[et_pb_section admin_label="section"][et_pb_row admin_label="row"][et_pb_column type="4_4"][et_pb_text admin_label="Texto" background_layout="light" text_orientation="justified" text_font="Verdana||||" text_font_size="18" use_border_color="off" border_color="#ffffff" border_style="solid"]
Em palestra recente na UFMS, um aluno citou um documento intitulado Livro Verde para justificar o fato do BNDES emprestar mais para Micro, Pequenas e Médias Empresas (MPMEs) do que para Grandes Empresas. Disse na oportunidade que isso não era verdade, que os dados dizem justamente o contrário. Só hoje, porém, em uma manhã de sábado nublada no RJ, consegui parar para mostrar a evidência disso. Os dados utilizados são públicos, disponibilizados na página do Banco, em Transparência e depois em Central de Downloads - ver aqui. Como de hábito, importo os dados com o código abaixo, utilizando o  :
:
## Carregar pacotes
library(XLConnect)
library(xts)
library(reshape2)
library(scales)
library(ggplot2)
## Importar e tratar dados
temp = tempfile()
download.file('http://bit.ly/2FOGP5Y', destfile=temp, mode='wb')
bndes = loadWorkbook(temp)
rm(temp)
bndes = readWorksheet(bndes, sheet=1, startRow=5,
startCol=4, header=T)[,-5]
colnames(bndes) = c('micro', 'pequena', 'media', 'grande', 'total')
bndes = bndes[complete.cases(bndes),]
bndes <- bndes[-c(13,13*2, 13*3, 13*4, 13*5, 13*6, 13*7, 13*8,
13*9,13*10, 13*11, 13*12, 13*13, 13*14, 13*15,
13*16, 13*17,nrow(bndes)),]
O código acima importa e trata os dados de desembolsos do BNDES por porte da empresa. Abaixo, eu somo os desembolsos das MPMEs e divido pelo total de desembolsos, de modo a obter a participação mensal das mesmas. Faço o mesmo para as grandes empresas.
## Criar variáveis mpme = rowSums(bndes[,1:3])/bndes[,5]*100 grande = (bndes[,4])/bndes[,5]*100
Por fim, crio um gráfico de área de modo a ilustrar a participação de cada grupo no total de desembolsos.
## Criar gráfico
dates = seq(as.Date('2001-01-01'), as.Date('2018-01-01'),
by='1 month')
df = data.frame(mpme=mpme, grande=grande)
df = xts(df, order.by=dates)
df = data.frame(time=index(df), melt(as.data.frame(df)))
ggplot(df, aes(x = time, y = value)) +
geom_area(aes(colour = variable, fill = variable))+
xlab('')+ylab('Participação Percentual')+
labs(title='Desembolsos do BNDES: Grandes vs. MPME',
caption='Fonte: analisemacro.com.br com dados do BNDES')+
theme(legend.position = 'bottom',
legend.title=element_blank())+
scale_x_date(breaks = date_breaks("1 years"),
labels = date_format("%Y"))
E o gráfico...
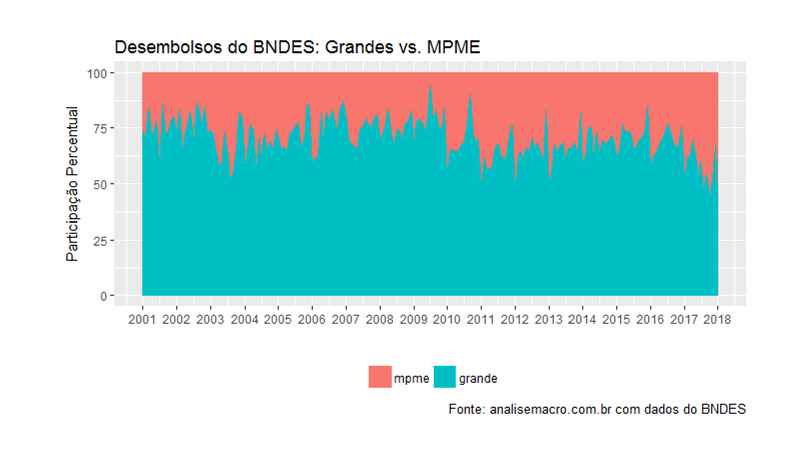
Pronto: a evidência do que eu afirmei na palestra está aí... 🙂
[/et_pb_text][et_pb_image admin_label="Imagem" src="https://analisemacro.com.br/wp-content/uploads/2017/11/cursosaplicados.png" show_in_lightbox="off" url="https://analisemacro.com.br/cursos-de-r/" url_new_window="off" use_overlay="off" animation="off" sticky="off" align="left" force_fullwidth="off" always_center_on_mobile="on" use_border_color="off" border_color="#ffffff" border_style="solid"]
[/et_pb_image][/et_pb_column][/et_pb_row][/et_pb_section]

