Dando continuidade ao nosso esforço de compreensão do organismo econômico brasileiro por meio de equações, adicionamos o Banco Central via a estimação de uma regra de Taylor. Realizaremos a construção do modelo por meio do Python, seguindo todos os passos de coleta e tratamento dos dados, finalizando com a construção do modelo via OLS.
A Regra de Taylor, também conhecida como Regra da Taxa de Juros de Taylor, é uma fórmula usada para prever a taxa de juros de um banco central com base em vários fatores econômicos. Portanto, é uma ferramenta muito importante para a tomada de decisões da autoridade monetária.
A Regra de Taylor produzida aqui toma forma com base na seguinte equação abaixo.
(1) 
Basicamente, a regra de Taylor a ser estimada relaciona a taxa básica de juros às suas próprias defasagens - de modo a incorporar a suavização da taxa de juros ao longo do tempo e, econometricamente, prevenir autocorrelação nos resíduos -, a diferença entre a inflação projetada e a meta de inflação e uma medida de hiato do produto.
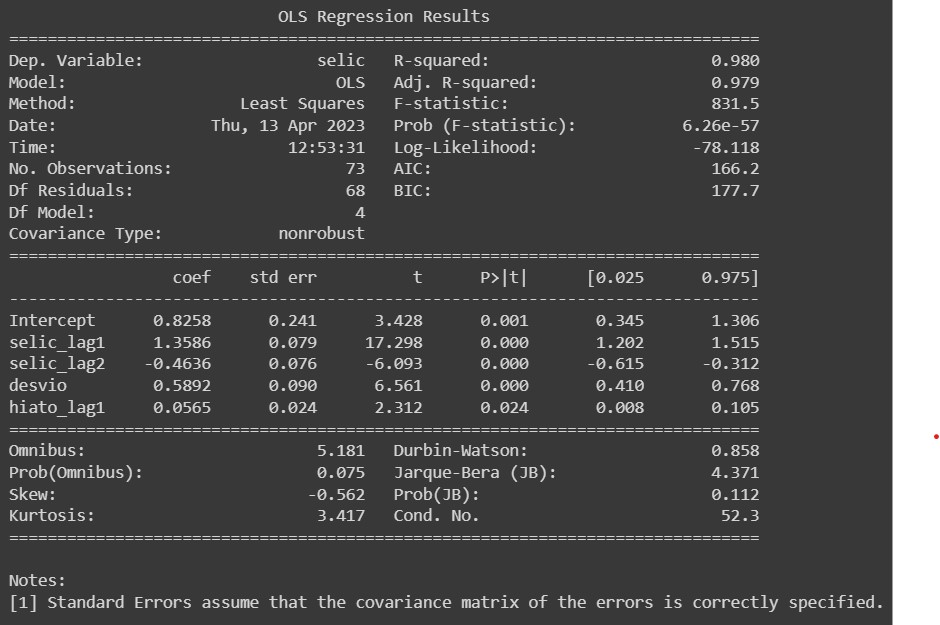
No Python, realizamos toda a tarefa de coleta e tratamento de dados e também a estimação do modelo via OLS, tornando todo o processo totalmente automatizado.
Para obter todo o código do processo de criação do modelo, faça parte do Clube AM, o repositório de códigos da Análise Macro, contendo exercícios semanais de R e Python.
Abaixo, temos o resultado do modelo, produzido pela função OLS do pacote statsmodels.
_____________________________________
Quer aprender mais?
Seja um aluno da nossa trilha de Macroeconomia Aplicada e aprenda a criar projetos voltados para a Macroeconomia.

