Na semana passada, a taxa de desemprego foi divulgada em 14.7% no 1º trimestre, o que equivale a cerca de 14.8 milhões de desempregados. Esses dados podem ser resumidos na tabela abaixo: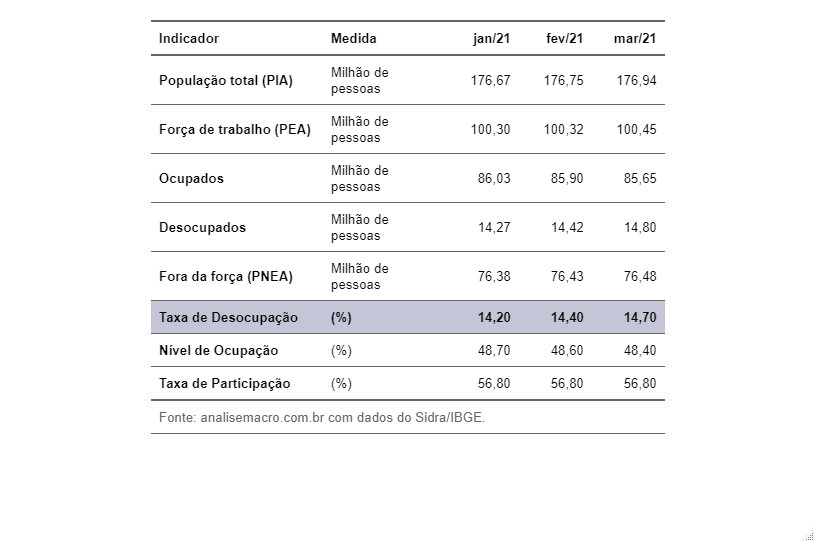
É importante notar que houve uma mudança na nomenclatura da PNAD: PIA é agora população total, PEA é força de trabalho, e a PNEA é fora da força. Vemos que houve um aumento da força de trabalho, simultaneamente com aumento da população desocupada. O nível de desemprego claramente é anormal, como resultado da crise de 2020, porém a variação vista nos últimos 2 meses tem, além do fator restrições sobre o comércio devido à nova onda de casos, um fator cíclico anual:
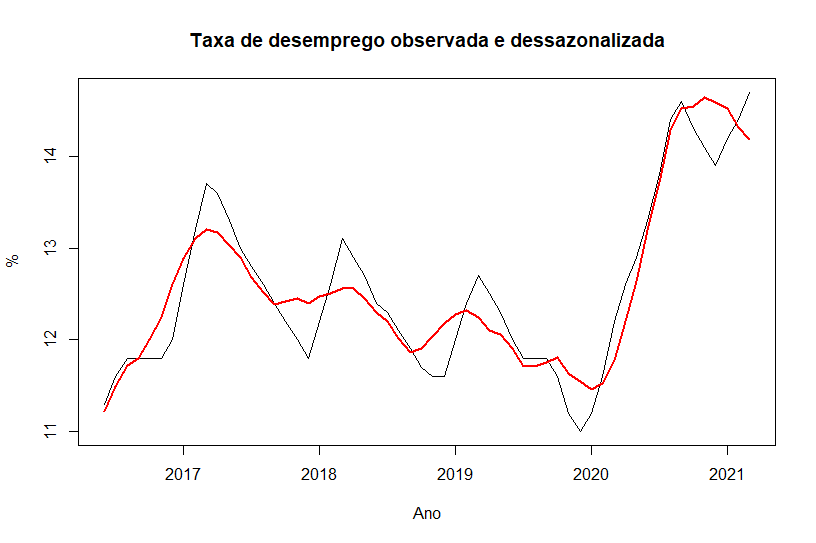
A taxa de desemprego após um choque como o visto atualmente traz grande preocupação para o futuro, devido ao fenômeno da histerese. Com o maior número de desempregados, a chance de uma pessoa passar mais tempo sem emprego é