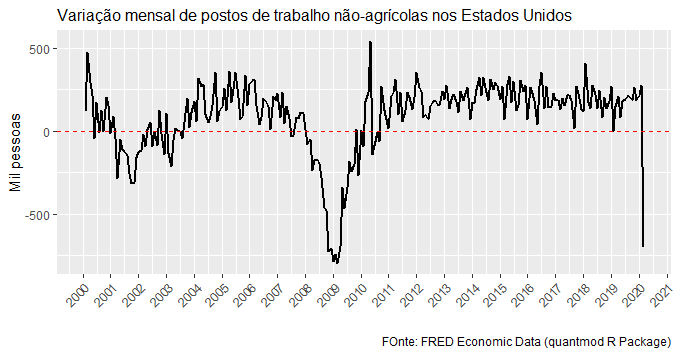
Hoje o U.S. Bureau of Labor Statistics divulgou o dado do nonfarm payroll, ou seja, a quantidade de postos de trabalho não agrícolas criadas/destruídas ao longo do mês. O resultado para março foi de uma queda de 701 mil postos de trabalho. Uma destruição de postos de trabalho muito mais rápida do que a que houve em 2008.
Para visualizar os dados do payroll, podemos usar o pacote quantmod como no código abaixo.
library(quantmod)
library(ggplot2)
library(gridExtra)
library(dplyr)
library(magrittr)
library(scales)
getSymbols('PAYEMS', src='FRED')
data = tibble(date=as.Date(time(PAYEMS)),
payroll=PAYEMS) %>%
mutate(variacao = payroll - lag(payroll,1))
filter(data, date > '2000-01-01') %>%
ggplot(aes(x=date, y=variacao))+
geom_line(size=.8)+
geom_hline(yintercept=0, colour='red', linetype='dashed')+
scale_x_date(breaks = date_breaks("1 year"),
labels = date_format("%Y"))+
theme(axis.text.x=element_text(angle=45, hjust=1),
plot.title = element_text(size=12))+
labs(x='', y='Mil pessoas',
title='Variação mensal de postos de trabalho não-agrícolas nos Estados Unidos',
caption='FOnte: FRED Economic Data (quantmod R Package)')
(*) Isso e muito mais você aprende em nossos Cursos Aplicados de R.
___________

