O Boletim Focus é uma pesquisa realizada pelo Banco Central do Brasil, que divulga semanalmente as projeções de diversos indicadores macroeconômicos do país. A pesquisa é extremamente útil para entender a conjuntura econômica do país. Para coletar os dados do relatório, podemos utilizar a biblioteca python-bcb, que realiza a conexão com a API do Banco Central e permite realizar a importação dos dados direto para o Python.
Para utilizar o python-bcb é extremamente simples. Primeiro devemos carregar o módulo Expectativas e utilizar suas funções e métodos para realizar a importação.
Utilizamos a função Expectativas() para instanciar com as informações da pesquisa. Salvamos em objeto com o nome "em" para utilizar o método describe() de forma a obtermos as pesquisas disponíveis e conectar com a que desejamos. No caso, queremos obter informações das Expectativas Anuais.
!pip install python-bcb from bcb import Expectativas import pandas as pd from matplotlib import pyplot as plt import seaborn as sns
# Instancia a classe em = Expectativas() # Obtém os entitysets (nome das pesquisas) em.describe()
</pre>
# Obtém as informações da pesquisa
em.describe('ExpectativasMercadoAnuais')
Com as informações conhecidas sobre o data frame a ser importado, utilizamos o método get_endpoint() para conectar com a API do Banco Central e executar a consulta com .query()
ep = em.get_endpoint('ExpectativasMercadoAnuais')
# Dados do IPCA ipca_expec = ( ep.query() .filter(ep.Indicador == 'IPCA', ep.DataReferencia == 2023) .filter(ep.Data >= '2022-01-01') .filter(ep.baseCalculo == '0') .select(ep.Indicador, ep.Data, ep.Media, ep.Mediana, ep.DataReferencia) .collect() ) # Formata a coluna de Data para formato datetime ipca_expec['Data'] = pd.to_datetime(ipca_expec['Data'], format = '%Y-%m-%d')
Em conjunto com query(), utilizamos os métodos do pandas de forma a obter os dados já tratados, com os dados da expectativas do IPCA do ano referente a 2023, coletados em 2022.
