Introdução
A relação entre o nível de atividade econômica e o mercado de trabalho é um dos pilares da macroeconomia. Tradicionalmente, essa dinâmica é analisada sob a ótica da Curva de Phillips (relação entre desemprego e inflação) ou da Lei de Okun (relação entre desemprego e produto). Um conceito central nessa discussão é a NAIRU (Non-Accelerating Inflation Rate of Unemployment), que representa a taxa de desemprego de equilíbrio, ou seja, a taxa compatível com uma inflação estável e com a economia operando em seu potencial (hiato do produto nulo).
Este exercício utiliza a linguagem Python para investigar essa relação na economia brasileira. O objetivo é construir um pipeline de dados que permita estimar a NAIRU implícita através da correlação histórica entre o Hiato do Produto (estimado pelo Banco Central) e a Taxa de Desemprego. O estudo demonstra como ferramentas computacionais modernas permitem superar desafios de compatibilidade de dados, realizar ajustes sazonais complexos e modelar parâmetros estruturais da economia.
Objetivo
O objetivo central deste trabalho é estimar a taxa de desemprego de equilíbrio (NAIRU) para o Brasil, utilizando dados trimestrais de 2003 a 2025. Para isso, o exercício busca:
- Automatizar a coleta do Hiato do Produto oficial do Banco Central.
- Construir uma série histórica longa e consistente de desemprego, unificando metodologias distintas (PME e PNAD Contínua).
- Modelar econometricamente a relação entre a ociosidade da economia e o mercado de trabalho.