maior, o que pode causar uma diminuição de seu capital humano, tornando ainda mais difícil sua reinserção no mercado de trabalho, gerando um ciclo vicioso. Abaixo, podemos ver que a população que está há mais de 2 anos sem emprego aumentou ao longo de 2020, evidenciando esse problema:
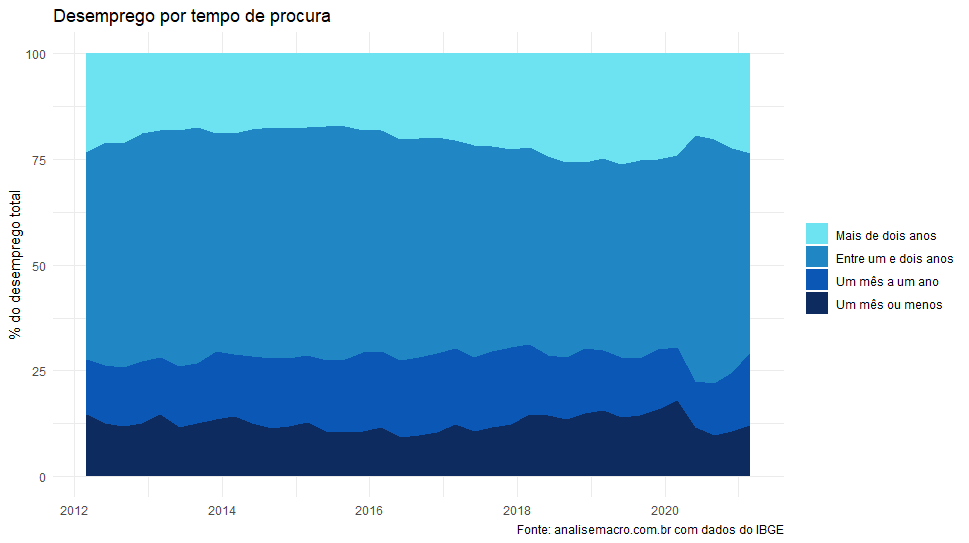 Outro ponto que tem sido muito discutido atualmente é a relevância dos dados do CAGED, devido a dúvidas sobre sua validade como medida do mercado de trabalho após a mudança em sua metodologia. Abaixo, os resultados do saldo nos últimos meses:
Outro ponto que tem sido muito discutido atualmente é a relevância dos dados do CAGED, devido a dúvidas sobre sua validade como medida do mercado de trabalho após a mudança em sua metodologia. Abaixo, os resultados do saldo nos últimos meses:
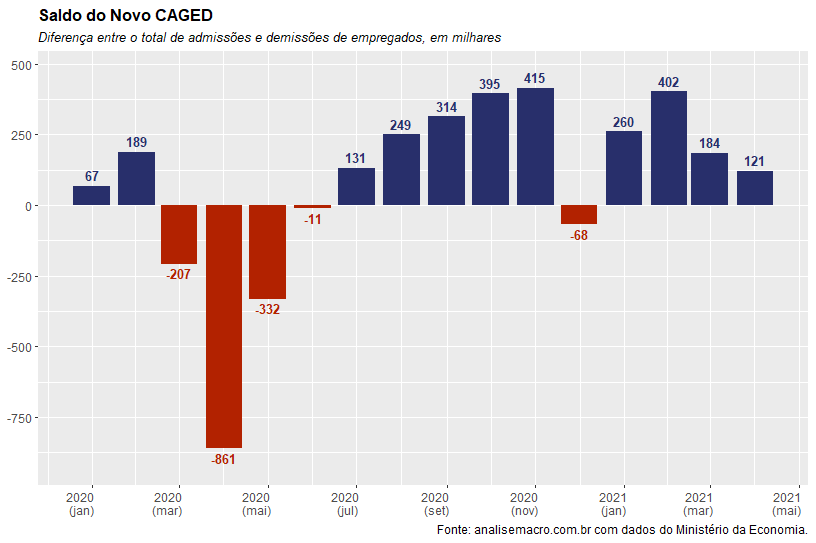
