[et_pb_section admin_label="section"][et_pb_row admin_label="row"][et_pb_column type="4_4"][et_pb_text admin_label="Texto" background_layout="light" text_orientation="justified" text_font="Verdana||||" text_font_size="18" use_border_color="off" border_color="#ffffff" border_style="solid"]
É com enorme felicidade que tenho visto a maior penetração do R no país. Ao longo das últimos meses, por onde passo, sou abordado por pessoas que conhecem a Análise Macro e estão interessadas em aprender o R. Passados dois anos do início desse projeto - sim, estamos comemorando dois anos! -, não deixa de ser bastante auspicioso verificar o avanço do uso da linguagem entre estudantes, profissionais de mercado e professores. Uma das formas de avaliar esse avanço, diga-se, é na produção de pacotes para coleta de dados nas principais bases do país. Nesse post, vou falar dos pacotes atualmente disponíveis para pegar dados do IPEADATA, FGV, IBGE e Banco Central. Caso tenha esquecido de algum, por favor, deixe aí nos comentários!
BETS
O pacote que mais tenho utilizado atualmente para pegar dados dessas bases é o BETS, pacote produzido pelo pessoal da FGV. Está disponível no CRAN e tem se mostrado bastante estável, à medida que alguns bugs foram corrigidos. Ele pode ser utilizado para pegar dados do Banco Central, IBGE e da FGV. Um vignette do pacote está disponível aqui.
library(BETS) BETS.chart(ts = 'iie_br', file = "iie_br", open = TRUE)
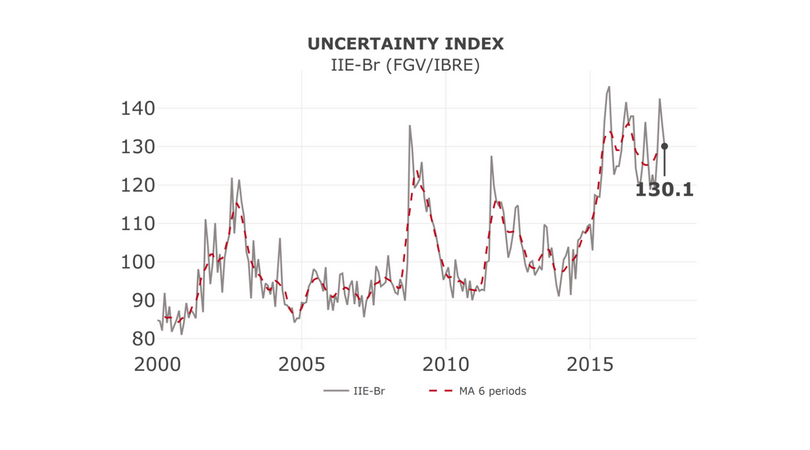
rbcb
Outro pacote que tenho utilizado é o rbcb, produzido pelo Wilson Freitas. Ele serve, como o próprio nome já entrega, para coletar dados do Banco Central.
library(rbcb) library(ggplot2) ipca = get_series(433) ggplot(ipca, aes(x=date))+ geom_line(aes(y=ipca$`433`), col='darkblue')
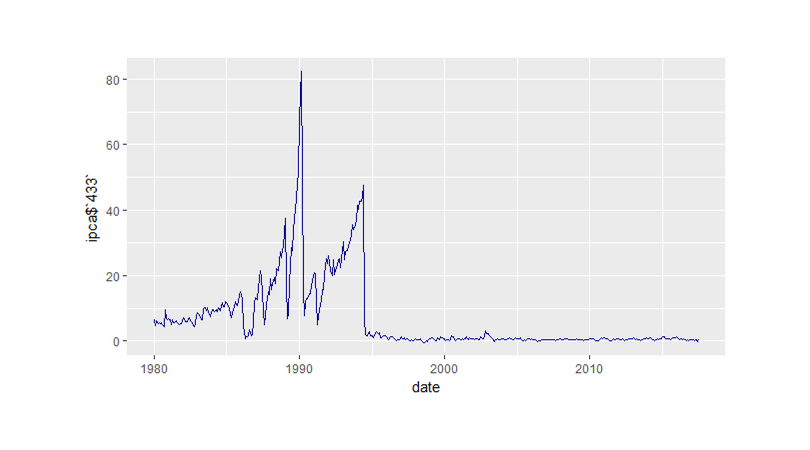 ribge
ribge
Um pacote que conheci recentemente foi o ribge, que ainda está em fase de desenvolvimento, disponível no GitHub. Tomare que ao longo dos próximos meses esteja plenamente funcional!
