Pela terceira vez nesse século, a Bovespa acionou o circuit breaker, mecanismo que paralisa os negócios por 30 minutos após uma queda de 10% no índice. O movimento refletiu o aumento da incerteza nos mercados globais, por conta da guerra no mercado de petróleo entre a Arábia Saudita e a Rússia. Eventos como esse são raros de ocorrer, de modo que é possível dizer que o mercado financeiro passou ontem por um forte teste de estresse.
Para ilustrar, vamos considerar a variação percentual entre a mínima do dia e o fechamento no pregão anterior. Para isso, vamos carregar alguns pacotes e pegar os dados que precisaremos para esse comentário.
library(quantmod)
library(BatchGetSymbols)
library(ggplot2)
library(scales)
library(forecast)
library(xts)
library(gridExtra)
library(tidyverse)
## Pegar dados
getSymbols("BRL=X",src="yahoo")
getSymbols("^BVSP",src="yahoo")
getSymbols('VIXCLS', src='FRED')
## Maiores quedas no BOVESPA
first.date = as.Date('2007-01-01')
last.date = as.Date('2020-03-09')
my.assets = c('CSNA3.SA','PETR4.SA', 'MRFG3.SA', 'PETR3.SA')
my.l = BatchGetSymbols(tickers = my.assets,
first.date = first.date,
last.date = last.date)
Uma vez que pegamos os dados, nós fazemos a criação das métricas que precisaremos.
df_ibov = tibble(time=as.Date(time(BVSP)), ibov=BVSP$BVSP.Close) %>% mutate(dibov = (BVSP$BVSP.Close/lag(BVSP$BVSP.Close,1)-1)*100) %>% mutate(variacao = (BVSP$BVSP.Low/lag(BVSP$BVSP.Close,1)-1)*100)
E a seguir, plotamos o gráfico com especial atenção para os eventos de circuit breaker.
ggplot(df_ibov, aes(x=time, y=variacao))+
geom_line()+
geom_hline(yintercept=-10, colour='red', linetype='dashed')+
annotate('text', x=as.Date('2017-05-18'), y=-11,
label='Joesley Day',
colour='darkblue', size=4.5)+
annotate('text', x=as.Date('2020-03-09'), y=-13,
label='Petróleo',
colour='darkblue', size=4)+
annotate('text', x=as.Date('2008-09-15'), y=-16,
label='Subprime',
colour='darkblue', size=4)+
scale_x_date(breaks = date_breaks("6 months"),
labels = date_format("%b/%Y"))+
theme(axis.text.x=element_text(angle=45, hjust=1))+
labs(x='', y='%',
title='Variação do Ibovespa: Mínima do pregão sobre fechamento do pregão anterior (%)',
caption='Fonte: analisemacro.com.br')
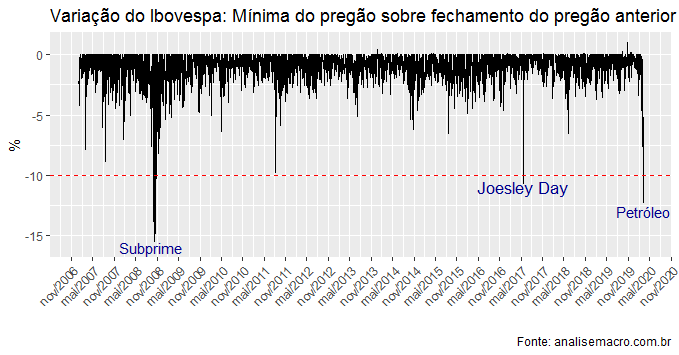
Quedas de mais de 10% em um pregão são raras, como é possível ver na amostra acima. Para um total de 3.268 pregões, apenas em três deles tivemos uma queda maior do que 10%. Foram causados pela crise do subprime nos Estados Unidos em 2008, pelo Joesley Day doméstico e agora pela crise entre os membros da Opep. A seguir, listamos as maiores quedas dentro da BOVESPA.
