Introdução
Metodologia da Previsão
Dados
Utilizou-se o banco de dados macroeconômicos FRED-MD, que abrange uma série de 127 indicadores econômicos dos EUA, com dados disponíveis desde 1959 até 2019 (ano da amostra utilizada, embora existam dados mais recentes disponíveis).
A seguir, apresentamos uma tabela com as variáveis utilizadas:
| Variável | Transformação | Nome no banco de dados FRED-MD | Código | Fórmula |
|---|---|---|---|---|
| Desemprego | Diferenças | UNRATE | 2 | ∆xₜ |
| Título do tesouro de 3 meses | Diferenças | TB3MS | 2 | ∆xₜ |
| Inclinação da curva de juros | Diferenças | – | 2 | ∆xₜ |
| Renda pessoal real | Diferenças logarítmicas | RPI | 5 | ∆log(xₜ) |
| Produção industrial | Diferenças logarítmicas | INDPRO | 5 | ∆log(xₜ) |
| Consumo | Diferenças logarítmicas | DPCERA3M086SBEA | 5 | ∆log(xₜ) |
| S&P 500 | Diferenças logarítmicas | S&P 500 | 5 | ∆log(xₜ) |
| Empréstimos empresariais | Diferenças logarítmicas de segunda ordem | BUSLOANS | 6 | ∆²log(xₜ) |
| IPC | Diferenças logarítmicas de segunda ordem | CPIAUCSL | 6 | ∆²log(xₜ) |
| Preço do petróleo | Diferenças logarítmicas de segunda ordem | OILPRICEx | 6 | ∆²log(xₜ) |
| Dinheiro M2 | Diferenças logarítmicas de segunda ordem | M2SL | 6 | ∆²log(xₜ) |
Cada variável no banco de dados FRED-MD possui um nome e um código específico que indica a transformação necessária para tornar a série estacionária. No exercício, extraímos as séries e aplicamos as transformações necessárias.
Um aspecto importante é a escolha da defasagem para cada método de transformação. É possível selecionar diferentes defasagens para cada variável. No nosso caso, utilizamos uma defasagem de 12 meses para o desemprego, pois queremos prever a mudança de um ano para o outro. Para as demais variáveis, optamos por uma defasagem de 3 meses.