Por fim, obtemos o data frame com a Media e a Mediana das projeções divulgadas pelo Boletim Focus nas semanas ao longo de 2022. Abaixo, criamos o gráfico para representar a evolução do indicador.
# Configura o tema do gráfico
## Cores
colors = ['#282f6b', '#b22200', '#eace3f', '#224f20', '#b35c1e', '#419391', '#839c56','#3b89bc']
## Tamanho
theme = {'figure.figsize' : (15, 10)}
## Aplica o tema
sns.set_theme(rc = theme,
palette = colors)
# cria o gráfico
sns.lineplot(x = 'Data',
y = 'Mediana',
data = ipca_expec).set(title = 'Expectativas de Mercado para o IPCA - 2023',
xlabel = '',
ylabel = '% a.a.')
# Adiciona a fonte no gráfico
plt.annotate('Fonte: analisemacro.com.br com dados do BCB/SGS',
xy = (1.0, -0.07),
xycoords='axes fraction',
ha='right',
va="center",
fontsize=10)
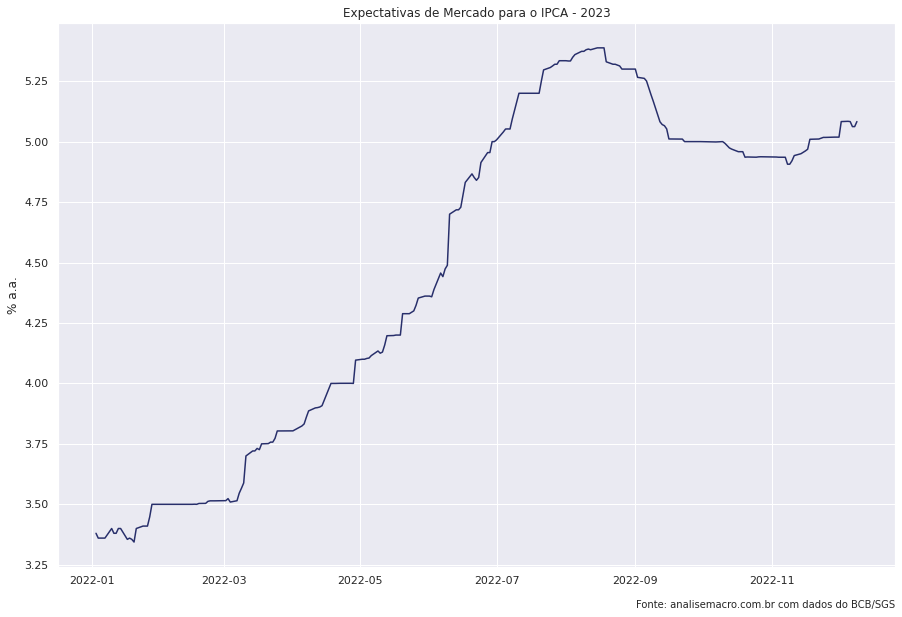
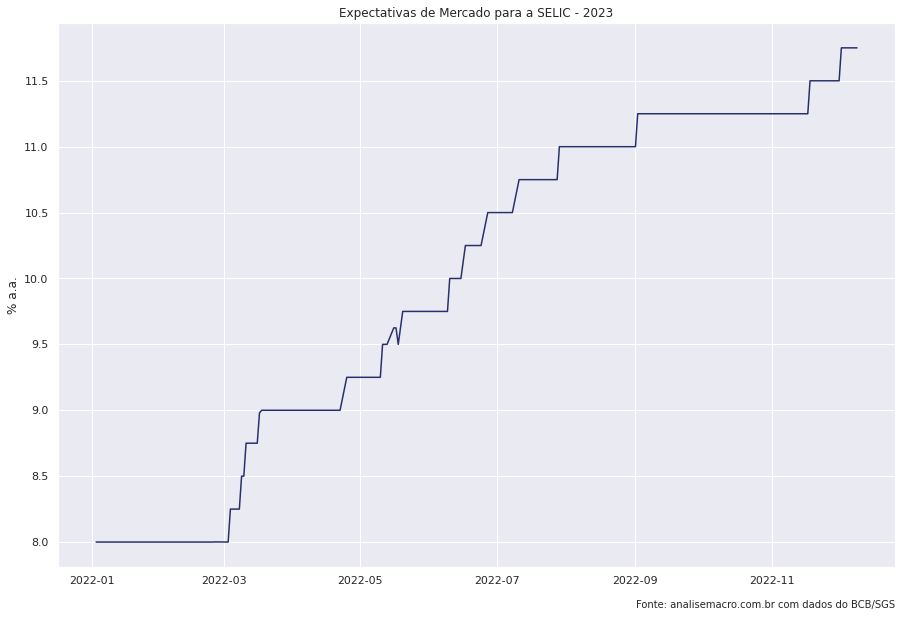
Abaixo, realizamos o mesmo procedimento com a SELIC, o PIB e o Câmbio.
selic_expec = ( ep.query()
.filter(ep.Indicador == 'Selic', ep.DataReferencia == 2023)
.filter(ep.Data >= '2022-01-01')
.filter(ep.baseCalculo == '0')
.select(ep.Indicador, ep.Data, ep.Media, ep.Mediana, ep.DataReferencia)
.collect()
)
selic_expec['Data'] = pd.to_datetime(selic_expec['Data'], format = '%Y-%m-%d')
# cria o gráfico
sns.lineplot(x = 'Data',
y = 'Mediana',
data = selic_expec).set(title = 'Expectativas de Mercado para a SELIC - 2023',
xlabel = '',
ylabel = '% a.a.')
# Adiciona a fonte no gráfico
plt.annotate('Fonte: analisemacro.com.br com dados do BCB/SGS',
xy = (1.0, -0.07),
xycoords='axes fraction',
ha='right',
va="center",
fontsize=10)
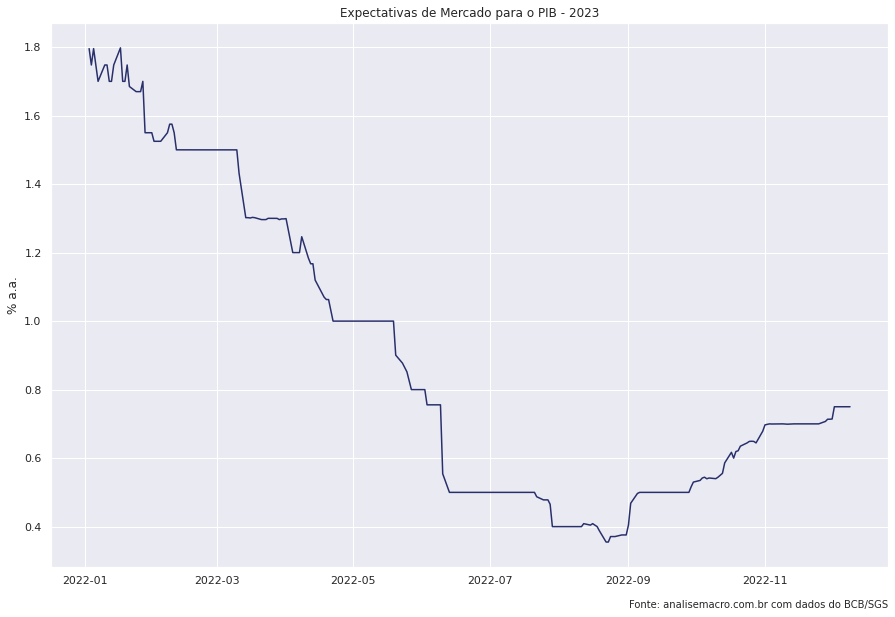
pib_expec = ( ep.query()
.filter(ep.Indicador == 'PIB Total', ep.DataReferencia == 2023)
.filter(ep.Data >= '2022-01-01')
.filter(ep.baseCalculo == '0')
.select(ep.Indicador, ep.Data, ep.Media, ep.Mediana, ep.DataReferencia)
.collect()
)
pib_expec['Data'] = pd.to_datetime(pib_expec['Data'], format = '%Y-%m-%d')
# cria o gráfico
sns.lineplot(x = 'Data', y = 'Mediana', data = pib_expec).set(title = 'Expectativas de Mercado para o PIB - 2023',
xlabel = '',
ylabel = '% a.a.')
