Introdução
Neste exercício mostramos como dar os primeiros passos para acessar dados brasileiros de fontes públicas, disponibilizados nas volumosas bases do BCB, IPEADATA e IBGE. Estas fontes constituem um ativo valiosíssimo para pesquisadores e profissionais de mercado - além de ser um “parquinho de diversões” para amantes de dados -, sendo fundamental o domínio de linguagens de programação como o R para coleta e automatização de rotinas.
Para obter o código e o tutorial deste exercício faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
Dados do BCB
Existem diversas bases de dados que o Banco Central do Brasil (BCB) disponibiliza para acesso público, dentre elas:
- Sistema Gerenciador de Séries Temporais (SGS): milhares de séries econômico-financeiras de diversas fontes;
- Sistema Expectativas de Mercado: dados de expectativas de agentes de mercado para indicadores econômicos, compilados no Relatório Focus.
E para acessar estes dados pela linguagem R podemos utilizar o pacote {rbcb}.
{rbcb}: interface para acessar API’s do SGS, Sistema de Expectativas e dados de taxa de câmbio;
Sistema Gerenciador de Séries Temporais (SGS)
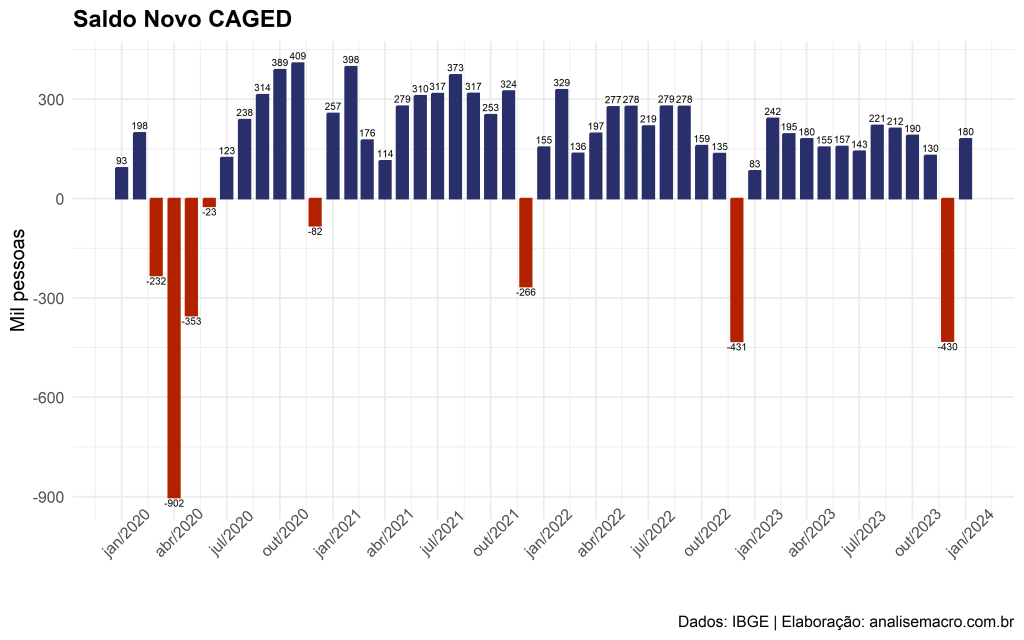
Vamos a um exemplo: suponha que você queira coletar uma série temporal do SGS/BCB (usaremos o código 432 da taxa SELIC no exemplo).