Quer ver a vídeoaula do tutorial deste exercício? E receber o código que o produziu? Faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
Metodologia e Dados
A execução deste estudo evidencia a capacidade do Python em integrar diferentes fontes e metodologias estatísticas. O processo foi dividido em três etapas principais:
1. Coleta e Tratamento do Hiato do Produto
A variável de referência para o ciclo econômico é o Hiato do Produto estimado pelo Banco Central do Brasil (BCB). Através da biblioteca pandas, o código acessa diretamente a planilha de dados do Relatório de Inflação disponível no site do BCB, extrai a série do "Cenário de Referência" e a converte para uma frequência trimestral estruturada. O Hiato mede a diferença percentual entre o PIB efetivo e o PIB potencial; valores negativos indicam ociosidade, enquanto valores positivos indicam superaquecimento.
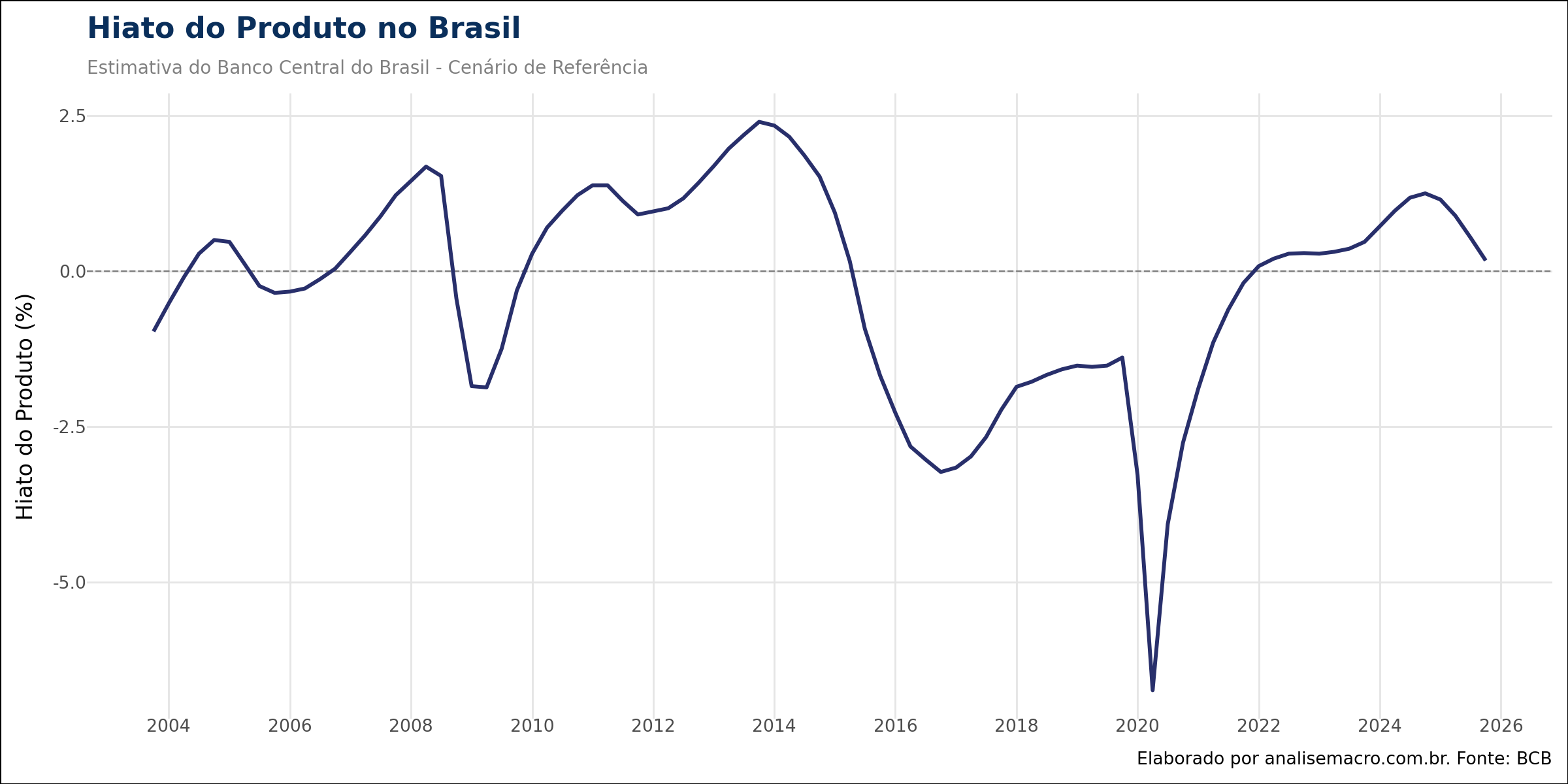
2. Construção da Série Longa de Desemprego (Retropolação)
Um desafio comum na análise de dados brasileiros é a mudança metodológica nas pesquisas de emprego. A série atual (PNAD Contínua) inicia-se apenas em 2012, o que é insuficiente para capturar ciclos econômicos completos. Para contornar isso, utilizamos a antiga Pesquisa Mensal de Emprego (PME) para o período anterior.
O Python permitiu aplicar uma técnica de retropolação econométrica: estimou-se uma regressão linear simples entre a PNAD e a PME no período em que ambas coexistiram. Os coeficientes obtidos foram utilizados para "prever" qual seria a taxa da PNAD nos anos anteriores a 2012, criando uma série sintética e harmonizada desde 2002.
