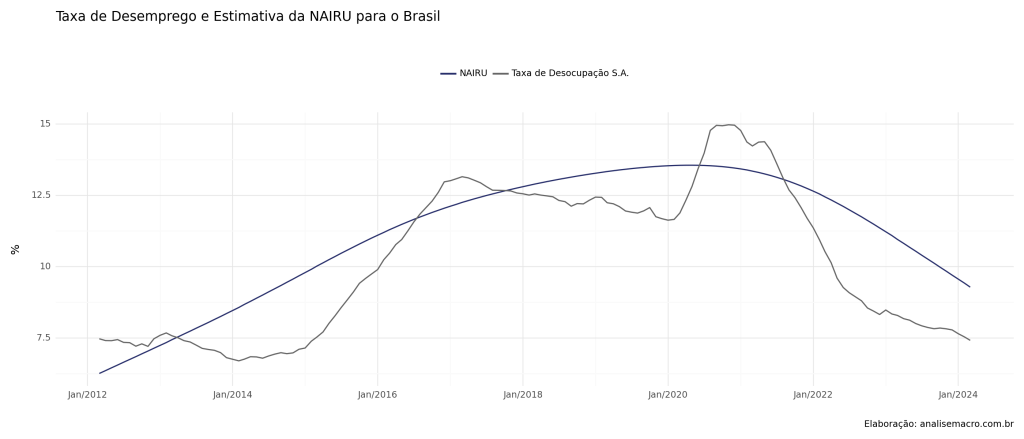
Um dos maiores desafios para aqueles que trabalham com dados econômicos é aliar a prática com a teoria. Para tanto, o uso do Python pode facilitar esse desafio, permitindo construir todos os passos de uma análise de dados. Demonstramos o poder da linguagem tomando como exemplo a construção da NAIRU para o Brasil.
NAIRU
NAIRU, sigla em inglês para “Non-Accelerating Inflation Rate of Unemployment” (Taxa de Desemprego Não Aceleradora da Inflação), refere-se ao nível de desemprego em uma economia que não provoca aceleração da inflação. Em outras palavras, é a taxa de desemprego em que a inflação permanece estável, não aumentando nem diminuindo.
Essa relação entre desemprego e inflação é capturada pela curva de Phillips. A curva de Phillips originalmente ilustra uma relação inversa entre a taxa de desemprego e a taxa de inflação: quando o desemprego é baixo, a inflação tende a ser alta, e vice-versa.
Os alunos do curso de Macroeconometria usando o Python, têm a oportunidade de adquirir um conhecimento abrangente em todas as fases do processo, desde a coleta e a preparação dos dados até a análise, o desenvolvimento de modelos econométricos e a comunicação dos resultados, tudo isso utilizando Python como ferramenta principal.
Modelo
Para estimar a NAIRU, tomaremos como base o método proposto por Ball e Mankiw (1997), em que baseia-se nos seguintes passo:
- Estimar uma Curva de Phillips
- A partir dos parâmetros estimados, obter a NAIRU somado aos movimentos de curto prazo/choque
- Obter o componente cíclico (NAIRU) da soma em 2 através do uso do Filtro HP.
Estimamos a Curva de Phillips conforme:
![\[\Pi = \Pi^e + a(U- U^*) + v\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-ab9d13991972d7d352f7c887c61cc870_l3.png "Rendered by QuickLaTeX.com")
aqui,  é a inflação corrente,
é a inflação corrente,  é a inflação esperada (com expectativas adaptativas ou racionais),
é a inflação esperada (com expectativas adaptativas ou racionais),  é a taxa de desemprego,
é a taxa de desemprego,  é a taxa de desemprego natural, e
é a taxa de desemprego natural, e  representa um choque de oferta.
representa um choque de oferta.
Rearranjando:
![\[\Delta \Pi = aU^* - aU + v\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-b0426ec4bf4226762bbac562325bced6_l3.png "Rendered by QuickLaTeX.com")
Podemos estimar os parâmetros facilmente por Mínimos Quadrados Ordinários desde que assumimos que seja contemporaneamente não correlacionado com .
Para obter  , rearranjamos a equação:
, rearranjamos a equação:
![\[U^* + v/a = U + \Delta \Pi / a\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-dce0a17c363855de41442f33b3477b04_l3.png "Rendered by QuickLaTeX.com")
O lado direito pode ser obtido somente com os dados, e com a estimação de  através da curva de phillips. O resultado será a estimativa da NAIRU () somado com os choques de curto prazo (
através da curva de phillips. O resultado será a estimativa da NAIRU () somado com os choques de curto prazo ( ). Assim, para obter o componente cíclico (NAIRU) aplicamos o Filtro HP.
). Assim, para obter o componente cíclico (NAIRU) aplicamos o Filtro HP.
Criando uma NAIRU para o Brasil
Para criar uma NAIRU para o Brasil definimos os seguintes passos:
1) Coleta dos dados da Taxa de Desocupação da PNADc, realizando um ajuste sazonal com o método X-13ARIMA-SEATS
2) Coleta e tratamentos dos dados da Expectativas do IPCA em 12 meses pelas Expectativas Focus
3) Coleta e tratamentos dos dados do IPCA acumulado em 12 meses
4) Estimação da NAIRU pelo método de Ball e Mankiw usando a biblioteca `statsmodels`.