- Passo 1: localize no site https://www3.bcb.gov.br/sgspub/ o código da série desejada;
- Passo 2: utilizando o pacote
{rbcb}, aponte na funçãoget_series()o código e período desejado, observando a documentação dos argumentos desta função, o resultado é exposto conforme abaixo:
Código
# A tibble: 6 × 2
date selic
<date> <dbl>
1 2023-12-26 11.8
2 2023-12-27 11.8
3 2023-12-28 11.8
4 2023-12-29 11.8
5 2023-12-30 11.8
6 2023-12-31 11.8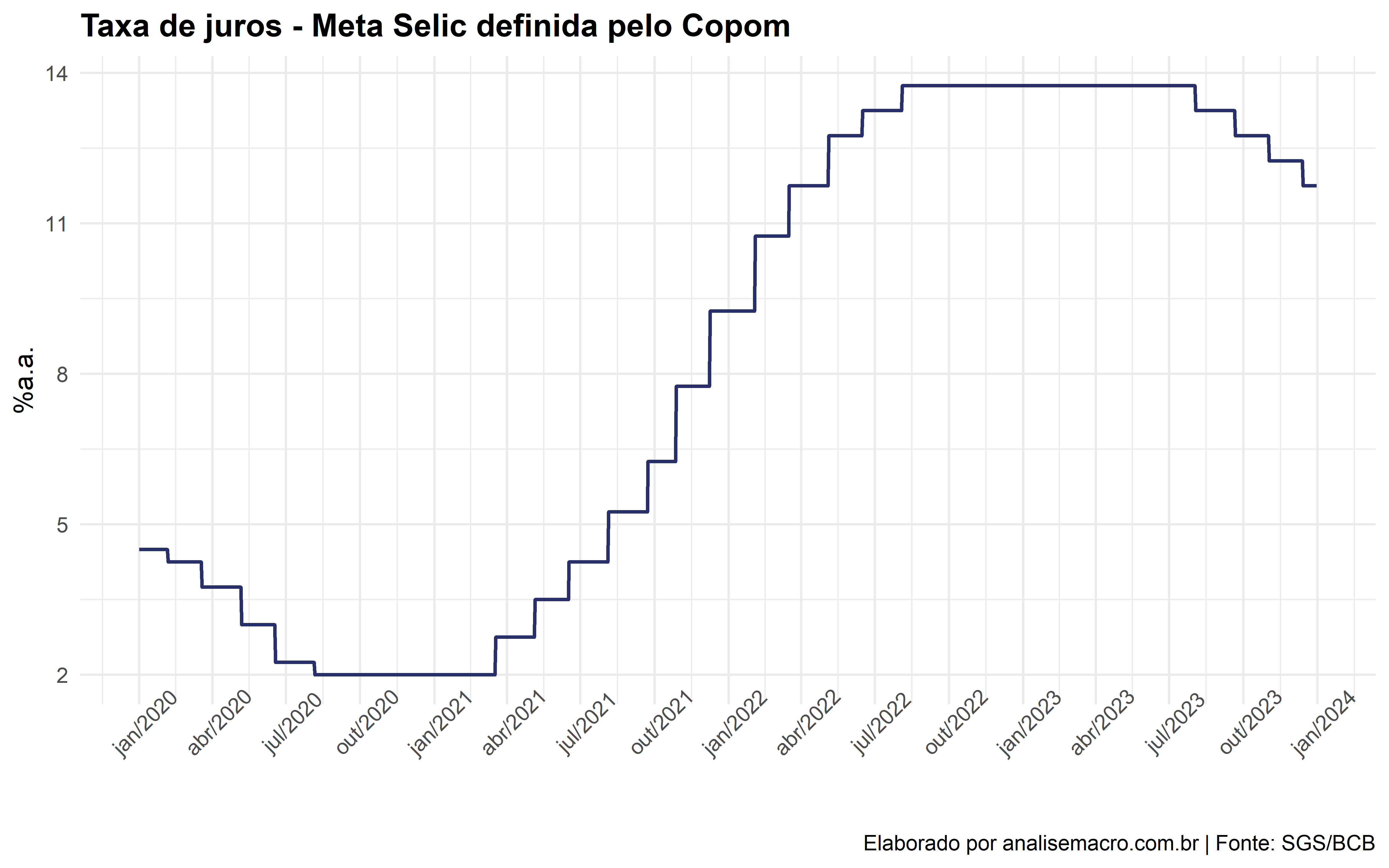
Sistema Expectativas de Mercado
Aprenda a coletar, processar e analisar dados na formação de Do Zero à Análise de Dados Econômicos e Financeiros com a linguagem R.
No segundo exemplo mostramos como obter dados do Sistema Expectativas de Mercado.
- Passo 1: Checar a série de interesse conforme a documentação do sistema de Expectativas do BCB através do site https://olinda.bcb.gov.br/olinda/servico/Expectativas/versao/v1/documentacao
- Passo 2: Usar a função
get_market_expectationspara retornar as expectativas de mercado discutidas no Relatório Focus que resume as estatísticas calculadas a partir das expectativas coletadas junto aos profissionais de mercado.
A função aceita como argumento as seguintes pesquisas:
annual: expectativas anuaisquarterly: expectativas trimestraismonthly: expectativas mensaistop5s-monthly: monthly: expectativas mensais para os top 5 indicadorestop5s-annual: expectativas anuais para os top 5 indicadoresinflation-12-months: expectativas de inflação para os próximos 12 mesesinstitutions: expectativas de mercado informadas por instituições financeiras
O gráfico abaixo mostra o resultado da importação das expectativas anuais do IPCA.

