Ao longo das últimas semanas, tenho publicado diversos posts sobre a pandemia do coronavírus bem como o seu impacto sobre a economia brasileira a partir de indicadores antecedentes de nível de atividade. Uma boa proxy para o que vai ocorrer com a atividade nesse período, por suposto, está no consumo de energia elétrica. De forma a identificar esse efeito, produzimos a edição 73 do Clube do Código, que busca verificar a relação entre consumo de energia e crescimento econômico. Para isso, construímos diversos modelos e análises ao longo da respectiva edição com base tanto no nível quanto nas taxas de crescimento das séries.
Para fazer essa análise, primeiro podemos dar uma olhada na carga diária de energia, que é uma série temporal disponibilizada pelo Operador Nacional do Sistema Elétrico (ONS).
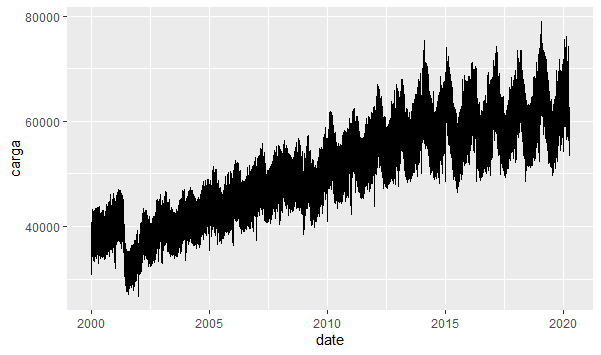
Com a série acima, não dá para fazer muita coisa, não é mesmo? Precisamos tratá-la. Primeiro, nós mensalizamos a série.
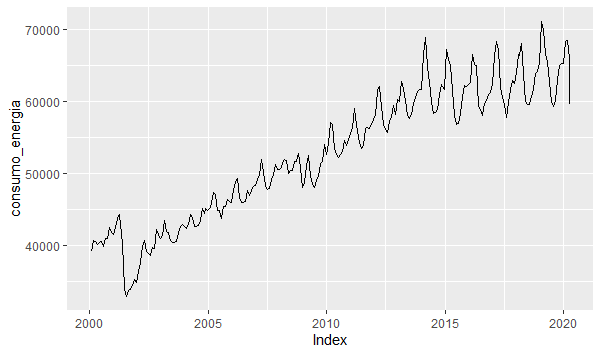
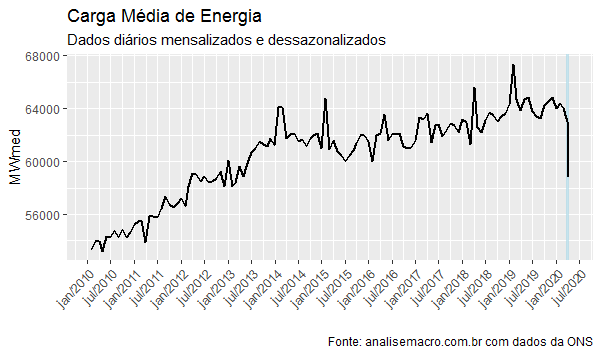
Na sequência, nós dessazonalizamos a série. O gráfico abaixo ilustrar o comportamento de um recorte da série, a partir de 2010. Com esse tratamento que fizemos, é possível observar uma queda significativa no consumo de energia no mês de março e nos primeiros dias de abril.
O gráfico a seguir ilustra a variação interanual, isto é, o mês t contra o mês t-12. Os primeiros dias de abril sugerem uma queda próxima a 9% no consumo de energia.
