[et_pb_section admin_label="section"][et_pb_row admin_label="row"][et_pb_column type="1_2"][et_pb_text admin_label="Texto" background_layout="light" text_orientation="justified" text_font="Verdana||||" text_font_size="18" use_border_color="off" border_color="#ffffff" border_style="solid"]
Um dos grandes problemas ao se debater sobre reforma da previdência é a dificuldade de encontrar e tratar os dados. De forma a dar uma contribuição ao debate, com efeito, resolvi nesse sábado de manhã nublado no Rio produzir um pdf para o Clube do Código sobre como tratar dados previdenciários do INSS. A ideia é coletar os dados agregados referentes à despesa e receita diretamente da Secretaria do Tesouro Nacional, deflacionar esses dados com o IPCA, retirar a sazonalidade, de modo a visualizar os dados mais "limpos" e, por fim, anualizar os mesmos, de modo a produzir o gráfico abaixo, que ilustra o déficit da previdência ao longo do tempo. É, a propósito, o tipo de coisa que fazemos em nosso Curso de Analise de Conjuntura usando o R.
[/et_pb_text][/et_pb_column][et_pb_column type="1_2"][et_pb_image admin_label="Imagem" src="https://analisemacro.com.br/wp-content/uploads/2019/02/loteextra2.png" show_in_lightbox="off" url="https://analisemacro.com.br/cursos-de-r/" url_new_window="off" use_overlay="off" animation="off" sticky="off" align="center" force_fullwidth="off" always_center_on_mobile="on" use_border_color="off" border_color="#ffffff" border_style="solid"]
[/et_pb_image][/et_pb_column][/et_pb_row][et_pb_row admin_label="row"][et_pb_column type="4_4"][et_pb_text admin_label="Texto" background_layout="light" text_orientation="justified" text_font="Verdana||||" text_font_size="18" use_border_color="off" border_color="#ffffff" border_style="solid"]
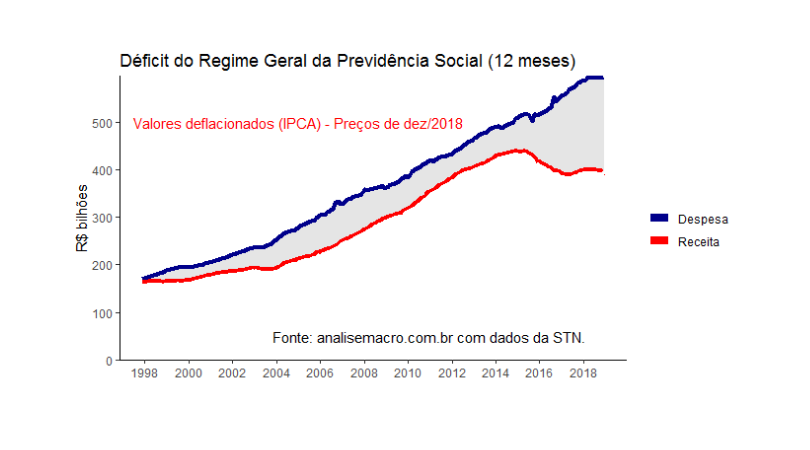
O gráfico acima ilustra muito bem o comportamento da despesa e da receita previdenciária referente ao INSS ao longo do tempo. Como eu disse acima, porém, para chegar nele é preciso um bom trabalho de tratamento dos dados. Para começar, vamos baixar os dados referentes ao resultado primário do governo central, de onde podemos extrair os dados agregados do INSS. O código abaixo ilustra.
library(readxl)
url = 'https://bit.ly/2N9vtOh'
download.file(url, 'primario.xlsx', mode='wb')
data = read_excel('primario.xlsx', sheet='1.1', skip=4,
col_types = c('text', rep('numeric', 264)))
previdencia = t((data[c(14,36),-1]))
A matriz previdencia contém, então, os dados agregados de receita e despesa do INSS. Abaixo, para ilustrar para o leitor como a vida é dura, podemos ver como esses dados estão...