Modelos Utilizados para a Previsão
Os seguintes modelos foram empregados para prever as mudanças no desemprego com um ano de antecedência:
- Regressão Linear
- Regressão Ridge
- Regressão Lasso
- Random Forest
- Support Vector Regression
Se você tem interesse em aprender a criar previsões de séries econômicas eficientes com o Python, veja nossos cursos de Modelagem e Previsão com Python e Previsão Macroeconômica usando Python e IA.
Visualização de dados
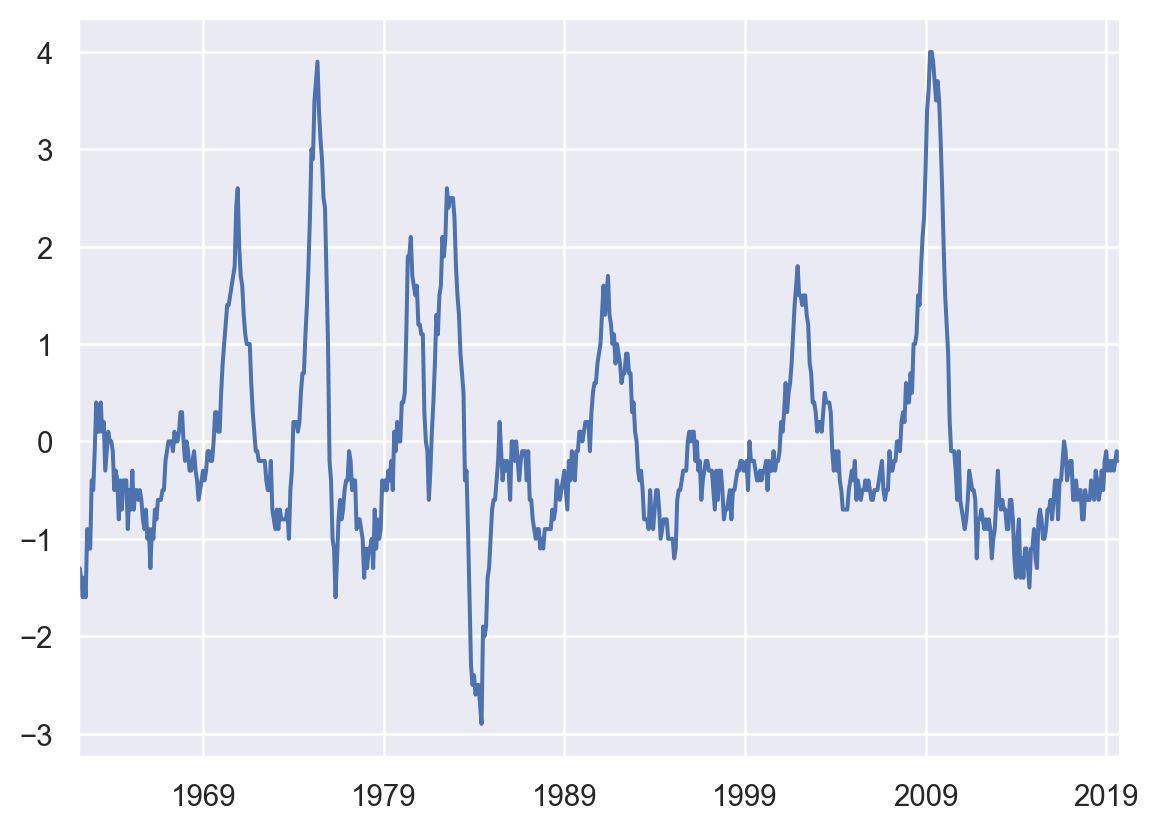
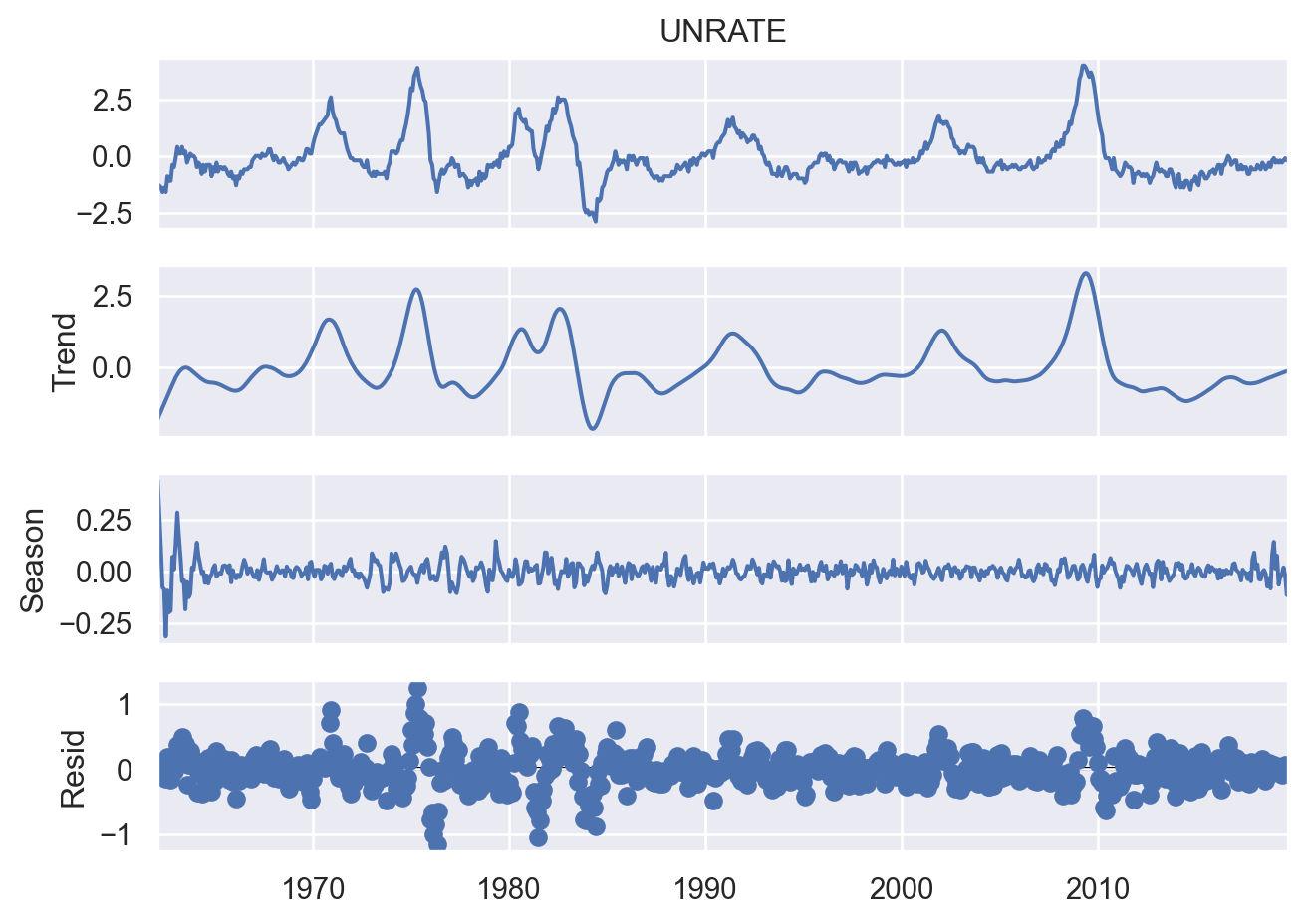
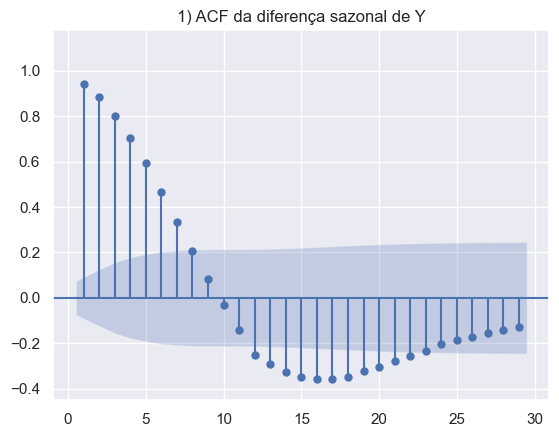
Os gráficos abaixo foram construídos para avaliar a série econômica do desemprego do EUA. Em ordem, temos a série em nível, sem transformações, a decomposição da série, com o objetivo de analisar os componentes sazonais e de tendência. E por fim, os gráficos ACF e PACF da série em diferenças e duas diferenças sazonais.