# Adiciona a fonte no gráfico
plt.annotate('Fonte: analisemacro.com.br com dados do BCB/SGS',
xy = (1.0, -0.07),
xycoords='axes fraction',
ha='right',
va="center",
fontsize=10)
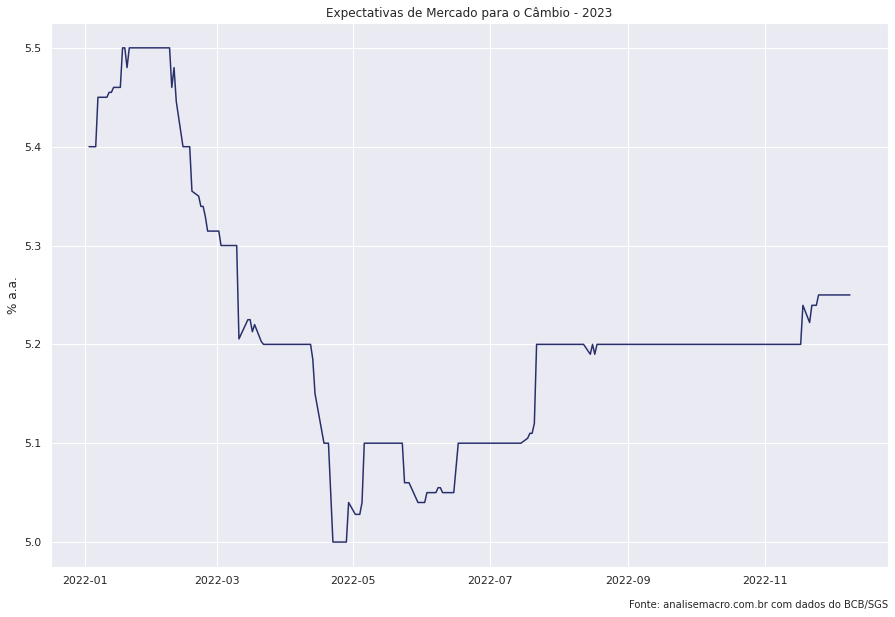
cambio_expec = ( ep.query()
.filter(ep.Indicador == 'Câmbio', ep.DataReferencia == 2023)
.filter(ep.Data >= '2022-01-01')
.filter(ep.baseCalculo == '0')
.select(ep.Indicador, ep.Data, ep.Media, ep.Mediana, ep.DataReferencia)
.collect()
)
cambio_expec['Data'] = pd.to_datetime(cambio_expec['Data'], format = '%Y-%m-%d')
# cria o gráfico
sns.lineplot(x = 'Data',
y = 'Mediana',
data = cambio_expec).set(title = 'Expectativas de Mercado para o Câmbio - 2023',
xlabel = '',
ylabel = '% a.a.')
# Adiciona a fonte no gráfico
plt.annotate('Fonte: analisemacro.com.br com dados do BCB/SGS',
xy = (1.0, -0.07),
xycoords='axes fraction',
ha='right',
va="center",
fontsize=10)
_____________________________________
Quer aprender mais?
Seja um aluno da nossa trilha de Macroeconomia Aplicada e aprenda a criar projetos voltados para a Macroeconomia