ecoseries
Por fim, outro pacote que também coleta dados do SIDRA IBGE, Banco Central e IPEADATA é o ecoseries, disponível no CRAN.
library(ecoseries)
library(BETS)
library(ggplot2)
library(forecast)
ipca = window(ts(series_ipeadata('36482',
periodicity = 'M')$serie_36482$valor,
start=c(1979,12), freq=12), start=c(1999,08))
base = window(BETS.get(1833), start=c(1999,08))
data = ts.intersect(base, ipca)
par(mar=c(5,4,4,5)+.1)
plot(data[,1]/1000000, xlim=c(2000,2017), xlab='', ylab='Base Monetária',
col='red', lty=1, lwd=2)
par(new=T)
plot(data[,2], xlim=c(2000,2017), xlab='', ylab='',
xaxt='n',yaxt='n', col='blue', lty=1, lwd=2)
axis(4)
mtext('IPCA',side=4,line=3)
mtext('Base Monetária vs. IPCA', side=3, line=1, font=2)
mtext('Fonte: analisemacro.com.br com dados do IPEA e do BCB.',
side=1, line=3, font=1)
legend('topleft', col=c('red','blue'), lty=c(1,1), lwd=c(2,2),
legend=c('Base', 'IPCA'))
grid()
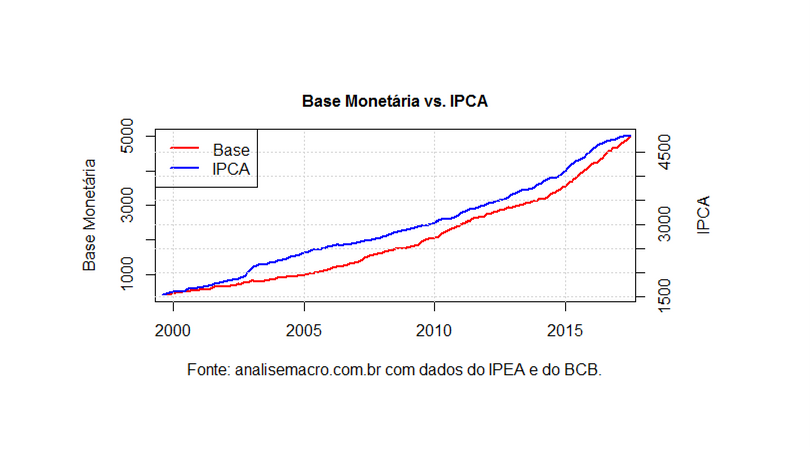
Na minha visão, o R e outras linguagens como o Python serão cada vez mais utilizadas no país, seja para fazer coleta de dados como os exemplos aqui, seja para facilitar/automatizar a vida dos analistas. E, claro, o momento de se tornar fluente nessas linguagens é agora! 🙂
[/et_pb_text][/et_pb_column][/et_pb_row][et_pb_row admin_label="row"][et_pb_column type="1_3"][et_pb_image admin_label="Imagem" src="https://analisemacro.com.br/wp-content/uploads/2017/05/econometria2.png" show_in_lightbox="off" url="https://analisemacro.com.br/cursos-de-r/cursos-de-econometria/" url_new_window="off" use_overlay="off" animation="left" sticky="off" align="center" force_fullwidth="off" always_center_on_mobile="on" use_border_color="off" border_color="#ffffff" border_style="solid"]
[/et_pb_image][/et_pb_column][et_pb_column type="1_3"][et_pb_image admin_label="Imagem" src="https://analisemacro.com.br/wp-content/uploads/2017/11/datascience.png" show_in_lightbox="off" url="https://analisemacro.com.br/cursos-de-r/" url_new_window="off" use_overlay="off" animation="left" sticky="off" align="center" force_fullwidth="off" always_center_on_mobile="on" use_border_color="off" border_color="#ffffff" border_style="solid"]
[/et_pb_image][/et_pb_column][et_pb_column type="1_3"][et_pb_image admin_label="Imagem" src="https://analisemacro.com.br/wp-content/uploads/2016/04/canva03.png" show_in_lightbox="off" url="https://analisemacro.com.br/cursos-de-r/macroeconomia-aplicada/" url_new_window="off" use_overlay="off" animation="left" sticky="off" align="center" force_fullwidth="off" always_center_on_mobile="on" use_border_color="off" border_color="#ffffff" border_style="solid"]
[/et_pb_image][/et_pb_column][/et_pb_row][/et_pb_section]