Dados do IPEADATA
O IPEADATA oferece um grande volume de dados com acesso público, organizados nos seguintes temas:
- Macroeconômico: dados econômicos e financeiros do Brasil em séries anuais, mensais e diárias na mesma unidade monetária;
- Regional: dados econômicos, demográficos e geográficos para estados, municípios (e suas áreas mínimas comparáveis), regiões administrativas e bacias hidrográficas brasileiras;
- Social: dados e indicadores sobre distribuição de renda, pobreza, educação, saúde, previdência social e segurança pública.
E para acessar estes dados no R existe o pacote {ipeadatar}, que possibilita ler e pesquisar metadados e extrair variáveis de interesse.
Vamos a um exemplo: suponha que você queira coletar a série do saldo do Novo CAGED.
- Passo 1: utilize a função
available_series()para localizar a série desejada e obter o código da mesma (retorna umtibble);
Código
# A tibble: 10 × 7
code name theme source freq lastupdate status
<chr> <chr> <fct> <fct> <fct> <date> <fct>
1 CAGED12_ADMIS Empregados - admissõe… Macr… MTE/C… Mont… 2020-05-27 "Inac…
2 CAGED12_DESLIG Empregados - demissõe… Macr… MTE/C… Mont… 2020-05-27 "Inac…
3 CAGED12_SALDO12 Empregados - saldo - … Macr… MTE/C… Mont… 2020-05-27 "Inac…
4 CAGED12_ADMISN12 Empregados - admissõe… Macr… Min. … Mont… 2024-03-20 "Acti…
5 CAGED12_DESLIGN12 Empregados - demissõe… Macr… Min. … Mont… 2024-03-20 "Acti…
6 CAGED12_SALDON12 Empregados - saldo - … Macr… Min. … Mont… 2024-03-20 "Acti…
7 ADMIS Empregados - admissõe… Regi… MTE/C… Mont… 2020-07-07 ""
8 ADMISNC Empregados - admissõe… Regi… MTE/C… Mont… 2024-03-26 ""
9 DESLIG Empregados - demissõe… Regi… MTE/C… Mont… 2020-07-07 ""
10 DESLIGNC Empregados - demissõe… Regi… MTE/C… Mont… 2024-03-26 "" - Passo 2: aponte na função
