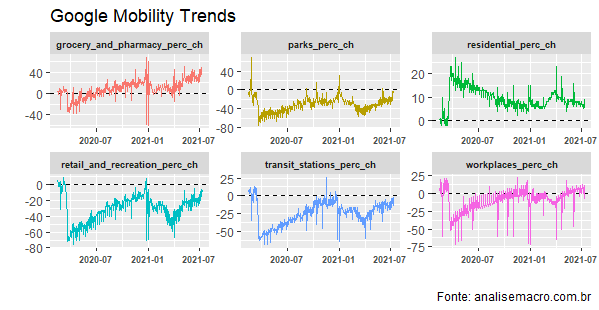
O gráfico acima mostra uma recuperação de lazer e varejo, o item que mais sofreu com as restrições de mobilidade. Esse item é composto por restaurantes, shoppings e similares. As estações de transporte público também estão abaixo do nível pré-pandemia.
A tendência desses índices, por suposto, mostra uma recuperação da mobilidade nos últimos meses, em linha com a recuperação da economia. Os serviços, setor mais impactado, deve acompanhar essa recuperação, mas com alguma defasagem, dado o impacto que sofreu ao longo do ano passado.
De forma a construir uma projeção dos serviços, o Vítor Pestana, Cientista de Dados da área de Produtos aqui na Análise Macro está desenvolvendo um modelo do tipo ARIMAX, onde as co-variáveis são compostas por termos de busca do Google Trends. A seguir, mostramos alguns desses termos.
lazer <- c("restaurante","bar", "cinema", "show", "parque", "academia")
viagem <- c("hotel", "passagem de avião", "passagem de onibus", "aluguel de carro")
emprego <- c("seguro desemprego", "vaga", "currículo","empréstimo")
transporte <- c("onibus", "logistica", "frete", "estrada")
outros <- c("tempo")
Com os termos selecionados, é preciso extrair a informação da API do Google Trends por meio do pacote gtrends. O pacote extrai os dados de forma relativa, ou seja, se for feita uma busca com mais de um termo ao mesmo tempo, os dados serão padronizados em relação ao volume máximo de um dos índices. Por isso, estamos utilizando uma função que extrai os volume de pesquisas termo por termo.
gtrends_clean_mensal <- function(x) {
lista = list()
for (i in x) {
df = gtrends(keyword = i,
geo = "BR", time='all', onlyInterest=TRUE)
df = df$interest_over_time %>%
select(date, hits, keyword)
lista[[i]] = df
}
# diferença em 12 meses
data = bind_rows(lista) %>%
pivot_wider(names_from = keyword, values_from = hits) %>%
mutate_at(vars(-("date")), funs(. - lag(.,12))) %>%
na.omit()
return(data)
}
df_limpo = gtrends_clean_mensal(termos)
Como nosso N é muito reduzido, dado que a PMS começa em 2011, é necessário utilizar algum procedimento para diminuir o número de variáveis. Assim, utilizaremos o *framework* da Análise de Componentes Principais. Iremos selecionar, portanto, os componentes principais de forma que a variância explicada seja ao menos igual a 75%.
A partir disso, rodamos o nosso modelo ARIMAX em uma amostra de treino, avaliamos a acurácia do modelo e geramos as previsões para h períodos. O modelo ainda está em fase de desenvolvimento, mas mostra a validade do uso desse tipo de informação, cada vez mais utilizada para treinar modelos preditivos.
_______________________
(**) Membros do Clube AM têm acesso a detalhes do código que estamos desenvolvendo.