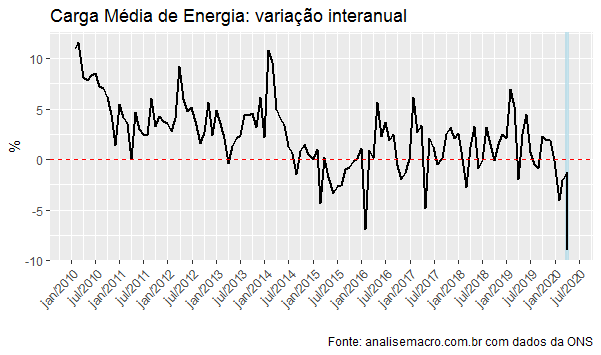
Identificamos assim que, de fato, houve um impacto significativo sobre o consumo de energia, como era esperado, dado o fechamento de estabelecimentos comerciais em quase todo o país. Uma vez feito isso, precisamos agora relacionar o consumo de energia com o PIB. Para isso, contudo, precisamos ao invés de mensalizar o consumo de energia, trimestralizá-lo, de forma a torná-lo comparável ao PIB. O gráfico a seguir ilustra o PIB com ajuste sazonal e o consumo de energia trimestralizado, bem como as variações anualizadas. A série do PIB está disponível no SIDRA/IBGE.
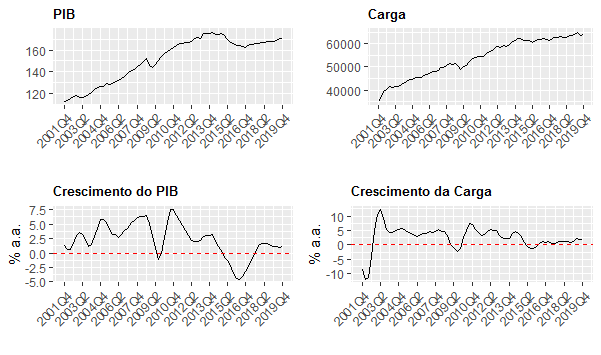 Um ponto importante aqui é que a despeito das mesmas não serem estacionárias, elas possuem uma relação de longo prazo. Em termos econométricos, dizemos que as mesmas são cointegradas.
Um ponto importante aqui é que a despeito das mesmas não serem estacionárias, elas possuem uma relação de longo prazo. Em termos econométricos, dizemos que as mesmas são cointegradas.
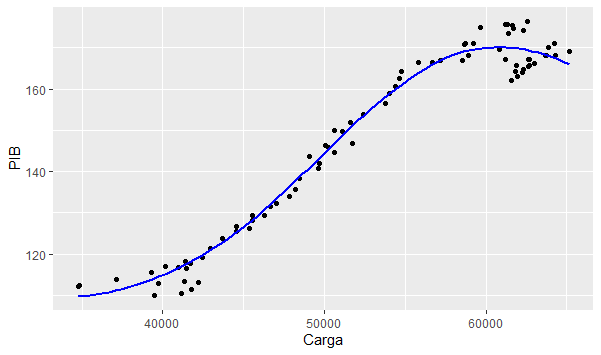 Uma vez tratadas as nossas séries, nós agora precisamos verificar o sentido da causalidade entre as séries. Ao aplicarmos o procedimento de Toda-Yamamoto, os resultados encontrados sugerem que há uma causalidade no sentido do PIB para a carga de energia. Estabelecido o sentido da causalidade, nós podemos criar o nosso modelo log-log, de modo a estimar a elasticidade entre as séries. Ao estimarmos nosso modelo, chegamos a uma elasticidade de 1,1, em linha com exercícios similares.
Uma vez tratadas as nossas séries, nós agora precisamos verificar o sentido da causalidade entre as séries. Ao aplicarmos o procedimento de Toda-Yamamoto, os resultados encontrados sugerem que há uma causalidade no sentido do PIB para a carga de energia. Estabelecido o sentido da causalidade, nós podemos criar o nosso modelo log-log, de modo a estimar a elasticidade entre as séries. Ao estimarmos nosso modelo, chegamos a uma elasticidade de 1,1, em linha com exercícios similares.
Dada uma elasticidade próxima de 1, podemos esperar um grande estrago sobre o nível de atividade, dados os primeiros números relacionados ao consumo de energia de meados de março para cá.
________________________
Lee, C.C., 2005, Energy Consumption and GDP in Developing Countries: A Cointegrated Panel Analysis, Energy Economics, 27, 415-427.
Toda H.Y.; Yamamoto T. (1995). Statistical inference in vector autoregressions with possibly integrated processes. Journal of Econometrics, 66, 225–250.
(*) Aprenda a produzir exercícios como esse em nossos Cursos Aplicados de R.
(**) Os códigos estarão disponíveis amanhã na Edição 73 do Clube do Código.

