Era difícil imaginar, um ano atrás, que passadas as (duras) comemorações de final de ano, ainda estaríamos sujeitos à medidas super restritivas de isolamento social. Era imaginável que, a essa altura, os governos já teriam investido em um misto de hospitais de campanha, que atenuassem o caos no SUS, bem como na compra e distribuição de vacinas para toda a população. Graças, porém, a uma das piores gestões de crise da nossa História, diversas cidades e regiões metropolitanas foram obrigadas a decretar, novamente, em maior ou menor grau, medidas de isolamento social, com dura repercussão sobre o nível de atividade. Como se vê nesse Comentário de Conjuntura, tais medidas foram necessárias porque atingimos o pior momento da pandemia no Brasil.
Membros do Clube AM, por suposto, têm acesso a todos os códigos desse exercício.
Os dados aqui utilizados são do repositório do Wesley Cota. Eles foram importados para o R como abaixo.
## Carregar pacotes
library(tidyverse)
library(tsibble)
library(gridExtra)
## Coletar dados
covid = readr::read_csv("https://raw.githubusercontent.com/wcota/covid19br/master/cases-brazil-states.csv") %>%
select(date, state, newDeaths, newCases, deaths_per_100k_inhabitants,
totalCases_per_100k_inhabitants, deaths_by_totalCases) %>%
tsibble::as_tsibble(index = date, key = state) %>%
group_by(state) %>%
mutate(MM_mortes = zoo::rollmean(newDeaths, k = 7, fill = NA, align = "right"),
MM_casos = zoo::rollmean(newCases, k = 7, fill = NA, align = "right"))
Uma vez que tenhamos os dados no RStudio, podemos criar gráficos para o nível nacional como abaixo.
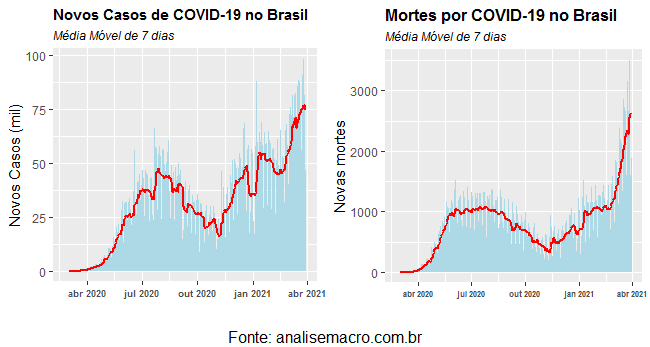
Os gráficos acima mostram uma situação devastadora, fruto da irresponsabilidade e do descaso do governo federal com a maior crise sanitária dos últimos 100 anos. Chegamos, um ano depois do início da pandemia, ao total descontrole da peste.
A média móvel de novos casos em 29/03 chegou a 74,5 mil e a de mortes a 2,6 mil!
São números superlativos que retratam uma tragédia de saúde pública.
A tragédia, diga-se, está espalhada pelo país. A seguir, fazemos um recorte sobre a região Sudeste.
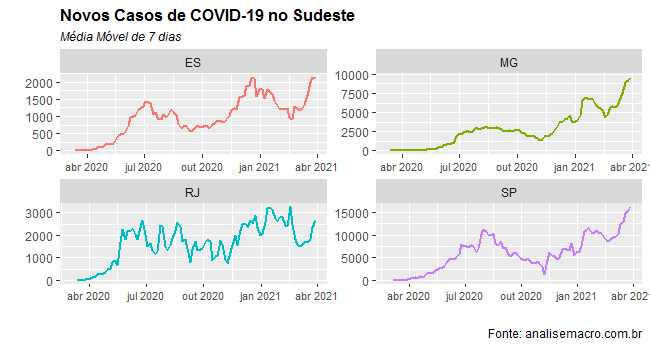
O estado de São Paulo, epicentro da pandemia, chegou a uma média móvel de 16,2 mil novos casos e a 600 mortes pela peste, em 28/3.
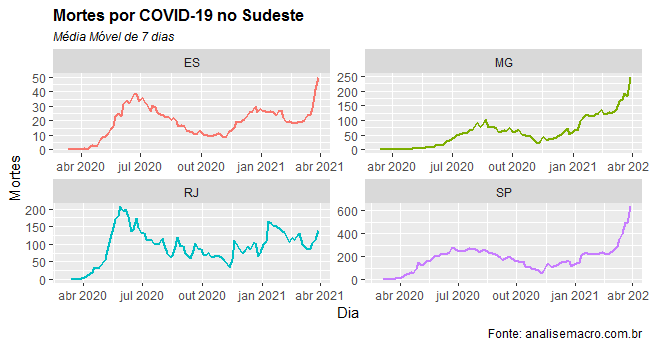
Com a vacinação sendo conduzida a passos de cágado, é difícil imaginar que não seremos obrigados a manter medidas de isolamento social por mais algum tempo no país.
Membros do Clube AM, por suposto, têm acesso a todos os códigos desse exercício.
____________________________