A partir do entendimento das características da série é possível aperfeiçoar o modelo, adicionando features adicionais para melhorar o poder da previsão.
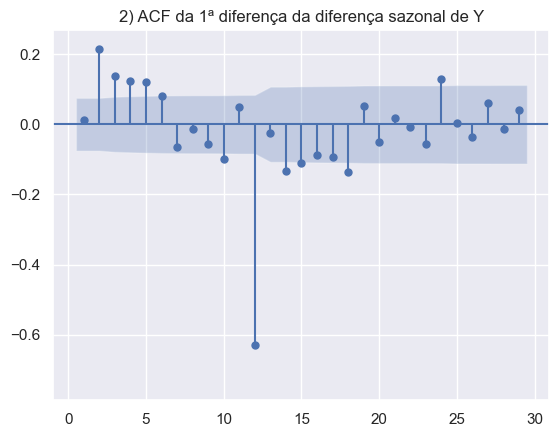
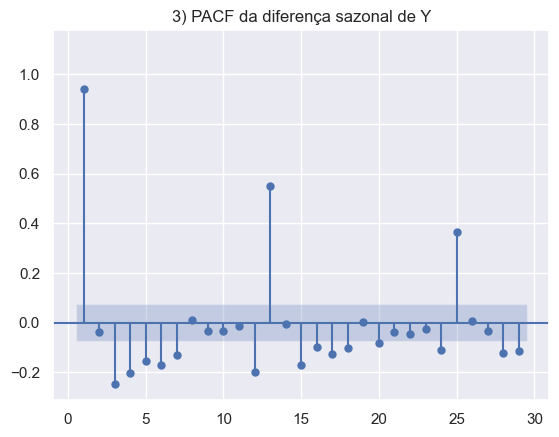
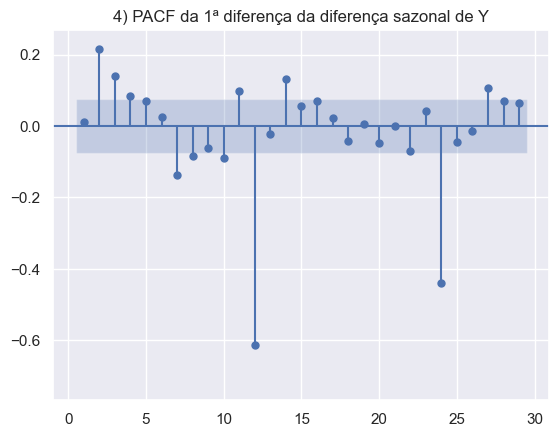
Resultados da Previsão
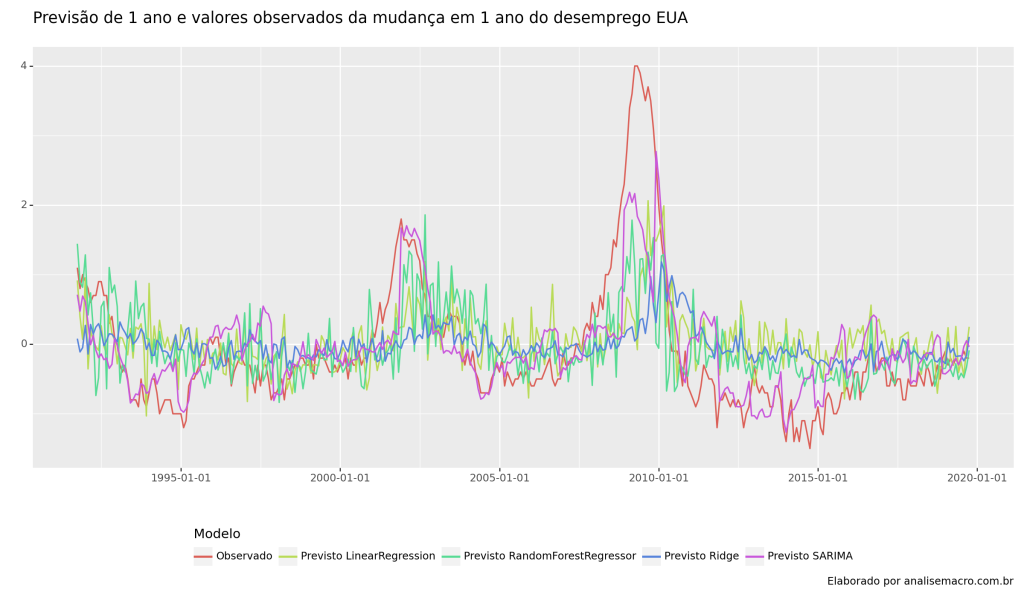
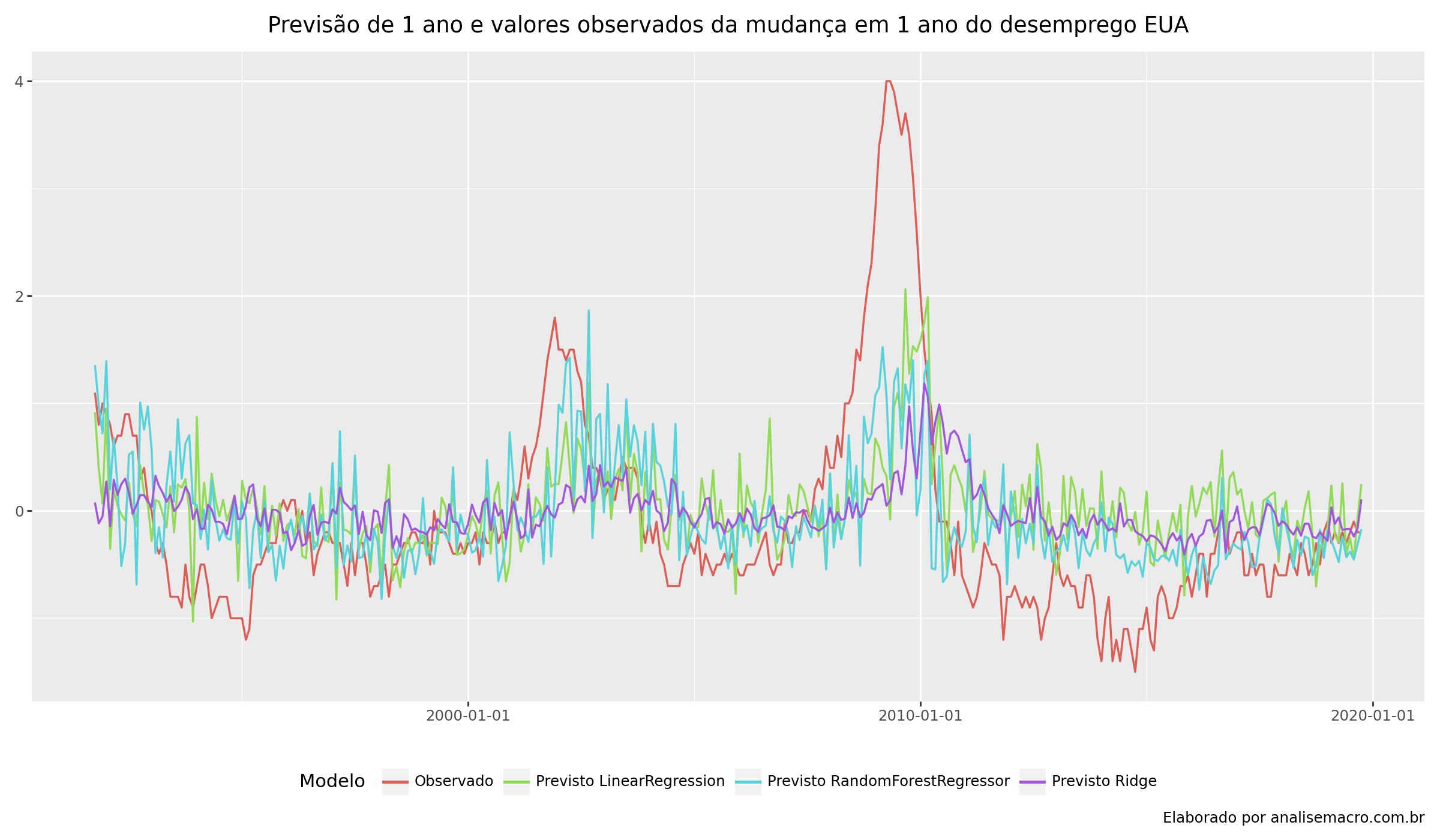
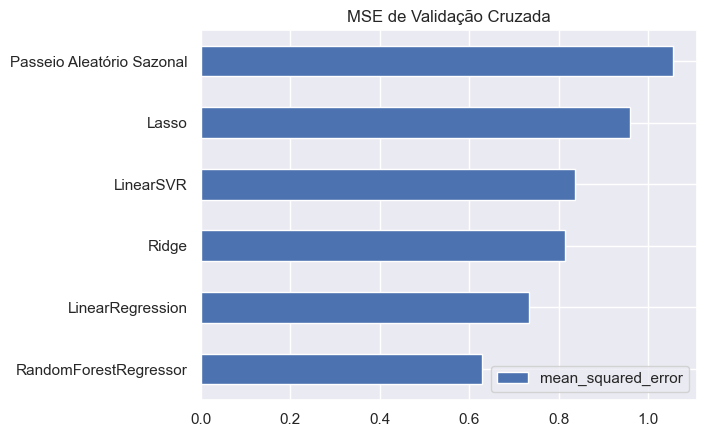
Abaixo, temos os resultados da previsão de 1 ano e valores observados da mudança em 1 ano do desemprego do EUA, isto é, realiza-se a previsão 1 ano a frente e compara-se com os valores efetivamente observamos. Para confirmar a qualidade dessas previsão realizamos o cálculo da métricas MSE (mean squared-error) da validação cruzada de cada modelo escolhido. Desta forma, podemos ter maiores garantias de qual o melhor modelo a ser escolhido. Na ocasião, temos que RandomForestRegressor foi o que possuiu o melhor desempenho.
Quer aprender mais?
Conheça nossa Formação do Zero à Análise de Dados Econômicos e Financeiros usando Python e Inteligência Artificial. Aprenda do ZERO a coletar, tratar, construir modelos e apresentar dados econômicos e financeiros com o uso de Python e IA.
Referências
Buckmann, M., Joseph, A. e Robertson, H. (2021). Opening the black box: Machine learning interpretability and inference tools with an application to economic forecasting. Data Science for Economics and Finance: Methodologies and Applications(pp. 43-63). Springer International Publishing.
fg-research. An overview of the FRED-MD database. Acesso em: https://fg-research.com/blog/general/posts/fred-md-overview.html#code
McCracken, M. W., & Ng, S. (2016). FRED-MD: A monthly database for macroeconomic research. Journal of Business & Economic Statistics, 34(4), 574-589. doi: 10.1080/07350015.2015.1086655.