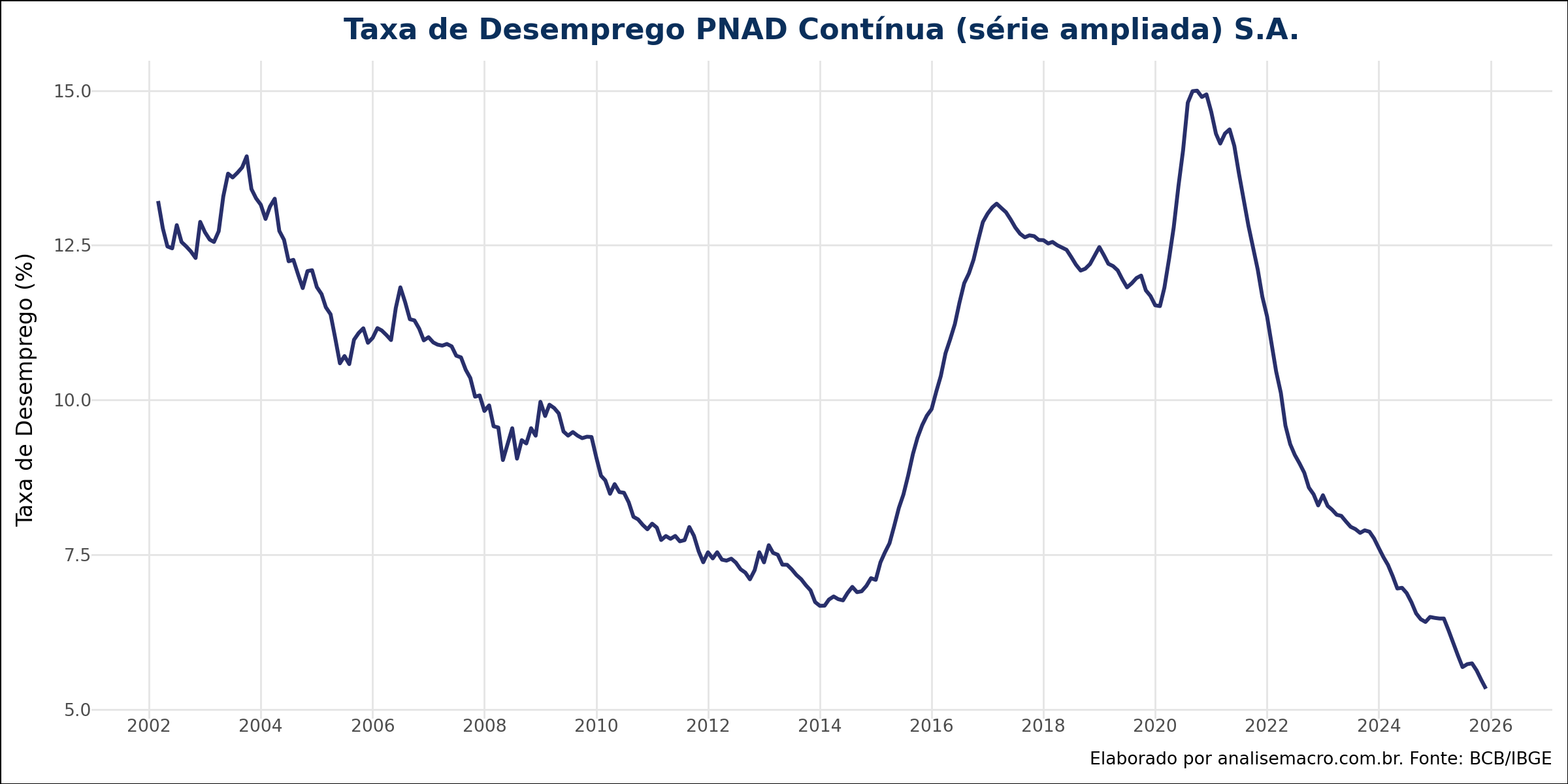
3. Ajuste Sazonal (X-13ARIMA-SEATS)
Como o Hiato do Produto é uma variável livre de efeitos sazonais, a taxa de desemprego também precisa sê-lo para evitar correlações espúrias. Utilizou-se a biblioteca statsmodels para integrar o algoritmo X-13ARIMA-SEATS (do Census Bureau dos EUA) diretamente no fluxo do Python, removendo a sazonalidade da série unificada de desemprego.
Resultados
A análise visual e econométrica dos dados processados revela a forte ciclicidade do mercado de trabalho brasileiro.