ipeadata()o(s) código(s) da(s) séries(s), e realize a importação. Podemos verificar o gráfico da variável importada abaixo:
Código
# A tibble: 6 × 5
code date value uname tcode
<chr> <date> <dbl> <ord> <int>
1 CAGED12_SALDON12 2023-08-01 220844 "" NA
2 CAGED12_SALDON12 2023-09-01 211764 "" NA
3 CAGED12_SALDON12 2023-10-01 190366 "" NA
4 CAGED12_SALDON12 2023-11-01 130097 "" NA
5 CAGED12_SALDON12 2023-12-01 -430159 "" NA
6 CAGED12_SALDON12 2024-01-01 180395 "" NA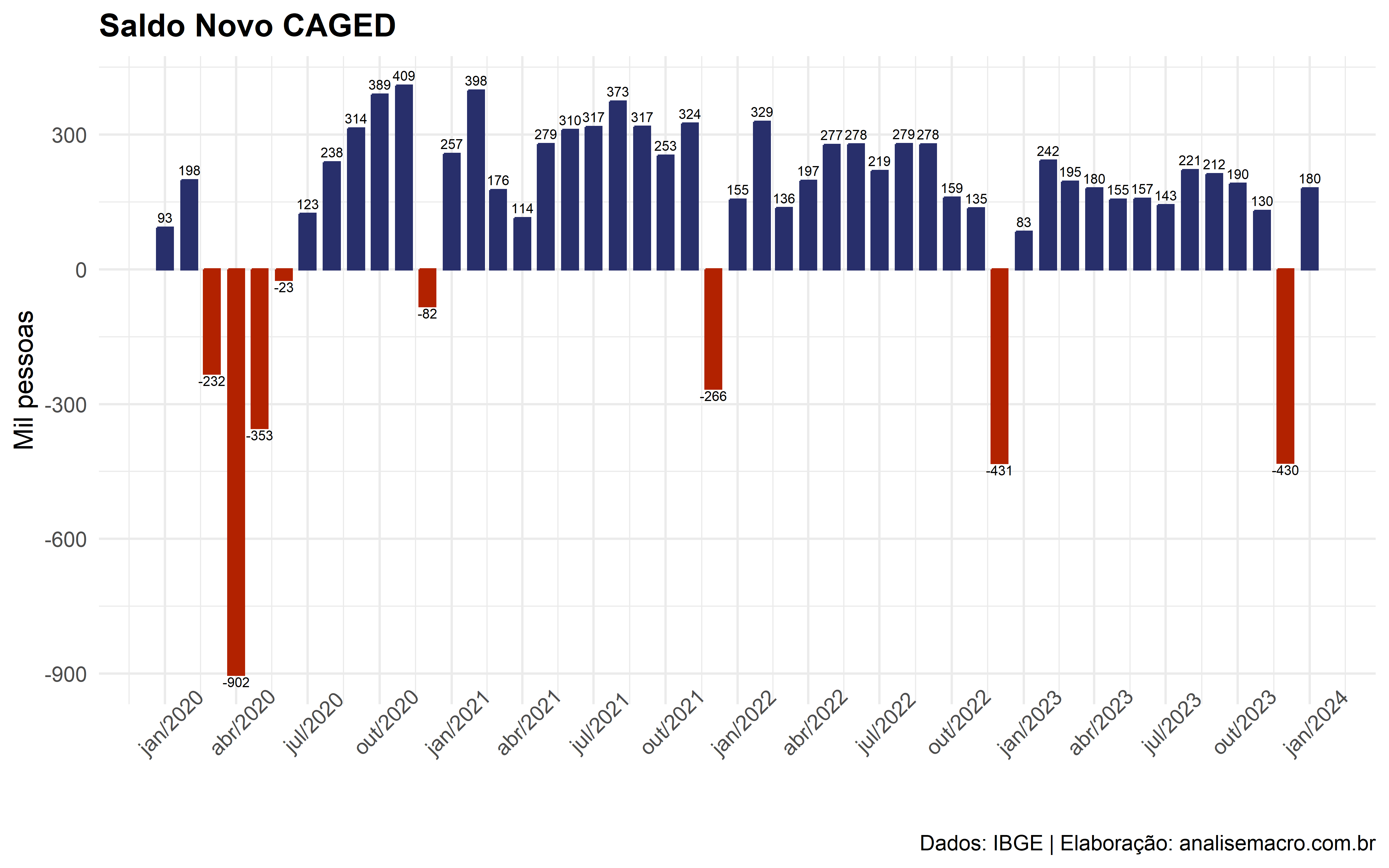
Dados do Sidra/IBGE
O Sidra é um sistema disponibilizado pelo IBGE com bases de dados públicas dos mais variados temas, organizados em tabelas agregadas (não identificam o informante). Estes dados são oriundos das pesquisas e diversos trabalhos que a instituição realiza, podendo conter informações atreladas a nível territorial, a um período de tempo, a classificações ou a unidades de medida/cálculos estatísticos.
Para acessar estes dados no R existe o pacote {sidrar}, que possibilita pesquisar tabelas, obter informações de parâmetros de consulta e extrair dados de tabelas de interesse.
Vamos a um exemplo: suponha que você queira coletar dados de uma tabela do Sidra/IBGE (usaremos a tabela 7060 referente ao IPCA no exemplo). Você pode usar o próprio pacote para especificar uma consulta com filtros ou construir essa consulta diretamente no site do Sidra (mais fácil), obtendo um código de consulta.
- Passo 1: localize no site https://sidra.ibge.gov.br/ a tabela de interesse e aplique os filtros desejados (neste caso usaremos a tabeça 7060, marcamos “Variável” = “IPCA - Variação acumulada em 12 meses (%)”; “Geral, grupo, subgrupo, item e subitem” = “Índice geral”; “Mês” = todos períodos disponíveis e “Unidade Territorial” = “Brasil”);
