Nosso objetivo nos nossos Cursos é o de fornecer uma introdução aplicada à macroeconomia. Serve tanto para alunos e professores de economia, em busca de ferramentas mais aplicadas para lidar com variáveis macroeconômicas, quanto para profissionais de outras áreas em busca de conhecimentos em macroeconomia.
Para ilustrar o que vemos no Curso, vou mostrar aqui nesse post como é possível deflacionar uma série econômica, dúvida muito comum entre nossos alunos. Sabemos todos que R$ 100 em dezembro de 1997 não é a mesma coisa que R$ 100 em dezembro de 2016, não é mesmo? Logo, para comparar valores no tempo é preciso que levemos em consideração a taxa de crescimento do nível geral de preços, ou simplesmente a inflação. Para comparar valores nominais em dois períodos distintos, é preciso que tenhamos a mesma base de preços. Para ilustrar, vamos dar um exemplo utilizando a despesa com benefícios previdenciários do governo central. Para deflacionar, vamos utilizar o Índice de Preços ao Consumidor Amplo (IPCA).
library(readxl)
library(tidyverse)
library(ggplot2)
library(magrittr)
library(lubridate)
library(sidrar)
data = read_excel("primario.xlsx")
data %>% pivot_longer(-date, names_to='Variável', values_to='valor') %>%
ggplot(aes(x=date, y=valor, color=Variável)) + geom_line() +
labs(title='Receitas e despesas com benefícios previdenciários', x='Data',
y='Valor', color='') +
theme_light()
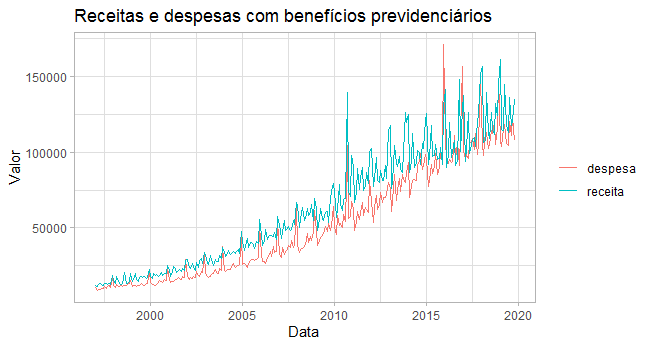
O gráfico acima ilustra as nossas séries em valores nominais. Na sequência, fazemos o ajuste para valores reais com base no IPCA.
ipca = get_sidra(api='/t/1737/n1/all/v/2266/p/all/d/v2266%2013')
ipca %<>% mutate(date = parse_date_time(`Mês (Código)`, 'ym'))
ajuste <- left_join(ipca, data, by='date') %>%
select(date, Valor, receita, despesa) %>%
na.omit() %>%
mutate('Receita ajustada' = receita/Valor*Valor[274],
'Despesa ajustada' = despesa/Valor*Valor[274])
ajuste %>% select(date, receita, 'Receita ajustada') %>%
pivot_longer(-date, names_to = 'Variáveis', values_to = 'Valor') %>%
ggplot(aes(x=date, y=Valor, color=Variáveis)) + geom_line() +
labs(title='Receitas com benefícios previdenciários nominais e reais', x='Data',
color='') +
theme_light()
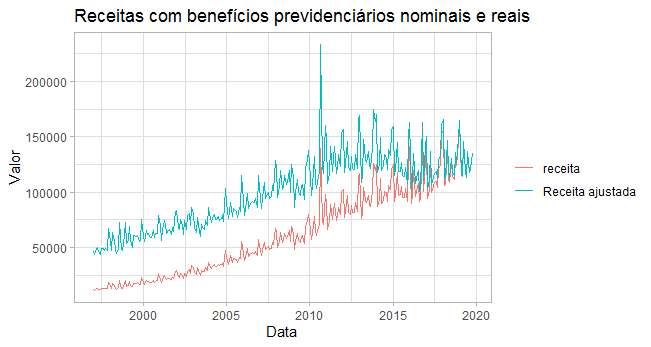 No gráfico acima, vemos os valores nominais e reais das receitas com benefícios previdenciários. A título de comparação, é necessário sempre usar valores reais.
No gráfico acima, vemos os valores nominais e reais das receitas com benefícios previdenciários. A título de comparação, é necessário sempre usar valores reais.
________________
Isso e muito mais você aprenda na nossa trilha de Macroeconomia Aplicada.