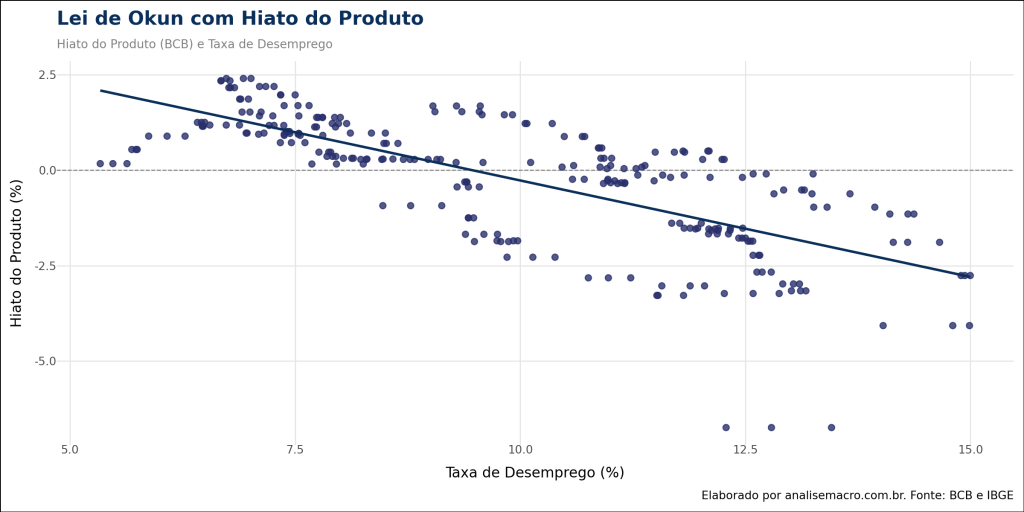
Regressão Linear e a NAIRU
Para formalizar essa relação, estimou-se um modelo de Mínimos Quadrados Ordinários (OLS) relacionando o Hiato do Produto (variável dependente) à Taxa de Desemprego (variável explicativa). A equação estimada foi:
![\[Hiato_t = \alpha + \beta \cdot Desemprego_t + \varepsilon_t\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-a6106fefe07d257b0fd327ac6ead1652_l3.png "Rendered by QuickLaTeX.com")
OLS Regression Results
==============================================================================
Dep. Variable: BCB R-squared: 0.531
Model: OLS Adj. R-squared: 0.529
Method: Least Squares F-statistic: 299.9
Date: Fri, 20 Feb 2026 Prob (F-statistic): 1.87e-45
Time: 04:53:18 Log-Likelihood: -413.88
No. Observations: 267 AIC: 831.8
Df Residuals: 265 BIC: 838.9
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 4.7794 0.297 16.100 0.000 4.195 5.364
u -0.5050 0.029 -17.317 0.000 -0.562 -0.448
==============================================================================
Omnibus: 60.642 Durbin-Watson: 0.118
Prob(Omnibus): 0.000 Jarque-Bera (JB): 137.499
Skew: -1.088 Prob(JB): 1.39e-30
Kurtosis: 5.761 Cond. No. 43.5
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
Os resultados da regressão indicam um coeficiente β de -0.5050, estatisticamente significativo. Isso sugere que, para cada ponto percentual de aumento no desemprego, o hiato do produto tende a cair cerca de 0,5 ponto percentual, confirmando a Lei de Okun para o Brasil. O R2 de 0.53 indica que o desemprego explica mais da metade da variância do ciclo econômico no período.
Cálculo da NAIRU Implícita A NAIRU é definida, neste contexto, como a taxa de desemprego que prevalece quando a economia está em equilíbrio (Hiato = 0). Matematicamente, isolamos o desemprego na equação de regressão assumindo Hiato zero:
![\[0 = 4.7794 - 0.5050 \cdot NAIRU \Rightarrow NAIRU = \frac{4.7794}{0.5050} \approx 9.46\%\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-c614ebe99370b9162a771ce9346a29e8_l3.png "Rendered by QuickLaTeX.com")
O gráfico de dispersão final ilustra essa relação, com a linha de regressão cruzando o eixo horizontal (onde o Hiato é zero) exatamente no ponto da NAIRU estimada.
