Uma das grandes vantagens de usar R é poder facilitar sua vida no momento de coletar e tratar dados. Para ilustrar, vamos supor, por exemplo, que tenhamos um arquivo .csv com dados de aprovação/desaprovação do governo federal. Vamos importar essa planilha para o R e mostrar um grande problema que ela tem.
data <- read.table('governo.csv', sep=';', dec=',', header=T)
data$DATE <- as.Date(data$DATE, format="%d/%m/%Y")
data <- xts(data[,c(2:4)], order.by = data$DATE)
Se plotarmos as colunas 1 e 2 do objeto data, respectivamente, aprovação e desaprovação do governo federal, obteremos algo como abaixo.
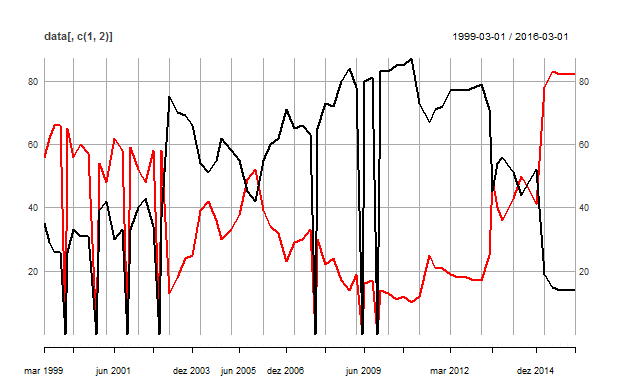
Repare que o gráfico tem um grande problema. Por algum motivo, nosso arquivo .csv tem valores nulos em algumas linhas. Provavelmente porque nessas datas, não houve pesquisa de opinião. Isso tornar o gráfico poluído, não é mesmo? Para resolver isso, basta que retiremos esses valores do nosso objeto data. Isso é feito com a linha de código abaixo.
data <- data[!data$APROVA==0,]
Uma vez feito isso, podemos, agora assim, fazer um gráfico mais bonitinho com o código abaixo.
p <- autoplot(data[,c(1,2)], facets = F)
p + scale_colour_hue("Legenda",
labels=c('Aprovação',
'Desaprovação')) +
ggtitle('Aprovação vs. Desaprovação do Governo Federal (%)')
E o resultado abaixo...
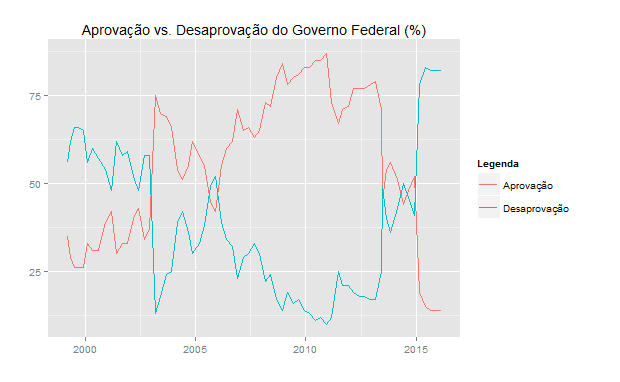
Bem melhor, não? 🙂 O arquivo .csv aqui e o script do R aqui.
________________________________________________________________
Gostou? Veja nosso Curso de Introdução ao R. Aprenda a coletar, tratar, analisar e apresentar dados de forma bem mais produtiva!

