O SIDRA (Sistema IBGE de Recuperação Automática) é uma plataforma do IBGE criada com o objetivo de consultar as pesquisas criados e disponibilizadas pelo Instituto. A interface permite que sejam acessado através de API's informações e dados sobre indicadores importantes. O objetivo do post de hoje será mostrar como é possível acessar estes dados utilizando o Python, utilizando a série do PIB como exemplo.
A API do SIDRA permite a extração dos dados disponibilizados. Por sorte, existe o {sidrapy} que permite acessar facilmente estes dados e realizar a importação direta para a linguagem.
Apesar de mais ser mais facilitado do que retirar diretamente da API do SIDRA, é necessário alguns conhecimentos de uso da biblioteca e o posterior tratamento de dados. Nosso objetivo neste post será de elencar os procedimento necessário, bem como ensinar como realizar a limpeza.
sidrapy
A biblioteca oferece uma única função, get_table(), que permite através de seus argumentos especificar a série e seus parâmetros para a importação.
Os diferente tipos de parâmetros definem a tabela e suas dimensões (períodos, variáveis, unidades territoriais e classificações/categorias). Iremos elencar a baixo cada parâmetro, como obter e onde se insere na função (para mais observações ver a página de ajuda da API do SIDRA).
- t (table_code) - é o código da tabela referente ao indicador e a pesquisa;
- p (period) - utilizado para especificar o período;
- v (variable) - para especificar as variáveis desejadas;
- n (territorial_level) - especifica os níveis territoriais;
- n/ (ibge_territorial_code) - inserido dentro do nível territorial, especificar o código territorial do IBGE;
- c/ (classification/categories) - especifica as classificações da tabela e suas respectivas categorias.
Para obter a tabela e os códigos, o primeiro passo será entrar na interface do SIDRA e buscar a pesquisa/indicador de interesse através do site e em seu buscador https://sidra.ibge.gov.br/home/
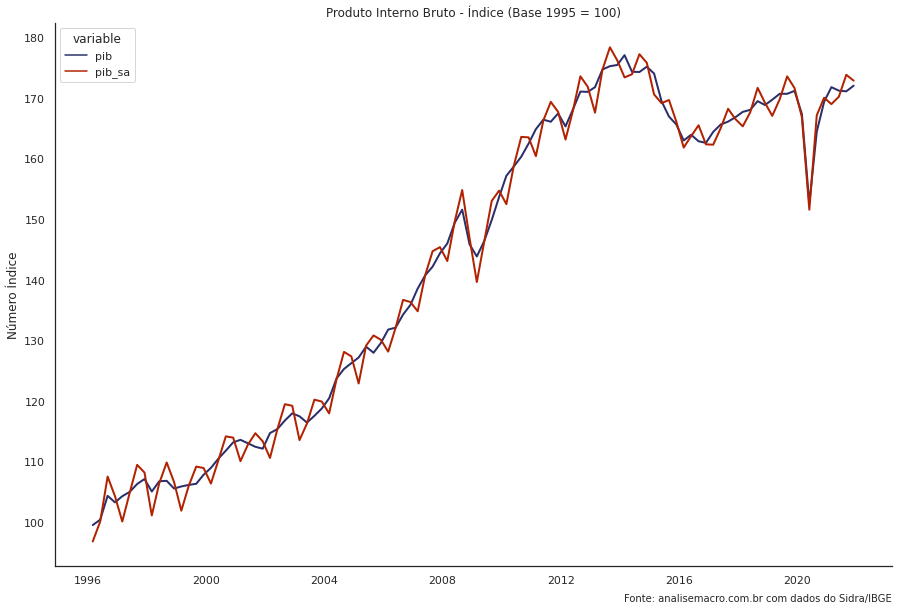
Escolhemos como exemplo a série do PIB sem ajuste sazonal e com ajuste sazonal, referente a tabela 1620 e 1621, respectivamente, que se trata da série das Contas Nacionais Trimestrais.