filter(my.l$df.tickers, ref.date > '2019-01-01') %>%
ggplot(aes(x = ref.date, y = price.close))+
geom_line()+facet_wrap(~ticker, scales = 'free_y')+
scale_x_date(breaks = date_breaks("30 days"),
labels = date_format("%d/%b"))+
theme(axis.text.x=element_text(angle=45, hjust=1))
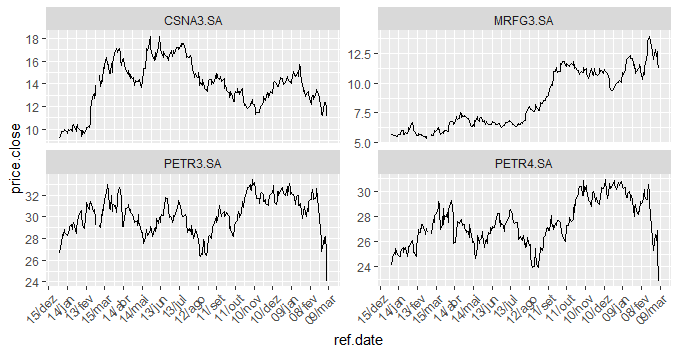
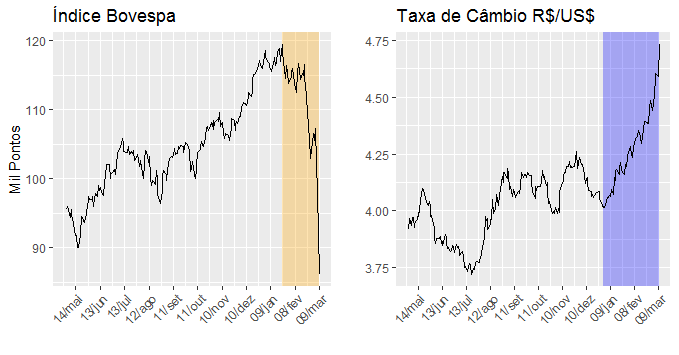
As ações da Petrobras foram as que mais sofreram no pregão de ontem. A PETR3 e a PETR4 caíram 29,68% e 29,70%, respectivamente. Também sofreram perdas grandes a CSNA3 e a MRFG3, com quedas de 25,29% e 23,89%, respectivamente. Em termos gerais, o Ibovespa caiu 12,17% e a taxa de câmbio já é cotado hoje acima de 4,70 R$/US$. Ilustramos a seguir o comportamento das duas séries.
df_cambio = tibble(time=as.Date(time(`BRL=X`)),
cambio = `BRL=X`[,4]) %>%
mutate(log_cambio = diff(log(cambio)))
g1 = filter(df_ibov, time > '2019-05-01') %>%
drop_na() %>%
ggplot(aes(x=time, y=ibov/1000))+
annotate("rect", fill = "orange", alpha = 0.3,
xmin = as.Date('2020-01-23'),
xmax = as.Date('2020-03-09'),
ymin = -Inf, ymax = Inf)+
geom_line()+
scale_x_date(breaks = date_breaks("30 days"),
labels = date_format("%d/%b"))+
theme(axis.text.x=element_text(angle=45, hjust=1))+
labs(x='', y='Mil Pontos',
title='Índice Bovespa')
g2 = filter(df_cambio, time > '2019-05-01') %>%
drop_na() %>%
ggplot(aes(x=time, y=cambio))+
annotate("rect", fill = "blue", alpha = 0.3,
xmin = as.Date('2020-01-01'),
xmax = as.Date('2020-03-10'),
ymin = -Inf, ymax = Inf)+
geom_line()+
scale_x_date(breaks = date_breaks("30 days"),
labels = date_format("%d/%b"))+
theme(axis.text.x=element_text(angle=45, hjust=1))+
labs(x='', y='',
title='Taxa de Câmbio R$/US$')
grid.arrange(g1, g2, ncol=2, nrow=1)
E, por fim, ilustramos o comportamento da volatilidade de ações, com base no índice VIX.
df_vix = tibble(time=as.Date(time(VIXCLS)),
vix = VIXCLS)
filter(df_vix, time > '2018-01-01') %>%
ggplot(aes(x=time, y=vix))+
geom_line()+
scale_x_date(breaks = date_breaks("30 days"),
labels = date_format("%d/%b"))+
theme(axis.text.x=element_text(angle=45, hjust=1))+
labs(x='', y='',
title='VIX Index')
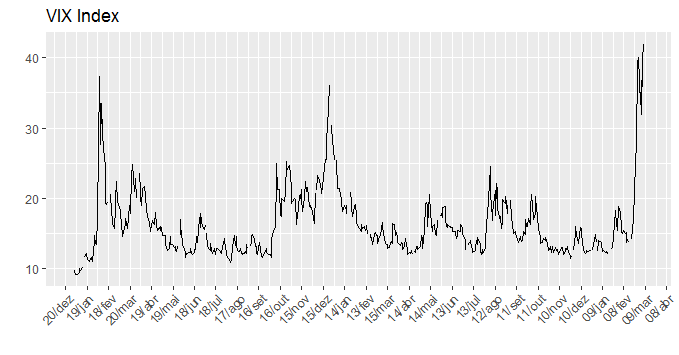
O cenário externo virou de vez. A volatilidade está em níveis bastante elevados. Nesse quadro, é preciso que os poderes Legislativo e Executivo se entendam e deem cabo das reformas que faltam para destravar o ambiente de negócios. Sem isso, corremos um sério risco de cair em uma nova recessão.
___________________
(*) O código completo desse comentário estará disponível logo mais no Clube do Código.
(**) Aprenda a analisar dados financeiros em nosso curso de Econometria Financeira usando o R.
___________________