- Passo 2: clique no botão de compartilhar na parte inferior chamado “Links de compartilhar” e, na tela que se abre, copie o código a partir de “/t/” (inclusive) até o final;
- Passo 3: aponte na função
get_sidra(), usando o argumentoapi, o código de consulta obtido no passo anterior, conforme abaixo:
Código
# A tibble: 6 × 13
`Nível Territorial (Código)` `Nível Territorial` `Unidade de Medida (Código)`
<chr> <chr> <chr>
1 1 Brasil 2
2 1 Brasil 2
3 1 Brasil 2
4 1 Brasil 2
5 1 Brasil 2
6 1 Brasil 2
# ℹ 10 more variables: `Unidade de Medida` <chr>, Valor <dbl>,
# `Brasil (Código)` <chr>, Brasil <chr>, `Variável (Código)` <chr>,
# Variável <chr>, `Mês (Código)` <chr>, Mês <chr>,
# `Geral, grupo, subgrupo, item e subitem (Código)` <chr>,
# `Geral, grupo, subgrupo, item e subitem` <chr>Dessa forma simples conseguimos acesso rápido e fácil aos dados de qualquer tabela do Sidra. Consulte os detalhes e mais opções na documentação do pacote e, sobre as tabelas, no site da instituição.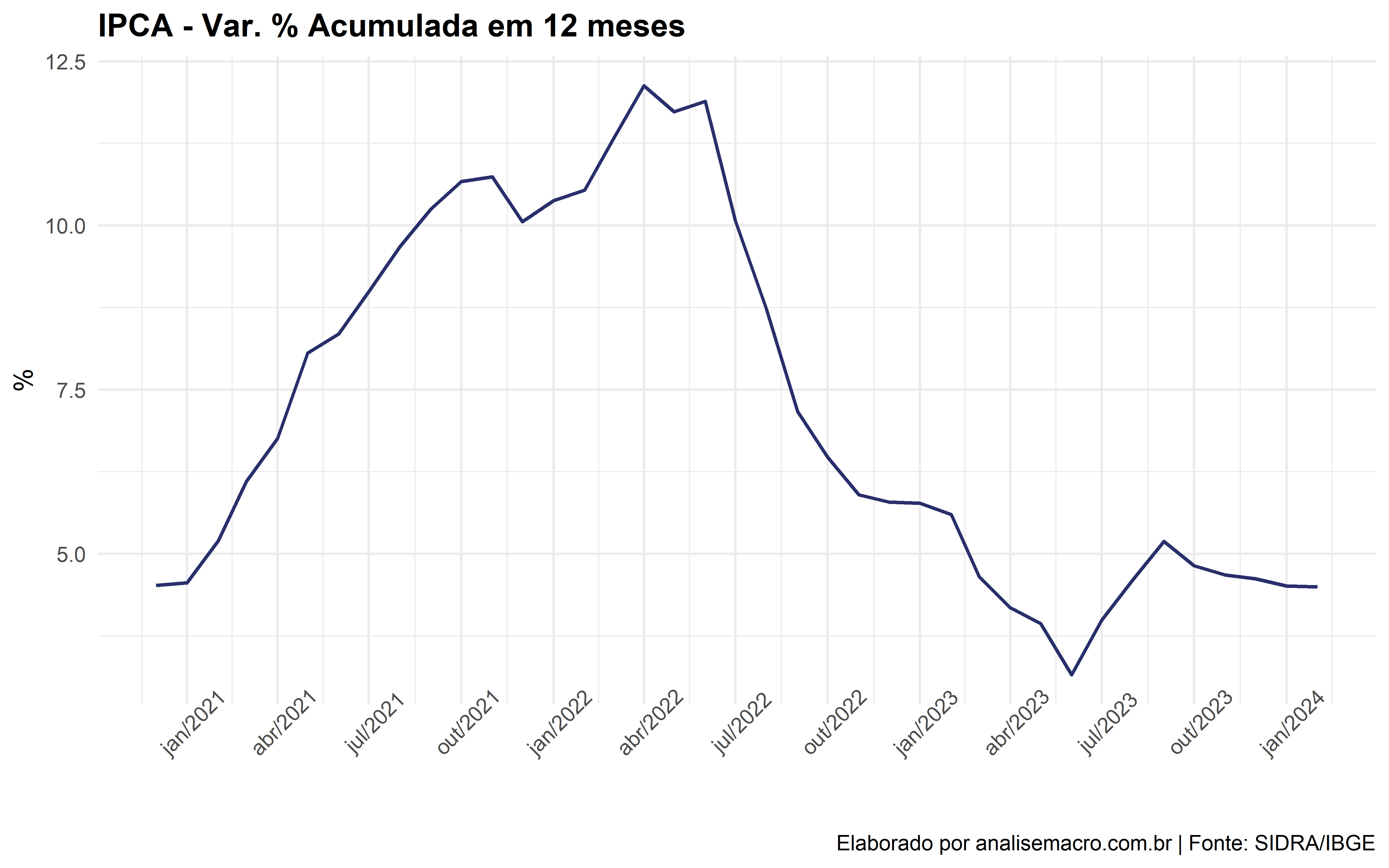
Considerações
Note que as fontes de dados aqui exploradas são públicas e, apesar de serem um ativo valiosíssimo para os amantes de dados, frequentemente podem apresentar instabilidades. Se você obteve um erro estranho ao tentar extrair dados destas fontes, verifique no site da instituição se está tudo ok e tente novamente em outro momento se for o caso.
Além disso, API’s de dados públicos geralmente possuem limitações de requisição/acessos - como é o caso Sidra/IBGE -, portanto, utilize com cautela e responsabilidade, evitando realizar requisições de dados desnecessárias.
Quer aprender mais?
Clique aqui para fazer seu cadastro no Boletim AM e baixar o código que produziu este exercício, além de receber novos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas diretamente em seu e-mail.