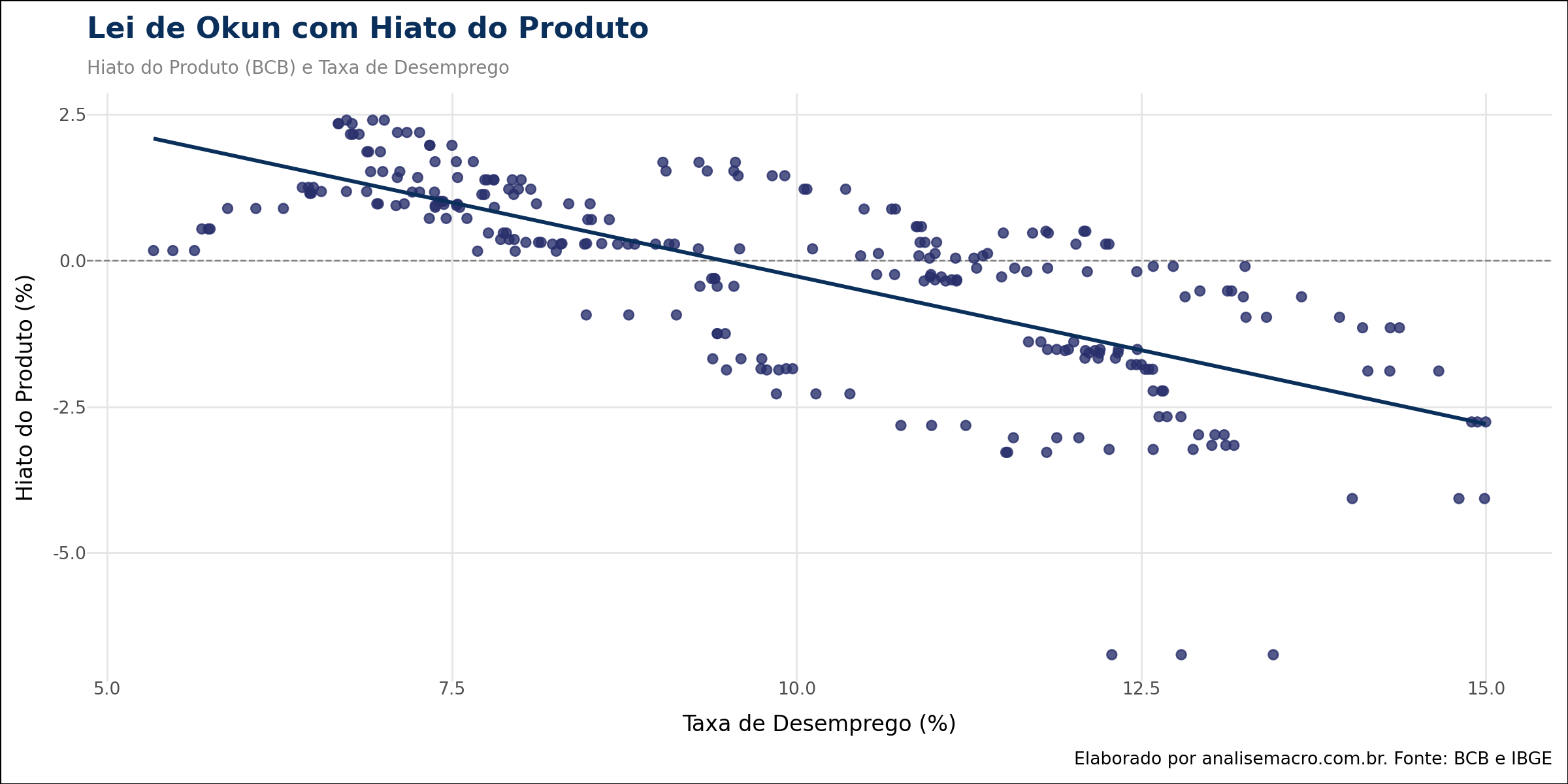
Conclusão
Este exercício demonstra como o Python pode ser utilizado para derivar parâmetros estruturais da economia a partir de dados brutos. A estimativa de uma NAIRU implícita de aproximadamente 9,46% sugere que o mercado de trabalho brasileiro possui rigidezes estruturais significativas; taxas de desemprego abaixo desse patamar tendem a gerar pressões inflacionárias via aquecimento da demanda (hiato positivo).
Além do resultado econômico, o trabalho destaca a eficiência do ciclo de dados em Python. A capacidade de automatizar a coleta de dados do BCB, harmonizar séries históricas distintas via modelagem e aplicar ajustes sazonais robustos em um único ambiente de programação oferece aos economistas uma ferramenta poderosa para o monitoramento de conjuntura e a formulação de cenários.

