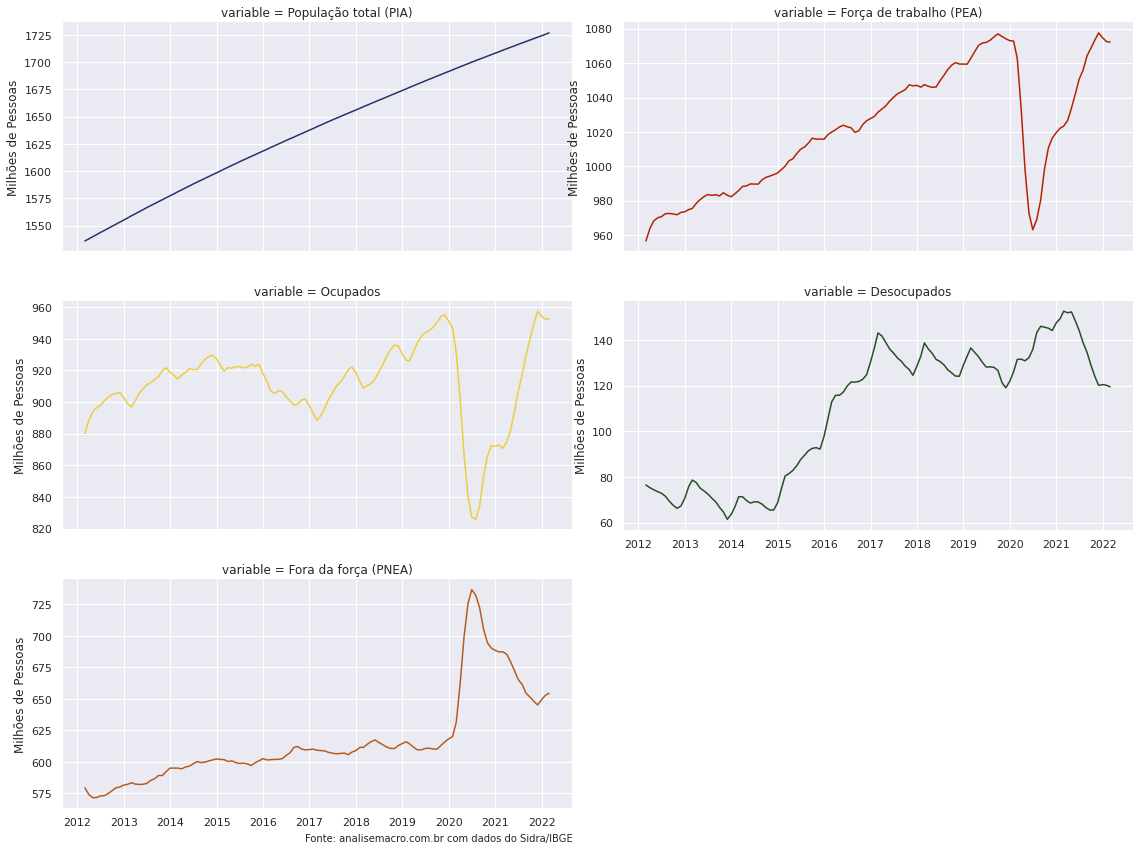
Para realizar uma análise de conjuntura completa, é crucial dominar a habilidade de coletar dados sobre o Mercado de Trabalho. Esse processo pode ser facilitado utilizando o Python, sendo possível importar os dados direto do SIDRA. No post de hoje, mostraremos como é possível realizar essa coleta de forma reprodutível e automática.
Antes de tudo, é necessário escolher as tabelas do SIDRA dos indicadores que se deseja analisar. Aqui buscaremos a tabela 6318, que diz respeito a " Pessoas de 14+ anos (Mil pessoas): ocupados/desocupados na Força de trabalho". Existem diversas outras tabelas interessantes que entregam informações preciosíssimas sobre o Mercado de Trabalho, e que podem ser coletadas utilizando o mesmo método aqui praticado.
Para coletar os dados do SIDRA utilizaremos a biblioteca {sidrapy}, que através dos códigos dos parâmetros oferecidos pela API da plataforma, permite importar os dados para o Python.
Pessoas de 14+ anos (Mil pessoas): ocupados/desocupados na Força de trabalho: "/t/6318/n1/all/v/1641/p/all/c629/all"
Realizamos essa busca na seguinte URL: https://sidra.ibge.gov.br/tabela/6318, escolhendo os parâmetros de interesse na plataforma e buscando a API em "Links para Compartilhar" no final da página.
Com isso, construímos o código no Python.
Quer saber mais?
Veja nossos cursos de Macroeconomia através da nossa trilha de Macroeconomia Aplicada.