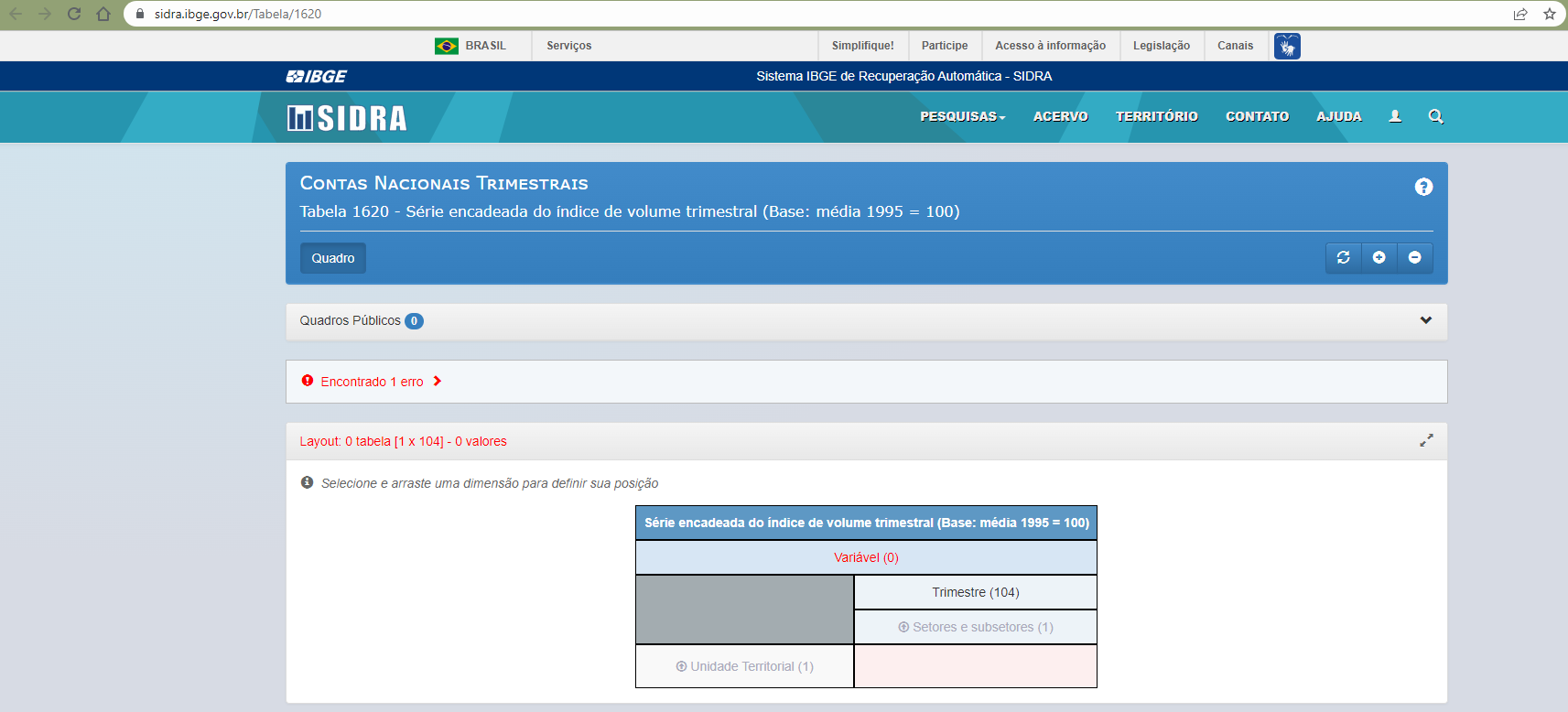
Através da interface, selecionamos a variável "Série encadeada do índice de volume trimestral (Base: média 1995 = 100) (Número índice)"; Setores e subsetores (categorias) "PIB a preços de mercado"; Trimestre (período) - todo o período; Unidade Territorial "Brasil".
Com efeito, será gerado os parâmetros para API no quadro de links (localizado ao fim da página). No caso da tabela 1620, foi produzido a seguinte API: https://apisidra.ibge.gov.br/values/t/1620/n1/all/v/all/p/all/c11255/90707/d/v583%202
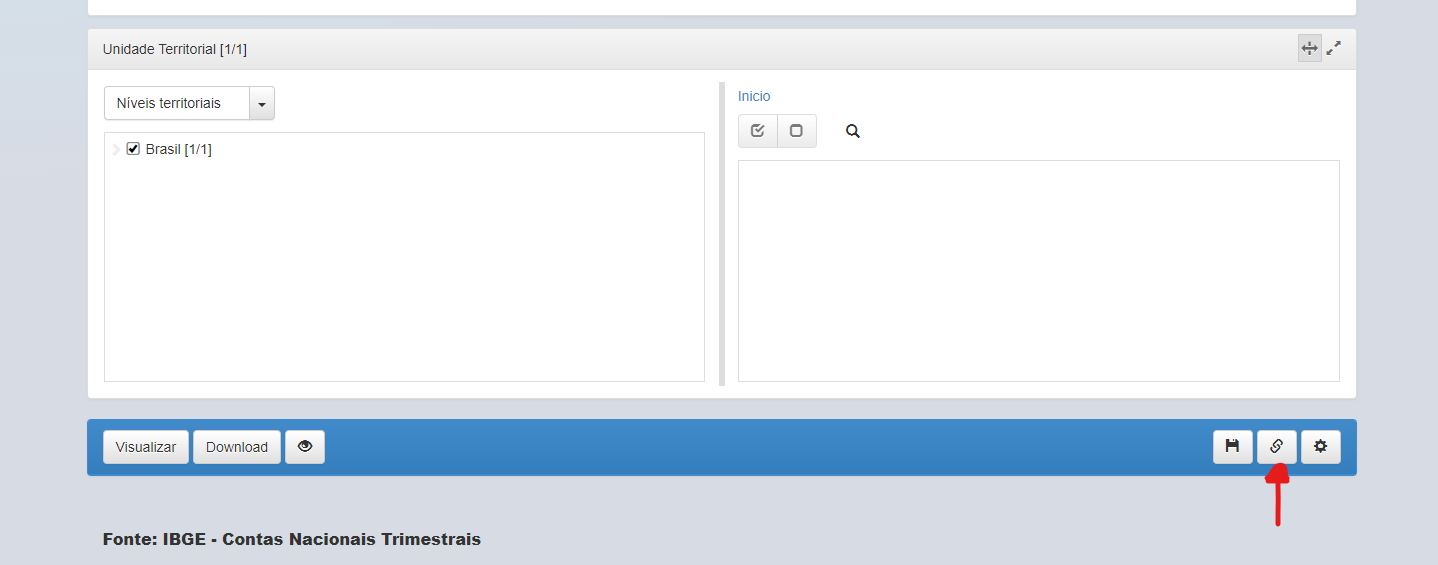
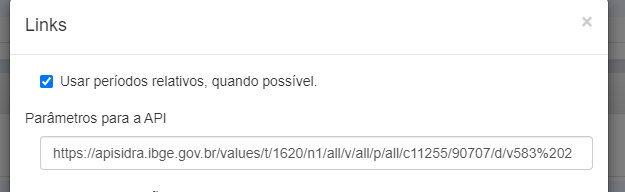
O que nos interessa, entretanto, serão os códigos posteriores a /t/, sendo representados pelos parâmetros necessários para utilizar a função get_table() do {sidrapy} de acordo com os caracteres do parâmetros listados acima.
/t/1620/n1/all/v/all/p/all/c11255/90707/d/v583%202
Sendo assim, temos que:
- t (table_code) = 1620
- n (territorial_level) = 1
- n/ (ibge_territorial_code) = all
- v (variable) = all
- p (period) = all
- c/ (categories) = 11255/90707
PIB sem ajuste sazonal
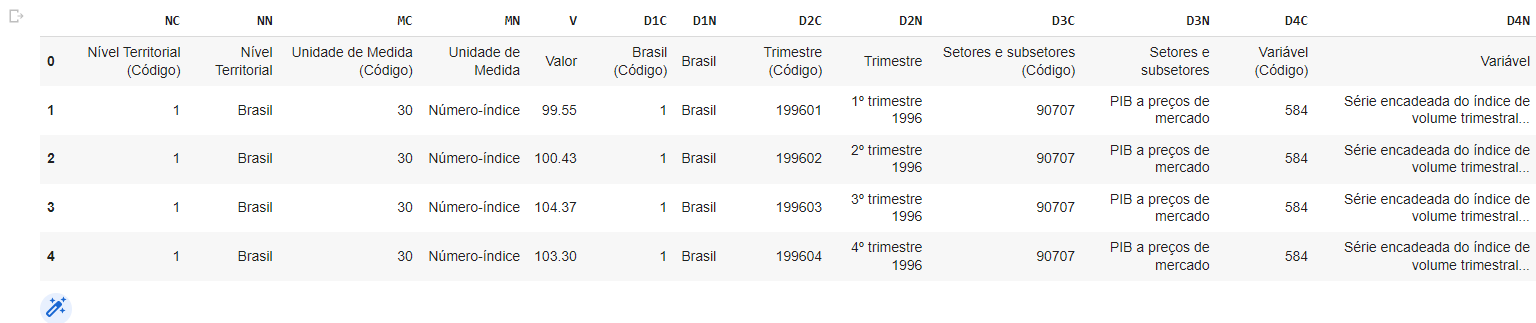
Após a importação, vemos que o dados não estão da forma que gostaríamos, sendo necessário, portanto, a realização de uma limpeza.
O primeiro passo será alterar o nomes da colunas com os nomes da primeira observação, e retirar estes dados do data frame. Também é necessário alterar o tipo de dados da coluna "Valor" para float.
Devemos então alterar os nomes das colunas de interesse e remover o restante das colunas. Deixemos as variáveis que representam o valor da série e o código do trimestre.
Através de uma inspeção no data frame, vemos que a coluna de trimestre está em formato de ano e trimestre numérico (199601, 199602...), devemos realizar um procedimento para que o Python reconheça esta coluna como data.
Para lidar com isto, removemos da coluna o valor numérico referente ao trimestre e alteramos para um valor que se aproxime de um mês relacionado em período de trimestres. Juntamos novamente com o ano em uma nova coluna.
Por fim, utilizamos a função to_datetime() para transformar em formato de data e inserir dentro do índice.
PIB com ajuste sazonal
Criar o gráfico
Quer saber mais?
Veja nossos cursos de Python aplicados:

