No nosso Curso de Teoria Macroeconômica com Laboratórios de R, incentivamos nossos alunos a aplicarem os conhecimentos de R aprendidos em laboratórios aplicados. Para ilustrar o que vemos no Curso, vou mostrar o laboratório 5, onde é solicitado aos alunos a coleta e tratamento dos dados de poupança e da Formação Bruta de Capital com o R.
O código abaixo pega os dados diretamente do SIDRA/IBGE:
## Importação dos dados da poupança e da fbc library(sidrar) data = get_sidra(api='/t/2072/n1/all/v/933,940,941/p/all')
Na sequência, nós fazemos a organização dos dados.
library(tidyverse) library(lubridate) library(zoo) dados <- data %>% select(`Trimestre (Código)`, Variável, Valor) %>% pivot_wider(names_from=Variável, values_from=Valor) %>% mutate(date=as.yearqtr(parse_date_time(`Trimestre (Código)`, '%y%q'))) %>% select(-`Trimestre (Código)`)
Com os dados organizados, nós podemos anualizá-los com o código abaixo.
anuais <- dados %>% mutate(`Produto Interno Bruto` = rollsum(`Produto Interno Bruto`, k=4, align='right', fill=NA), `(=) Poupança bruta` = rollsum(`(=) Poupança bruta`, k=4, align='right', fill=NA), `(-) Formação bruta de capital` = rollsum(`(-) Formação bruta de capital`, k=4, align='right', fill=NA))
Por fim, nós normalizamos nossos dados pelo PIB de forma poder compará-los.
pct <- anuais %>% mutate(FBC=`(-) Formação bruta de capital`/`Produto Interno Bruto`*100, Poupança=`(=) Poupança bruta`/`Produto Interno Bruto`*100, .keep='unused')
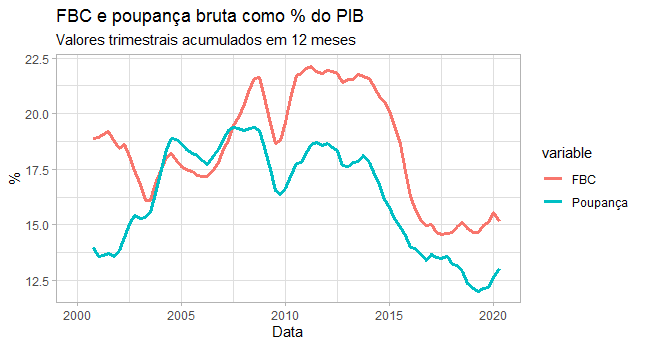
O gráfico abaixo ilustra as séries obtidas.
 ________________
________________
(*) Isso e muito mais você irá aprender no nosso Curso de Teoria Macroeconômica com Laboratórios de R.