Muitos problemas, não é mesmo? Para começar, os dados estão em valores correntes ou nominais. Isso significa que não estamos considerando a inflação do período, de modo que não faz sentido comparar o dinheiro do ano x com o do ano y. Assim, precisamos deflacionar os mesmos. Para isso, porém, precisamos de um deflator. Vamos usar aqui o IPCA, que pode ser baixado do IBGE como no código abaixo.
library(sidrar) ### Importar IPCA ipca = get_sidra(api='/t/1737/n1/all/v/2266/p/all/d/v2266%2013') ipca = ts(ipca$Valor, start=c(1979,12), freq=12) ipca = window(ipca, start=c(1997,01), end=c(2018,12)) ### Deflacionar Dados nominal = ts(previdencia[,2:3], start=c(1997,01), freq=12) real = ipca[length(ipca)]*(nominal/ipca)
Agora, temos uma matriz com os valores nominais e outra com os valores reais. O gráfico a seguir ilustra os valores reais.
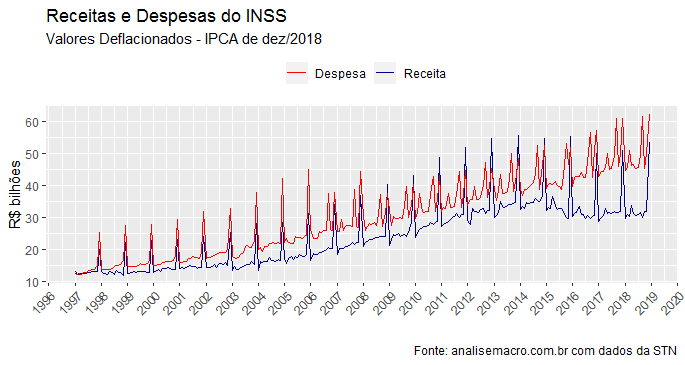
Observe que em termos reais, a despesa continua acima da receita, mas repare que na ponta há uma queda em termos reais da receita (por quê?). Isso dito, observe que a visualização do gráfico ainda não é muito boa por conta da sazonalidade da série. Podemos fazer um ajuste sazonal nela, apenas como exercício, com o código abaixo.
### Pacote Seasonal library(seasonal) Sys.setenv(X13_PATH = "C:/Séries Temporais/R/Pacotes/seas/x13ashtml") ## Dessazonalizar Dados receita = final(seas(real[,1])) despesa = final(seas(real[,2])) realsa = ts.intersect(receita,despesa)
A seguir, um gráfico para ilustrar os dados dessazonalizados...
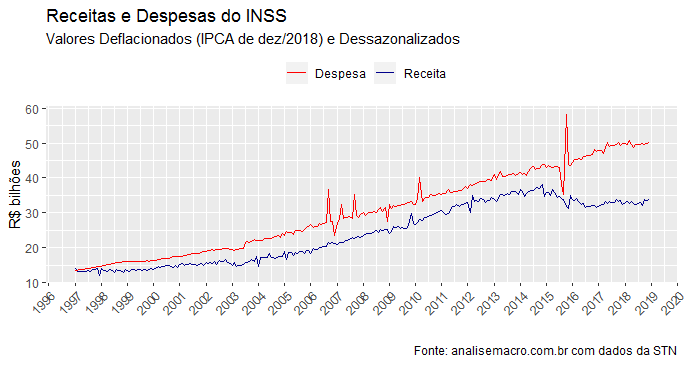
Com os dados deflacionados e dessazonalizados, fica bem melhor a visualização, não é mesmo? Observe que uma coisa é bastante perceptível: as séries possuem uma tendência positiva ao longo do tempo. De fato, se você quiser criar uma taxa de crescimento, verá que elas crescem em média acima de 6% a.a., em termos reais!! Por fim, podemos gerar o primeiro gráfico desse post, de modo a suavizar ainda mais a nossa série, anualizando os dados com o código a seguir.
### Acumular em 12 meses real12 = real+lag(real,-1)+lag(real,-2)+lag(real,-3)+ lag(real,-4)+lag(real,-5)+lag(real,-6)+lag(real,-7)+ lag(real,-8)+lag(real,-9)+lag(real,-10)+lag(real,-11)
Observe que, primeiro, eu deflacionar os dados mensais e só depois acumulei eles em 12 meses. Com a matriz real12, por fim, podemos gerar aquele primeiro gráfico do post que ilustra perfeitamente a tendência de crescimento da despesa ao longo do tempo.
Com os dados tratados, podemos avançar para a próxima etapa da análise de dados que é construir um modelo para os gastos previdenciários. Isso fica para um próximo post! 🙂
O pdf completo estará disponível no Clube do Código na próxima semana!
_____________________________________
Conheça nossos Cursos Aplicados de R e aprenda a coletar, tratar, analisar e apresentar dados com o R!
[/et_pb_text][/et_pb_column][/et_pb_row][/et_pb_section]