Resultados
Os parâmetros estimados da Curva de Phillips é verificado abaixo (usamos a diferença de 12 meses da taxa de desocupação como variável explicativa).
Para obter o código e o tutorial deste exercício faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvida
OLS Regression Results
==============================================================================
Dep. Variable: delta_ipca_exp R-squared: 0.024
Model: OLS Adj. R-squared: 0.017
Method: Least Squares F-statistic: 3.289
Date: Mon, 20 May 2024 Prob (F-statistic): 0.0720
Time: 11:44:20 Log-Likelihood: -281.58
No. Observations: 133 AIC: 567.2
Df Residuals: 131 BIC: 572.9
Df Model: 1
Covariance Type: nonrobust
===============================================================================
coef std err t P>|t| [0.025 0.975]
-------------------------------------------------------------------------------
Intercept 1.1699 0.176 6.660 0.000 0.822 1.517
pnad_diff12 -0.1586 0.087 -1.814 0.072 -0.332 0.014
==============================================================================
Omnibus: 15.441 Durbin-Watson: 0.059
Prob(Omnibus): 0.000 Jarque-Bera (JB): 13.873
Skew: 0.711 Prob(JB): 0.000972
Kurtosis: 2.307 Cond. No. 2.01
============================================================================== Para confirmar a relação de tradeoff, comparamos o Hiato do Desemprego (Taxa de desocupação - NAIRU) com a Taxa da Inflação contemporaneamente, o que permite compreender os momentos de relação inversa entre as duas variáveis:
Para confirmar a relação de tradeoff, comparamos o Hiato do Desemprego (Taxa de desocupação - NAIRU) com a Taxa da Inflação contemporaneamente, o que permite compreender os momentos de relação inversa entre as duas variáveis: 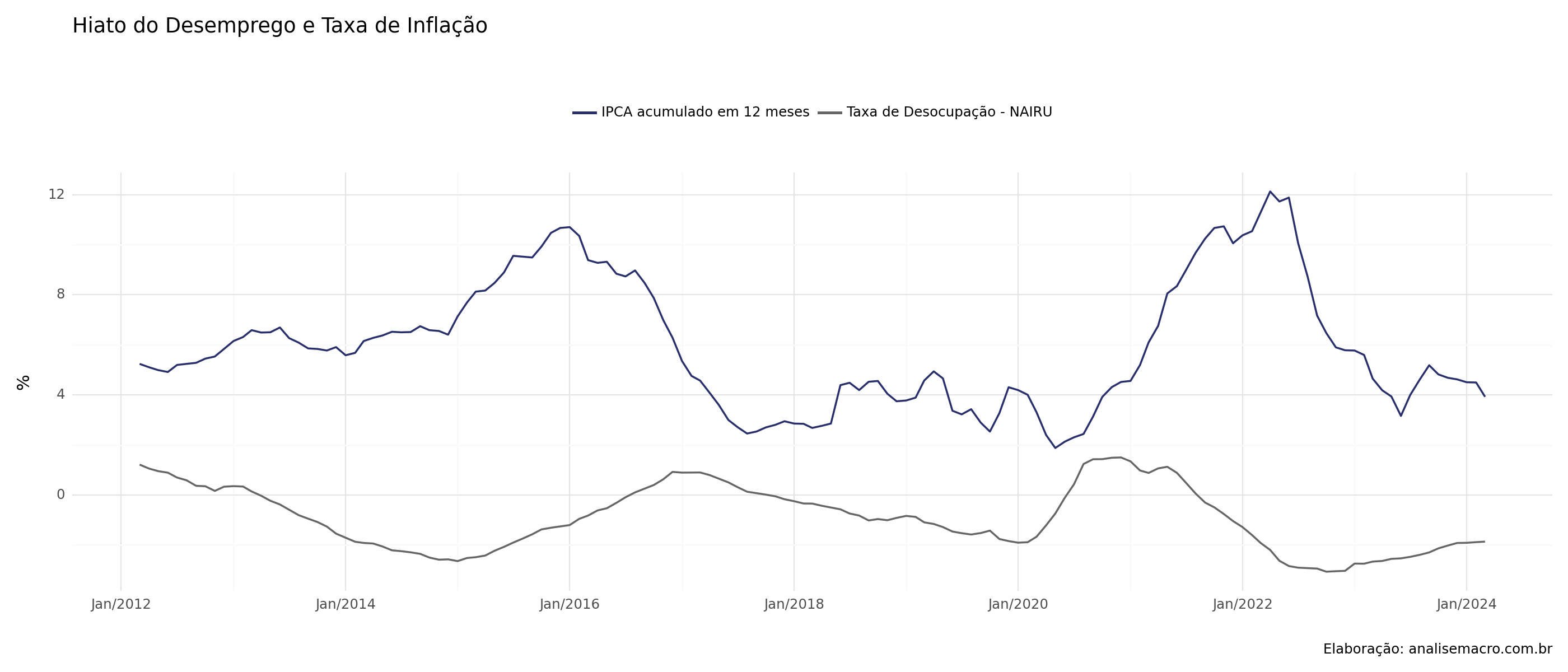
Quer aprender mais?
Clique aqui para fazer seu cadastro no Boletim AM e baixar o código que produziu este exercício, além de receber novos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas diretamente em seu e-mail.
Referências
Ball, Laurence, and N. Gregory Mankiw. "The NAIRU in theory and practice." Journal of economic Perspectives 16.4 (2002): 115-136.