Como podemos ver, apesar de diminuir em magnitude, o saldo de admissões está positivo nos últimos meses, o que parece discordar com a taxa de desemprego crescente. Esse dado se torna ainda mais duvidoso ao compararmos com as estatísticas da PNAD contínua:
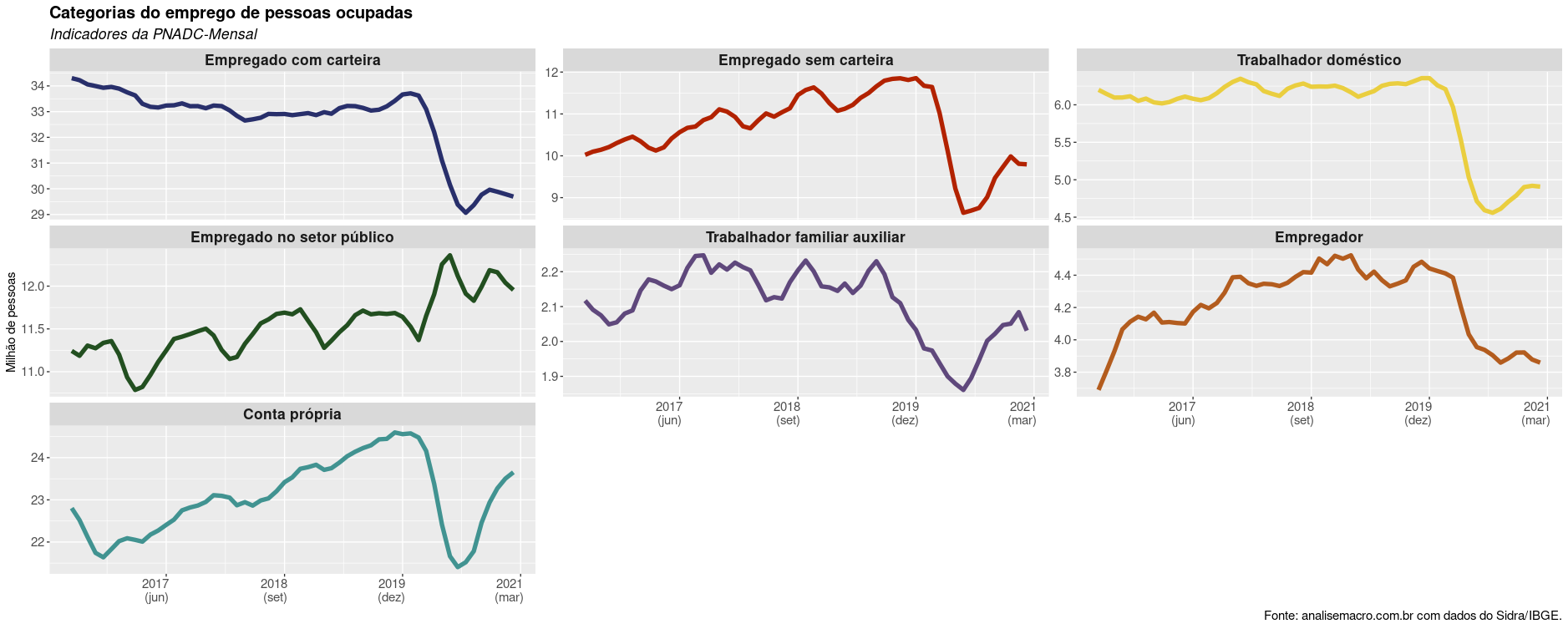
Como podemos ver, o nível de empregados com carteira diminuiu nos dados mais recentes, sendo o nível geral compensado por trabalhadores sem carteira e autônomos. Para justificar um saldo positivo como apresentado acima, teríamos que supor uma grande redução no número de demissões, o que não condiz com o movimento sazonal de começo de ano. Com isso, os dados do CAGED parecem ter se tornado demasiadamente problemáticos para serem confiáveis.
O gráfico apresentado acima faz parte do nosso monitor de mercado de trabalho. Ele é um aplicativo interativo, que realiza diversas visualizações e facilita a compreensão de tudo que está acontecendo na macroeconomia em tempo real. Também estamos publicando outros 3 monitores: de inflação, atividade e do mercado de crédito.


